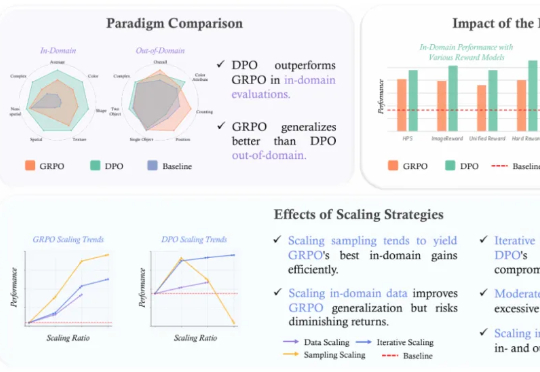
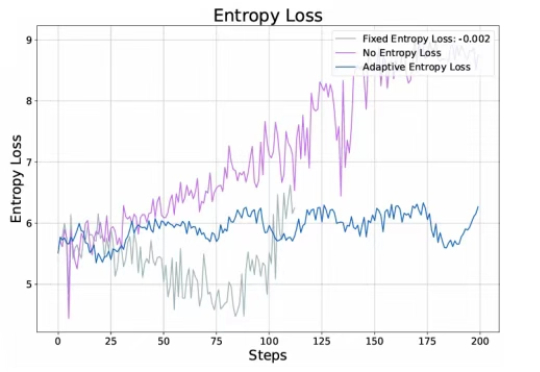
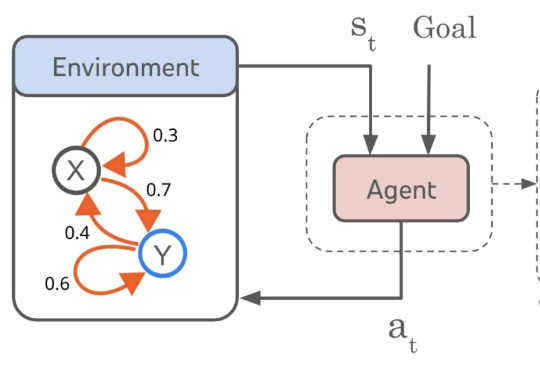
合成数据>人工数据,绝对性能暴涨超10个点!仅需任务定义,高效微调大模型
合成数据>人工数据,绝对性能暴涨超10个点!仅需任务定义,高效微调大模型基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。
来自主题: AI技术研报
9956 点击 2025-06-24 16:13