大模型第一股热闹正酣,“局外人”阶跃星辰发了一个小更新
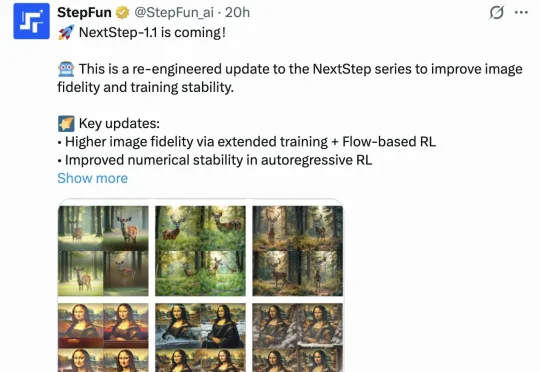
大模型第一股热闹正酣,“局外人”阶跃星辰发了一个小更新直到刚刚,用最新的图像模型NextStep-1.1,扳回一球。总体来看,这次开源的NextStep-1.1解决了之前NextStep-1中出现的可视化失败(visualization failures )问题。其通过扩展训练和基于流的强化学习(RL)后训练范式,大幅提升了图像质量。
来自主题: AI资讯
9823 点击 2025-12-28 09:57
 搜索
搜索
直到刚刚,用最新的图像模型NextStep-1.1,扳回一球。总体来看,这次开源的NextStep-1.1解决了之前NextStep-1中出现的可视化失败(visualization failures )问题。其通过扩展训练和基于流的强化学习(RL)后训练范式,大幅提升了图像质量。
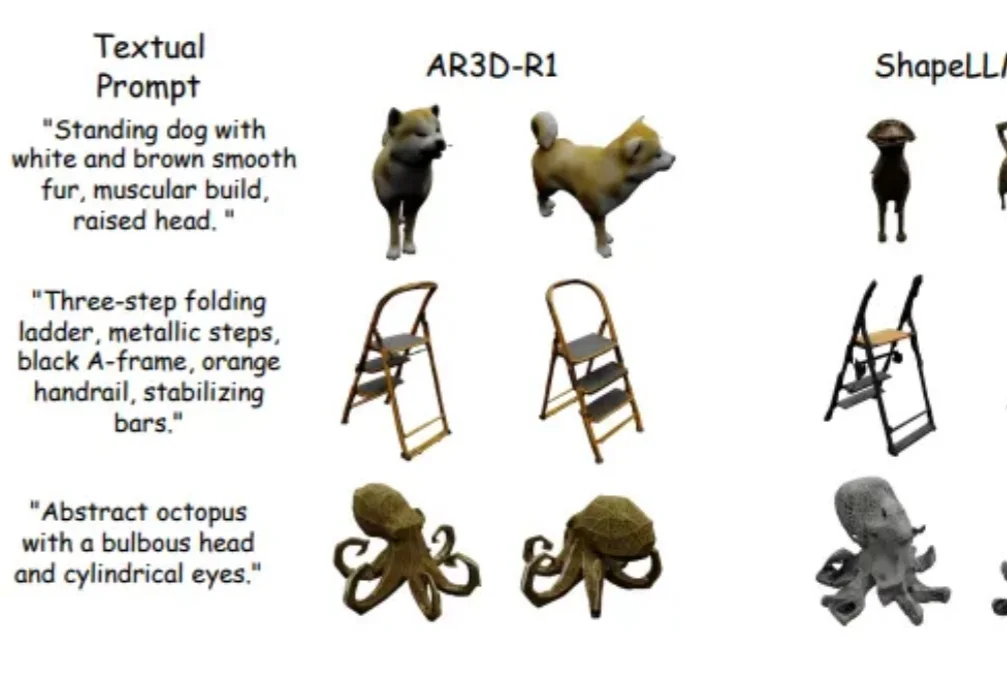
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
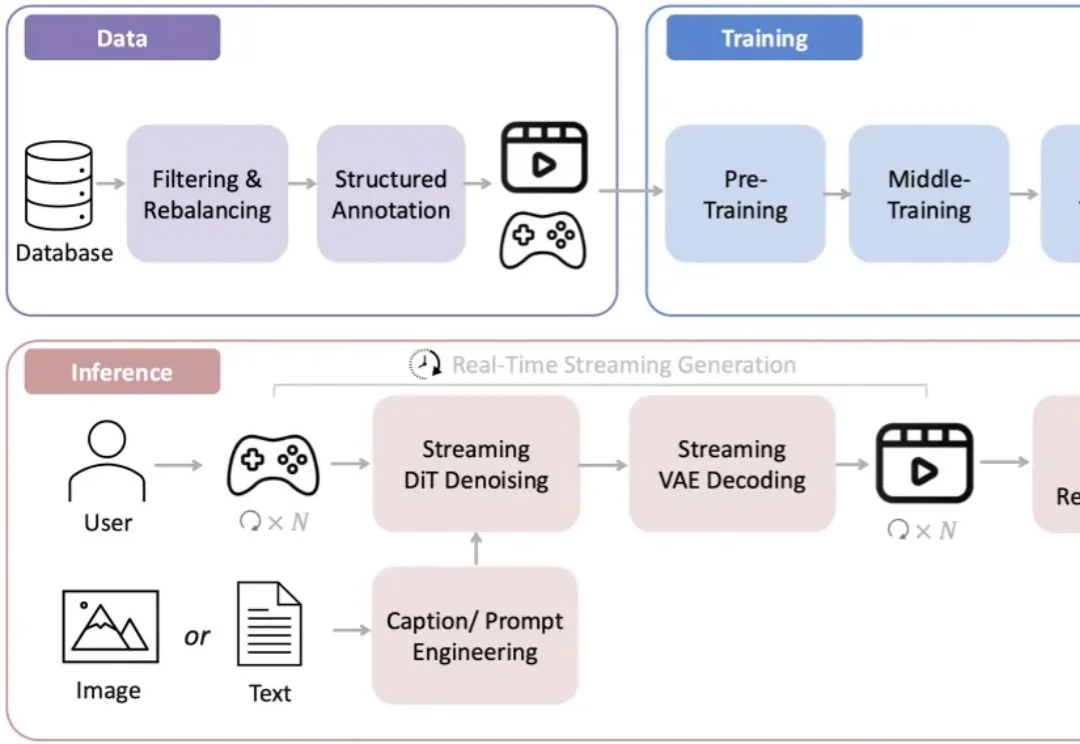
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。
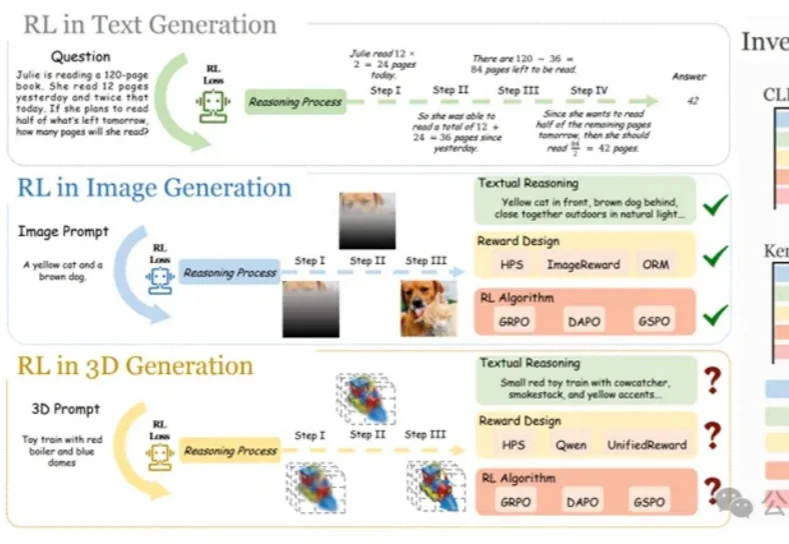
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。
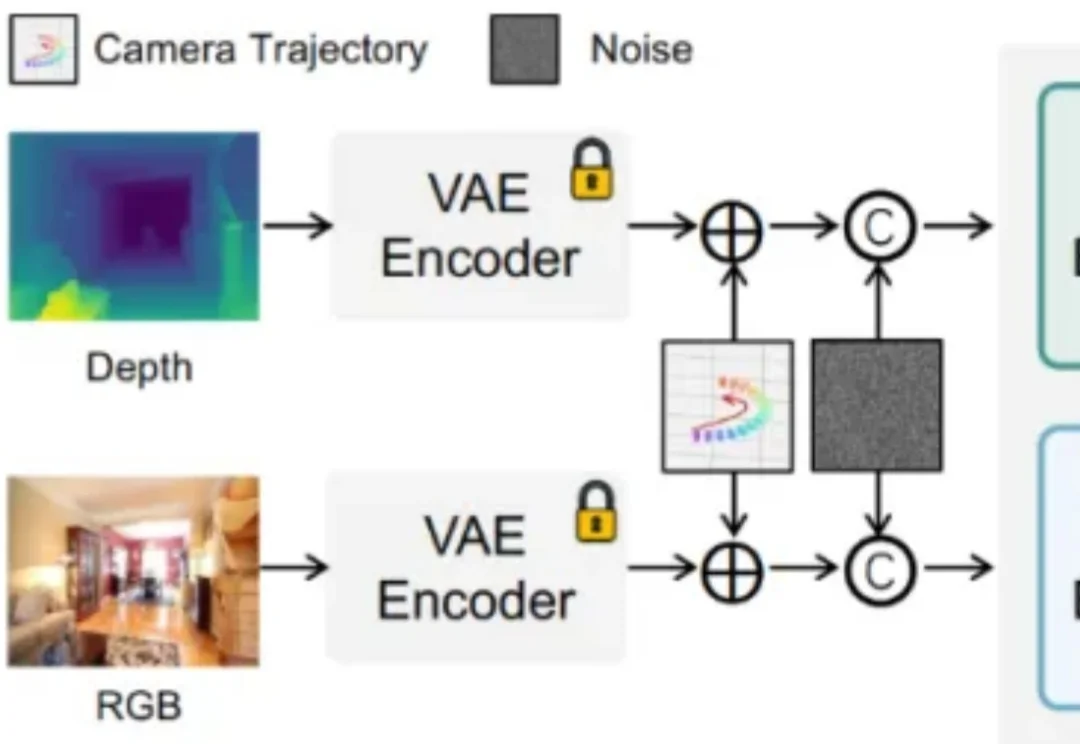
你的生成模型真的「懂几何」吗?还是只是在假装对齐相机轨迹?

现有视频生成模型往往难以兼顾「运镜」与「摄影美学」的精确控制。为此,华中科技大学、南洋理工大学、商汤科技和上海人工智能实验室团队推出了 CineCtrl。作为首个统一的视频摄影控制 V2V 框架,CineCtrl 通过解耦交叉注意力机制,摆脱了多控制信号共同控制的效果耦合问题,实现了对视频相机外参轨迹与摄影效果的独立、精细、协调控制。
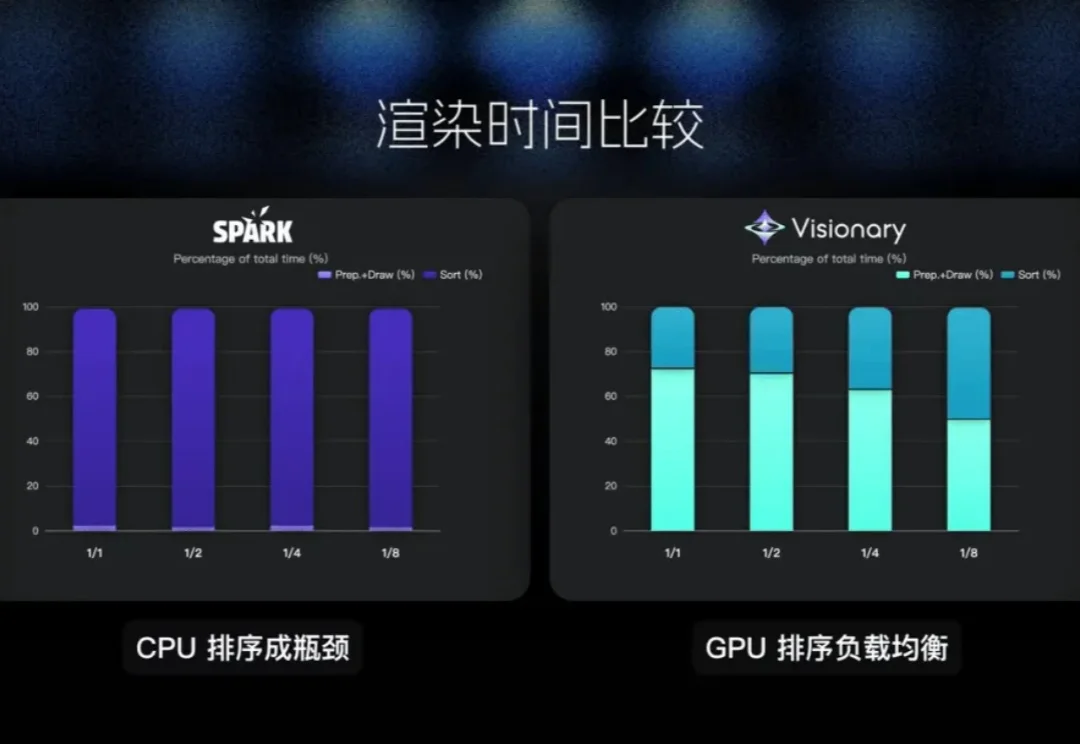
可支持24帧/秒的长时流式生成。
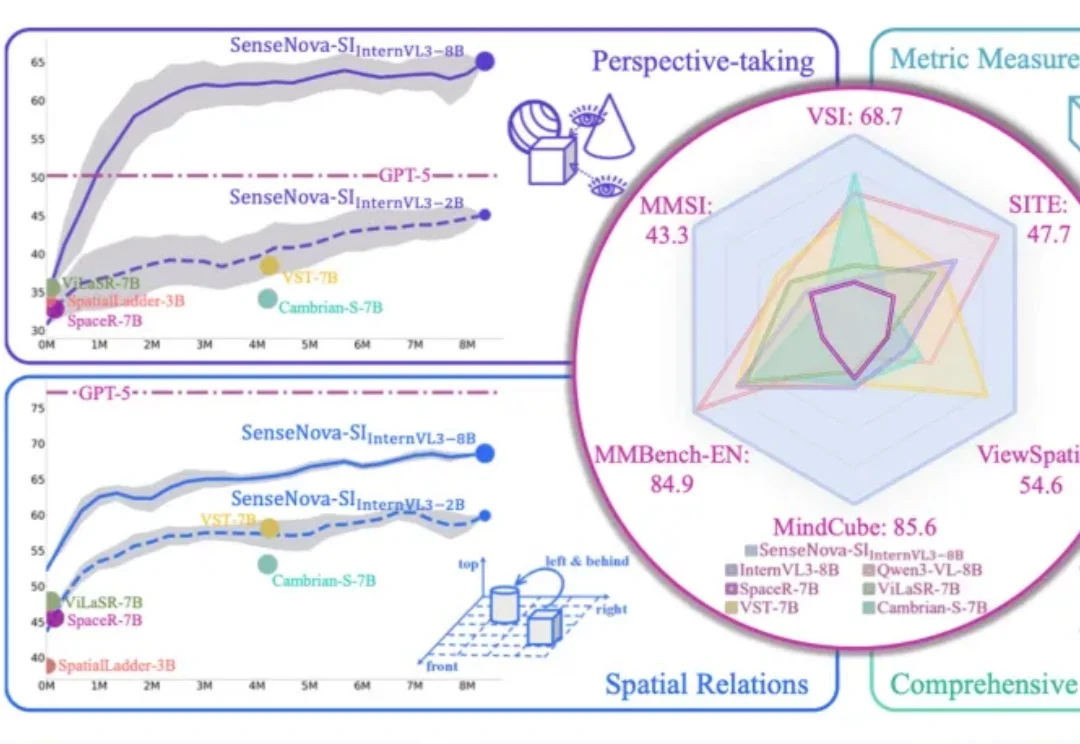
李飞飞团队最新的空间智能模型Cambrian-S,首次被一个国产开源AI超越了。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。