
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
来自主题: AI资讯
11150 点击 2026-02-11 10:47
 搜索
搜索
谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!

系统性能优化领域顶级专家Brendan Gregg,正式官宣加入OpenAI。

Aishwarya Naresh Reganti 和 Kiriti Badam 曾在 OpenAI、Google、Amazon、Databricks 等公司参与构建并成功推出了 50 多个企业级 AI 产品。最近,他们在播客节目中,与主持人 Lenny 细致分享了当前 AI 产品开发中的常见陷阱与成功路径。基于该播客视频,InfoQ 进行了部分删改。
近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。
大家都知道 Elon Musk 最近和 OpenAI 在硅谷法庭上,「打得火热」,算是「一团和气」。前两天,OpenAI 的总裁 Greg Brockman 终于坐不住了。他直接发推 Diss Elon Musk,指责他为了打官司,竟然断章取义地把自己私人日记里的片段当成证据 😆。
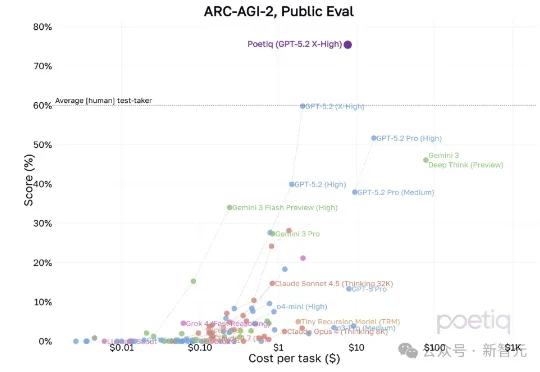
刚刚,GPT-5.2刷新了一项新纪录!OpenAI联合创始人Greg Brockman发帖称使用GPT-5.2在ARC-AGI-2基准测试上,表现超过了人类基线水平。

AI Coding火到不用多说,但怎么用才最高效呢?这份连大神卡帕西和OpenAI总裁Greg Brockman都在转发推荐的Coding Agents指南,用3招教你快速交付。大神们在转,网友也在夸

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。