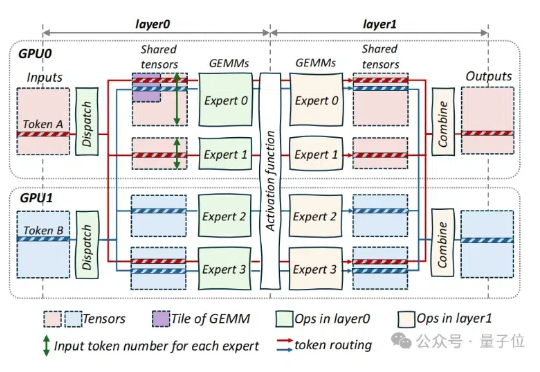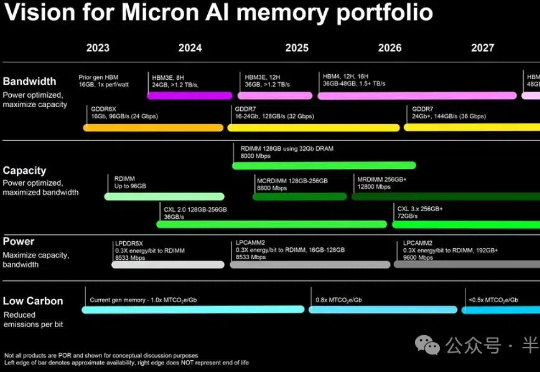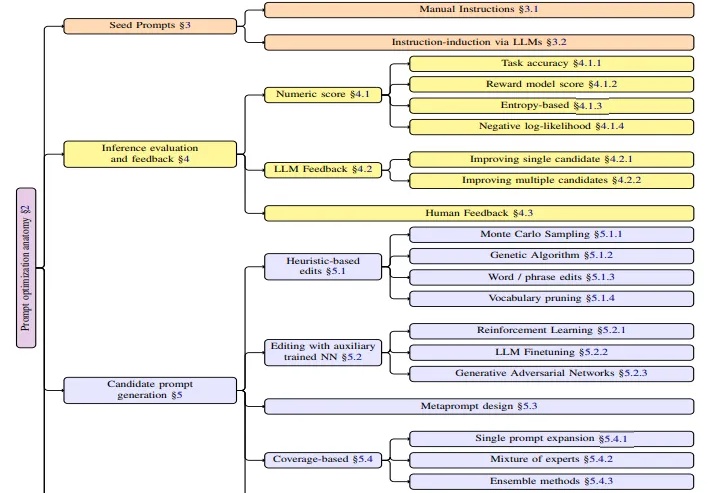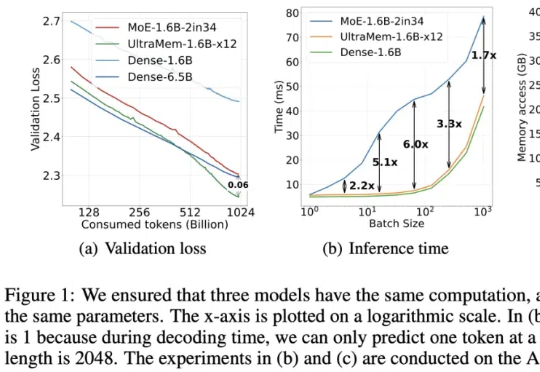
3700次预训练总结超参规律,开源海量实验,告别盲猜
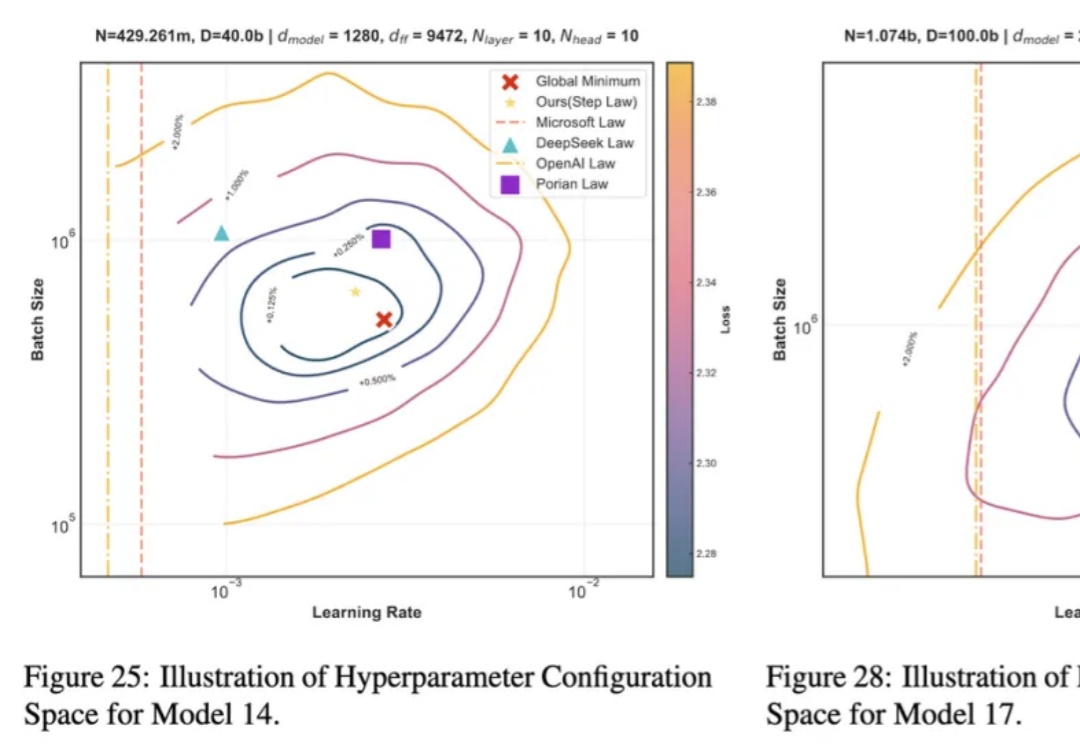
3700次预训练总结超参规律,开源海量实验,告别盲猜近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
来自主题: AI技术研报
10430 点击 2025-03-13 15:15