

对谈闵可锐、方汉和吴翼:DeepSeek-R1 之后,AI 应用更好做了吗?
对谈闵可锐、方汉和吴翼:DeepSeek-R1 之后,AI 应用更好做了吗?应用内接入 DeepSeek-R1 已经成了一种潮流。
来自主题: AI资讯
10742 点击 2025-02-18 10:50
应用内接入 DeepSeek-R1 已经成了一种潮流。
接入DeepSeek,不等于All in DeepSeek
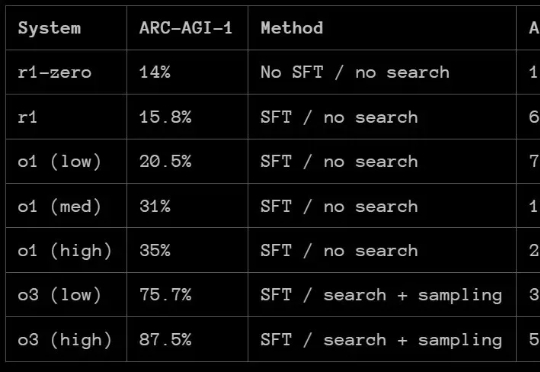
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。
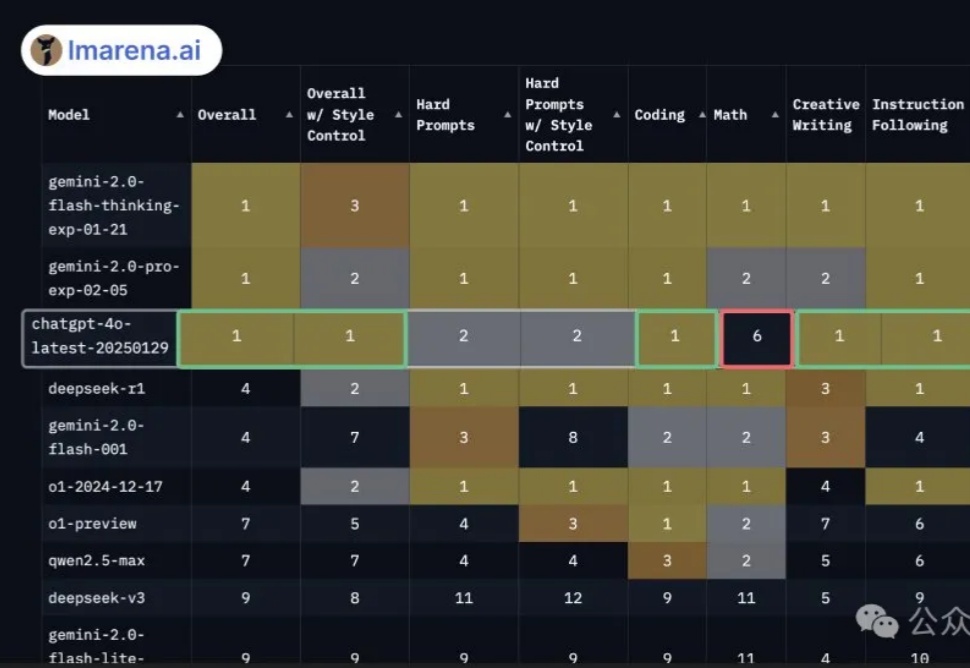
GPT-4o悄悄更新版本,在大模型竞技场超越DeepSeek-R1登上并列第一。

广东打响了第一枪。深圳龙岗区的政务系统悄悄上线了DeepSeek-R1全尺寸模型,群众办事时面对的不再是机械的问答机器人,而是一个能理解“我想办落户,但社保断了3个月怎么办”这类复杂问题的AI公务员。东莞紧随其后,把DeepSeek塞进了人工智能大模型中心,号称要让“企业办证速度跑赢奶茶外卖”。更狠的是广州,直接祭出DeepSeek-R1和V3 671B双模型组合

知乎直答默默掏出了自己的“底牌”。为啥这么说呢?因为知乎不仅有自己的AI模型,还攒了十多年的中文高质量知识库,再加上真实的问答场景作为AI的“实战训练场”,简直就是AI界的“学霸”。有了DeepSeek-R1的加持,知乎直答的推理能力直接拉满,传统搜索看了直呼“内行”,妥妥成了AI时代的“搜索界天花板”。
本文的作用是帮你把问题具体化,这是用好DeepSeek-R1等推理型模型的前置步骤。

“张小龙觉得对这个功能自己最满意的地方之一,就是一经发布几乎没有改进余地而稳定运行了十年。”极客公园创始人张鹏在与张小龙对话后,这样总结微信的产品逻辑。这一点在微信成为真正意义上的“国民社交App”之后,也没有发生改变。

一觉醒来,AI应用的天变了!而且据腾讯回应消息,接入的还是满血版 DeepSeek R1!微信正在灰度测试该模型,部分灰度到的用户可以内测相关的 AI 搜索功能。

AI搜索“老大哥”Perplexity,刚刚也推出了自家的Deep Research——随便给个话题,就能生成有深度的研究报告。