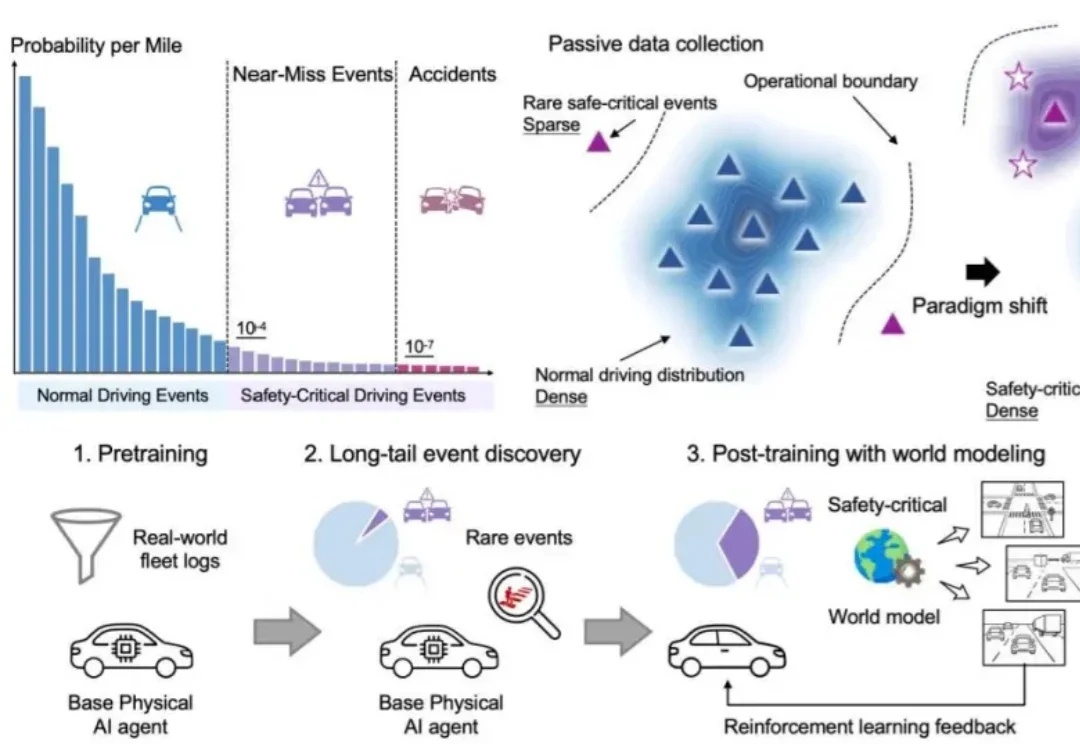
世界引擎:Post-Training开启Physical AGI新纪元
世界引擎:Post-Training开启Physical AGI新纪元一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
来自主题: AI技术研报
6715 点击 2026-04-20 09:00
 搜索
搜索
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,

DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。
爱诗科技近期完成了 3 亿美元 C 轮融资,由鼎晖投资领投,超过 20 家机构参与,包括中国儒意、三七互娱等文娱行业产业方,亦庄国投、苏创投等地方国资,和 UOB Venture Management、 Lion X 基金等海外机构。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
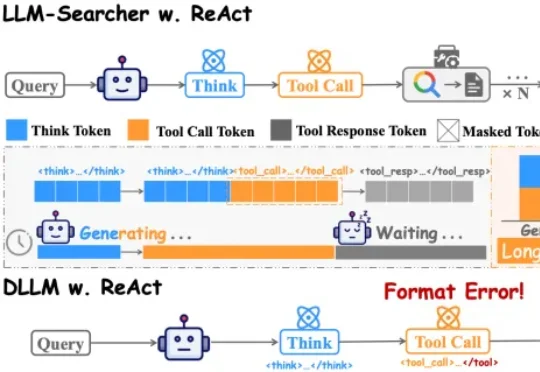
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:

李国杰院士指出,AI安全风险应按逻辑复杂性分为三类:R1可验证、R2可发现但不可证明安全、R3不可治理。当前AI多属R2,关键不在「证明安全」,而在构建人类主导的制度性刹车机制,拒绝让渡终极控制权。