
来一手Qwen-Image-2.0实测,好像还不错?!
来一手Qwen-Image-2.0实测,好像还不错?!BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0
来自主题: AI产品测评
11206 点击 2026-02-11 12:43
 搜索
搜索
BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0

今天,阿里巴巴发布了新一代图像生成基础模型Qwen-Image 2.0,这一模型支持长达一千个token的超长指令、2k分辨率,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 2.0的20B,带来更快的推理速度。
个人电脑也能跑出顶级编程智能体?今日凌晨,阿里开源了一款小型混合专家模型Qwen3-Coder-Next,专为编程智能体(Agent)和本地开发打造。该模型总参数80B,激活参数仅3B,在权威基准SWE-Bench Verified上实现了超70%的问题解决率,性能媲美激活参数规模大10-20倍的稠密模型。

AI生成一张图片,你愿意等多久?在主流扩散模型还在迭代中反复“磨叽”、让用户盯着进度条发呆时,阿里智能引擎团队直接把进度条“拉爆”了——5秒钟,到手4张2K级高清大图。

这个春节,中国 AI 迎来「决战时刻」。据《The Information》援引内部消息人士透露:字节或将祭出全模态三件套;阿里除了或将发布强大的全新旗舰模型 Qwen 3.5 外,也会让千问打通支付与电商,挑战豆包;DeepSeek V4 或将携最强代码能力突袭。这不仅是技术竞赛,更是对 14 亿用户生活入口与未来互联网秩序的终极争夺。
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。

今天受邀,参加了一个非常有趣的活动,现场人真的爆满了,很多人都是从外地特意赶过来的。 这个活动,叫AGI-NEXT。 主要是几个演讲的嘉宾,过于重磅了。 开源四巨头除了DeepSeek没来,智谱的唐杰老师、Kimi的杨植麟、Qwen的林俊旸,齐聚一堂。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
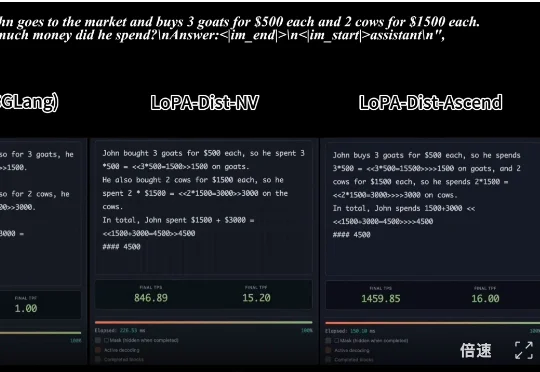
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台