从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践
从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
来自主题: AI技术研报
8180 点击 2025-08-22 16:35
 搜索
搜索
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
庸笔下的乔峰,在聚贤庄单挑群雄时,用一套人人会使的「太祖长拳」,打出了震慑全场的必杀效果。这门功夫看似平平无奇,却因使用者内力深厚、大巧不工,而威力无穷。
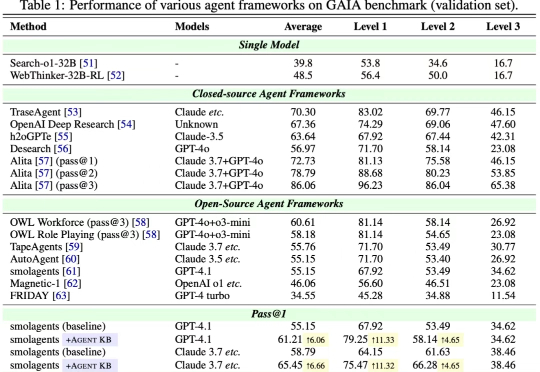
近日,来自 OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了 Agent KB 框架。这项工作通过构建一个经验池并且通过两阶段的检索机制实现了 AI Agent 之间的有效经验共享。Agent KB 通过层级化的经验检索,让智能体能够从其他任务的成功经验中学习,显著提升了复杂推理和问题解决能力。
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。

Redis 最近推出向量集合(Vector Set) 功能,这是一种专为向量相似性设计的数据类型,也是 Redis 针对人工智能应用的一个新的选项。这是 Redis 创始人 Salvatore Sanfilippo(“antirez”)自 重新加入 公司以来的第一个重大贡献。
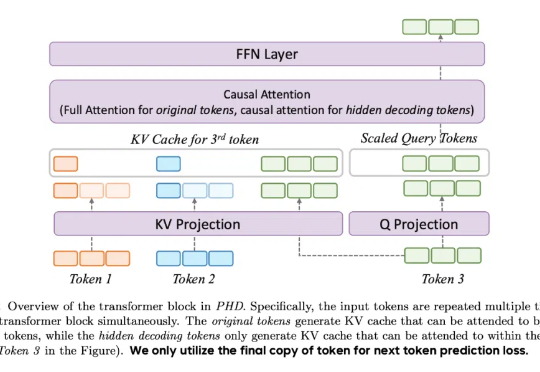
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
一切为了「多终端一致体验」和「用户数据闭环」。
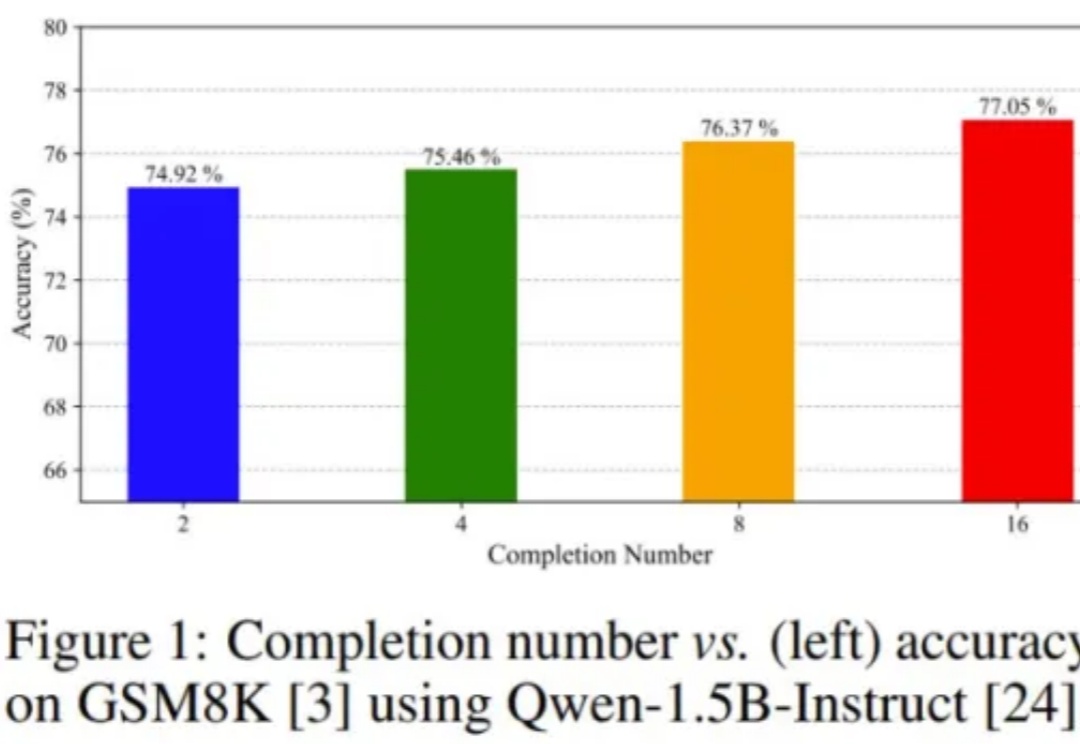
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。