
在OpenAI炼Agent一年半,回国做出首个开源Agent训练框架!这个30岁清华天才却说:创业不是技术命
在OpenAI炼Agent一年半,回国做出首个开源Agent训练框架!这个30岁清华天才却说:创业不是技术命姚班、伯克利、OpenAI、清华……年仅 30 多岁的吴翼身上已经聚集了众多亮眼的标签。
来自主题: AI资讯
8841 点击 2025-08-24 13:43
 搜索
搜索
姚班、伯克利、OpenAI、清华……年仅 30 多岁的吴翼身上已经聚集了众多亮眼的标签。

当OpenAI的CEO Sam Altman说出"未来几年将出现第一家由一个人创立的十亿美元公司"时,整个硅谷都震惊了。这听起来像天方夜谭,但仔细想想,这个预言可能正在成为现实。传统的创业模式——从想法到融资到招聘到产品开发——正在被一种全新的范式所颠覆。
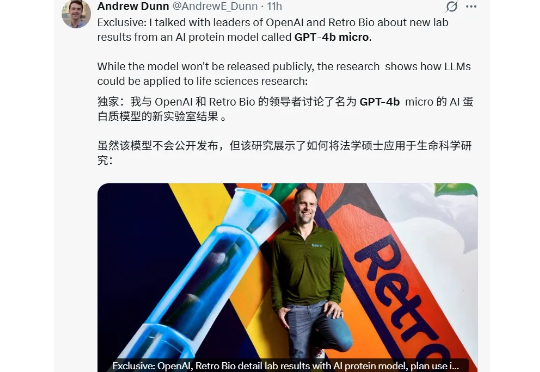
就在刚刚过去的一天,OpenAI 宣布他们与生物科技初创公司 Retro Bio 合作,研发的新模型 GPT-4b micro,设计出了新型且显著增强的山中因子变体。

万万没想到,当年为了𝕏扬言要找小扎线下打架的马斯克,如今竟回头拉拢人家合作了。 并且一开口,就是近千亿美金的超级大生意。

GPT-4o蛋白质专用版,已成功改进诺贝尔奖获奖蛋白的变体。 科学家利用GPT‑4b micro成功设计了新型且显著增强的山中伸弥因子变体,将干细胞重编程标记物的表达量提升了50倍。

刚刚,OpenAI 重大的权力结构调整曝光。 The Verge 报道称,OpenAI CEO Sam Altman 将把公司的大部分日常运营,交给 5 月任命的应用业务 CEO Fidji Simo。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
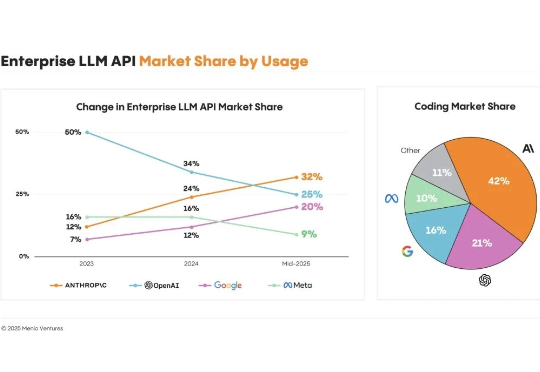
Anthropic的“快乐教育”让OpenAI份额暴跌25% 6个月自学速成AI,我成为了LLM天才❛‿˂̵✧ 成就OpenAI、打倒OpenAI(咳咳)创立对家Anthropic,从此化身前司的心腹大患……
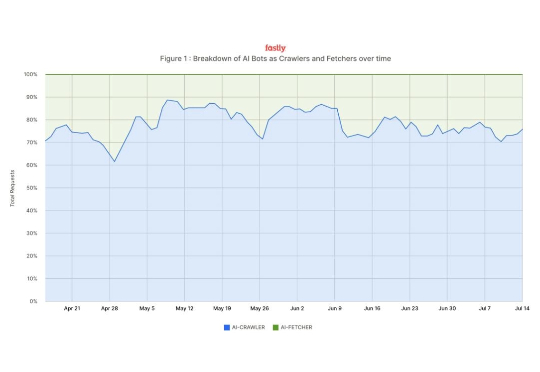
“我的网站被爬崩了,自己要付流量费,人家却用我的内容训练出 AI 模型,还赚足了眼球。” 自从 AI 机器人开始流行,很多网站开发者叫苦不堪。而近日,云服务巨头 Fastly 发布的一份报告让人看完直呼“现实往往我们仅听到的部分更为残酷。”

OpenAI的GPT-5因大幅降低AI幻觉而被批"变蠢",输出呆板创造力减弱,反映出幻觉降低限制模型灵活性。对话嘉宾甄焱鲲分析幻觉本质无法根除,需辩证看待,并探讨类型分5类、缓解方法如In-Context-Learning及RAG,影响企业应用场景的容忍度与决策,强调未来模型或通过世界模型深化理解。