
奥特曼连夜挖走英特尔CTO!AI首席突然叛逃,陈立武被迫亲自挂帅
奥特曼连夜挖走英特尔CTO!AI首席突然叛逃,陈立武被迫亲自挂帅今天,OpenAI将英特尔首席AI官招入麾下,专攻算力基础设施建设,华人CEO救火亲自接管英特尔AI部门。与英伟达的仗还没打赢,自家后院就起了火。
来自主题: AI资讯
11232 点击 2025-11-11 18:01
 搜索
搜索
今天,OpenAI将英特尔首席AI官招入麾下,专攻算力基础设施建设,华人CEO救火亲自接管英特尔AI部门。与英伟达的仗还没打赢,自家后院就起了火。

当硅谷把「AGI造福全人类」包装成信仰时,真实世界却在付出代价。Karen Hao在《Empire of AI》犀利指出,这场竞赛甚至被渲染成「中美对抗」——只要跑赢中国,就能守护自由。但事实是,美国与中国差距并未拉大,唯一真正收割的,是硅谷自己。我们是否还要为这场幻觉买单?

上周 Kimi K2 Thinking 发布,开源模型打败 OpenAI 和 Anthropic,让它社交媒体卷起不小的声浪,网友们都在说它厉害,我们也实测了一波,在智能体、代码和写作能力上确实进步明

在AI技术飞速发展的当下,「驻场交付工程师」(FDE)正成为连接实验室与市场的关键角色。他们兼具算法能力与业务洞察,深入客户现场,将抽象模型转化为可落地的解决方案。OpenAI、Anthropic、Cohere等公司纷纷扩充FDE团队,这个趋势也开始在国内蔓延,以打通AI落地的「最后一公里」。

过去几个月,大型人工智能公司在印度动作频频。首先是 Perplexity AI 公司与印度第二大移动网络运营商 Airtel 合作,在印度免费提供其高级 Pro 版本。他们免费赠送了一份价值约 17000 卢比(约合人民币 1365 元)的年度订阅服务。这发生在 7 月份。此举拉开了更多类似合作的序幕。

近日,OpenAI 就公司财务状况发表公开声明而引发混乱后,面临不诚实的指控。而三天前,他的首席财务官提议政府应该“支持”该公司的基础设施贷款。她后来声称说错了话。OpenAI 首席执行官 Sam Altman 在三天前,他的首席财务官提议政府应该“支持”该公司的基础设施贷款。她后来声称说错了话。

一段令人心碎的离别视频走红:小女孩与AI玩具的深情告别,揭示了对话式AI如何悄然融入人类情感世界,预示着实时交互技术的革命性突破。
这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。
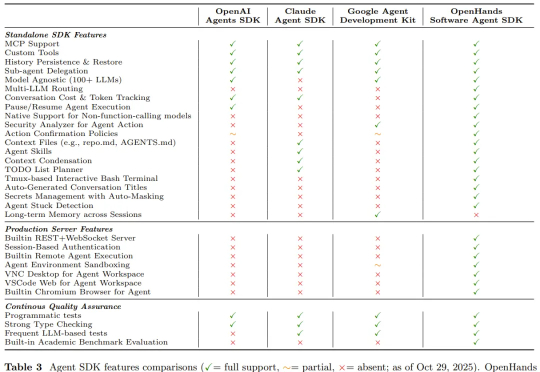
机器之心报道 编辑:Panda 刚刚,OpenHands 开发团队发布了一篇新论文,正式宣布广受欢迎的软件开发智能体框架 OpenHands (GitHub star 已超 6.4 万)中的智能体组件

杨红霞,是中国大模型领域一个无法绕开的名字。人们从 M6 模型(阿里达摩院发布的万亿参数 AI 大模型)开始熟知她,而她又在最近走出创业隐匿模式,正式向世界宣告自己已经是一名创业者,并希望能够做出下一