
一位网友逆向破解了 ChatGPT 记忆系统,给我干破防了
一位网友逆向破解了 ChatGPT 记忆系统,给我干破防了ChatGPT 号称是最有情商、越聊越懂你的 AI,但是,你有没有想过,它是怎么记住你的。昨天刷 X 的时候,我看到一个帖子。一个叫 Manthan Gupta 的开发者,做了一件挺疯狂的事。他花了好几天时间,通过对话实验逆向破解了 ChatGPT 的记忆系统。
来自主题: AI资讯
10128 点击 2025-12-16 10:26
 搜索
搜索
ChatGPT 号称是最有情商、越聊越懂你的 AI,但是,你有没有想过,它是怎么记住你的。昨天刷 X 的时候,我看到一个帖子。一个叫 Manthan Gupta 的开发者,做了一件挺疯狂的事。他花了好几天时间,通过对话实验逆向破解了 ChatGPT 的记忆系统。
AI 的脑回路,终于也开始学会做减法了。
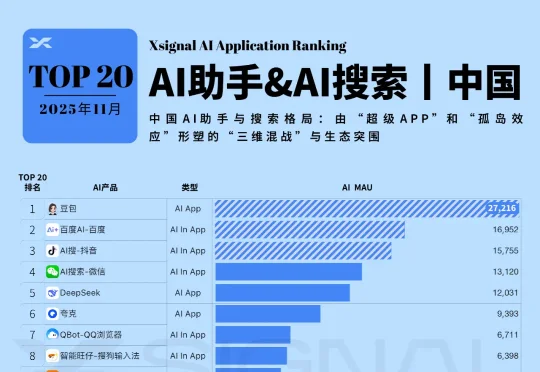
2025年,AI搜索行业进入了“模型商品化,分发定生死”的新阶段。 全球市场正经历一场双重变革:商业模式: 传统搜索巨头(Google)陷入严重的“创新者窘境”,庞大的广告营收成为其拥抱AI的最大掣肘;而挑战者(Perplexity, OpenAI)则通过“答案即行动”重塑商业闭环。

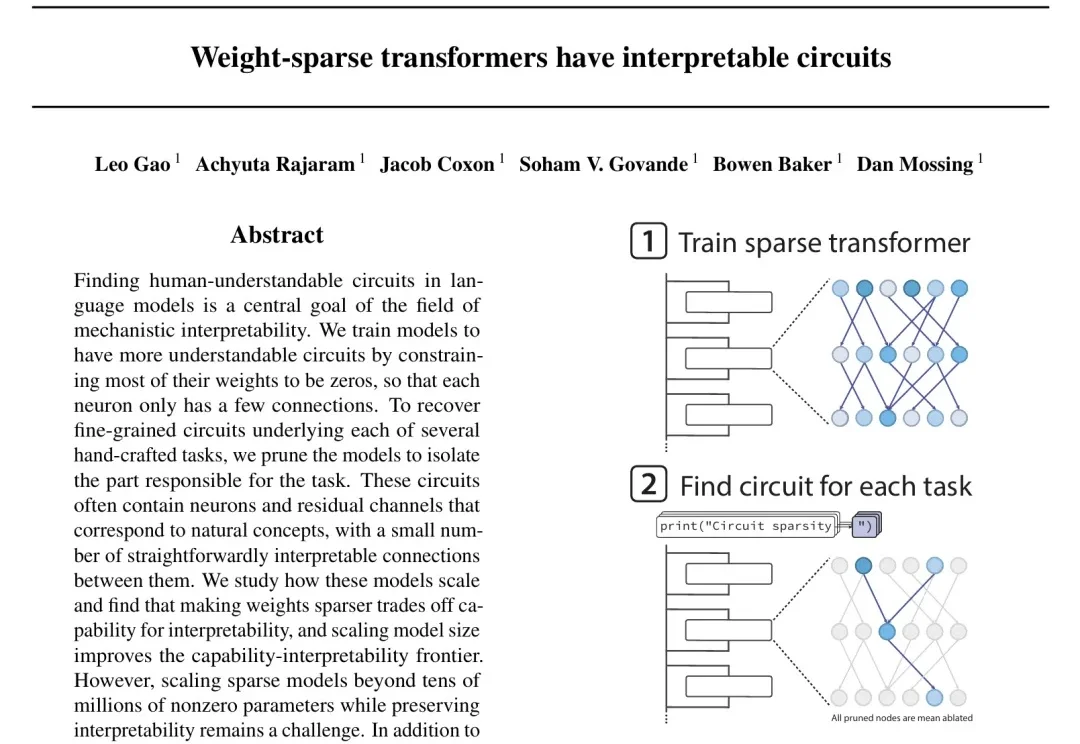
破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?
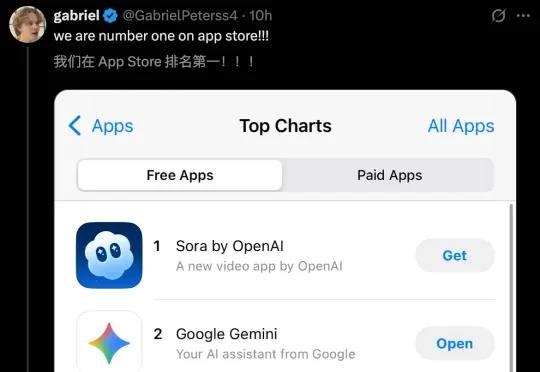
4人28天手搓Sora APP,约85%代码竟是AI写的!10月初,OpenAI重磅发布迭代后Sora 2,以及首个AI视频应用Sora APP。时隔两个月,OpenAI团队揭秘这款爆火应用(首个安卓版),如何构建的背后故事。

号称满分屠榜的GPT-5.2,一发布就降智了?许多网友现身表示,似乎确实比开始弱了很多。但提前实测的网友表示,它的确很强,甚至当得起GPT-6之称!
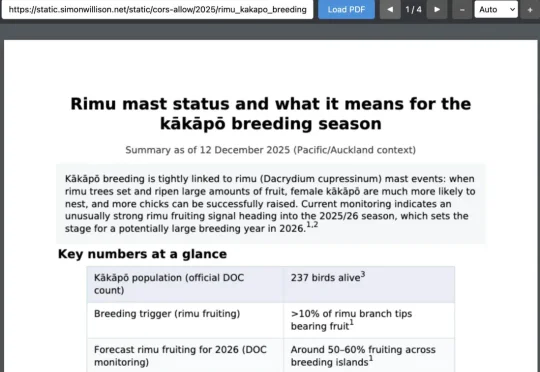
还在争论Skills是不是prompt?已经可以停下火了。因为,刚刚得到的消息消息,OpenAI已经悄悄地用上了Skills了。今天,知名博主、Django Web 框架联合创始人Simon Willson爆料:

大家还记得Mira Murati吗?那个曾经主导ChatGPT开发的“AI女王”,OpenAI的前CTO,2024年突然离职后,让整个科技圈炸锅!短短几个月,融资20亿美元,估值飙到120亿美元,现在更传出新一轮融资目标直冲500亿美元!这速度,这手笔,简直是AI界的“神话”!而最近的重磅炸弹来了:他们的首款产品Tinker正式全面开放!不再需要等待名单,人人可用!

GPT-5.2打赢Gemini 3.0 Pro,竟是靠高推理与海量Token「作弊」?网友的这个发现,在AI社区一石激起千层浪。更多网友七嘴八舌表示:GPT-5.2,并没有那么好用!

网友吐槽GPT-5.2「不通人性」。 X 上充斥着对 GPT-5.2 的恶评。昨天,OpenAI 十周年之际,拿出了最新的顶级模型 GPT-5.2 系列,官方号称是「迄今为止在专业知识工作上最强大的模型系列」,在众多基准测试中,GPT-5.2 也都刷新了最新的 SOTA 水平。