
AI斩获6枚金牌!华为Kaggle大师级智能体诞生,自主解决数据科学难题
AI斩获6枚金牌!华为Kaggle大师级智能体诞生,自主解决数据科学难题继 OpenAI o1 成为首个达到 Kaggle 特级大师的人工智能(AI)模型后,另一个 Kaggle 大师级 AI 也诞生了。
来自主题: AI技术研报
6305 点击 2024-11-14 20:36
 搜索
搜索
继 OpenAI o1 成为首个达到 Kaggle 特级大师的人工智能(AI)模型后,另一个 Kaggle 大师级 AI 也诞生了。

OpenAI治理研究员Richard Ngo宣布离职。近来,OpenAI中专注于AI安全的员工接连出走,Ngo是最新的一位。

五年内 AGI 还能否如期而至?

在未来,得AI者才能得天下。 今年年初,OpenAI发布了“文生视频”的工具Sora,仅凭几段视频,就让很多人见识到了AI生成视频的力量。

彭博今天消息,OpenAI 正准备推出一款代号为“Operator”的全新AI Agent产品,可以自动执行各种复杂操作,包括编写代码、预订旅行、自动电商购物等。

今天,OpenAI 联合创始人 Greg Brockman 宣布结束悠长假期,以总裁身份重返 OpenAI 。 「人生中最长的假期,结束了。」 Greg 在 X 上写道,回来继续搞事情。

2024年11月12日,在“百度世界大会”期间,百度创始人、CEO李彦宏与硅星人创始人骆轶航、甲子光年创始人张一甲进行了一场对谈。
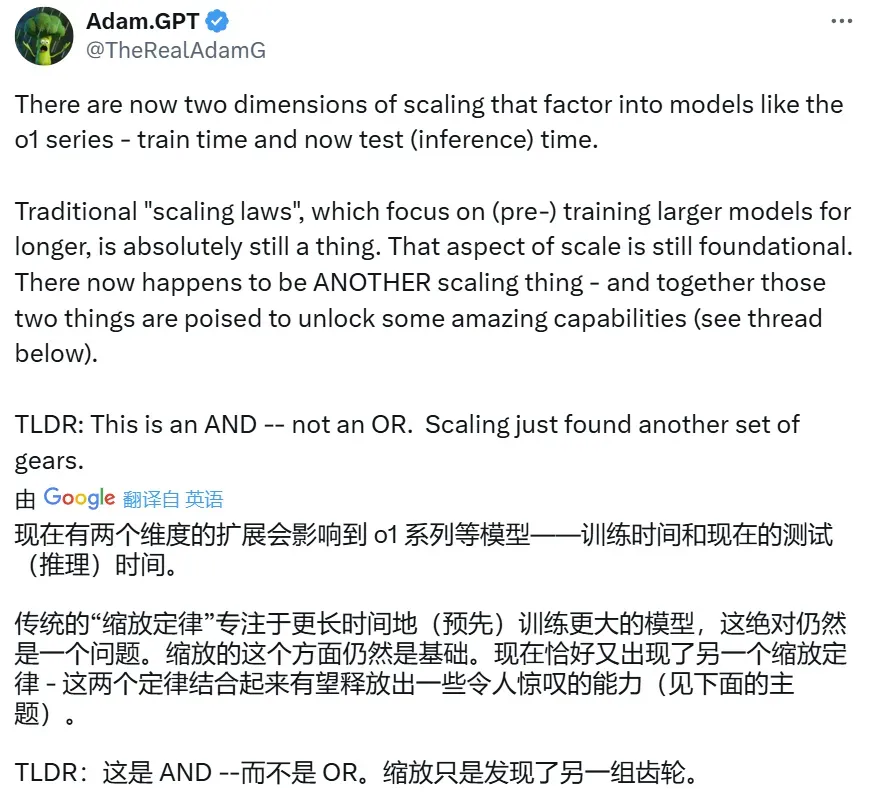
昨天,The Information 的一篇文章让 AI 社区炸了锅。

去年以来,包括纽约时报、Raw Story、The Intercept和AlterNet等在内的多家机构,针对ChatGPT所属的公司OpenAI提起诉讼,指控ChatGPT非法使用了新闻网站文章用于训练。近日,纽约联邦法官驳回了Raw Story和Alternet对OpenAI聊天机器人的训练数据提起的版权诉讼。

Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的对象究竟应该是什么。他自曝,SSI在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达GPU的垄断地位或许也要打破了。