开源万亿模型Ring-2.5-1T接管了我的终端,还给自己的大脑写了个实现
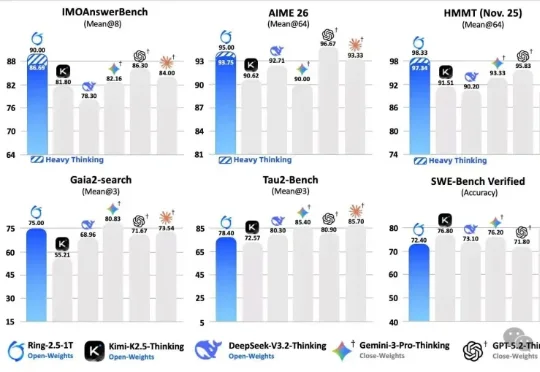
开源万亿模型Ring-2.5-1T接管了我的终端,还给自己的大脑写了个实现先介绍一下今天的主角。Ring-2.5-1T,蚂蚁百灵团队刚发布的万亿参数开源思考模型,全球首个混合线性注意力架构的万亿级选手。IMO 2025 国际奥数 35/42 拿到金牌水平,CMO 2025 中国奥数 105 分远超国家集训队线 87 分,GAIA2 通用 Agent 评测开源 SOTA。数字很漂亮,但数字谁都会贴。
来自主题: AI资讯
9247 点击 2026-02-13 23:30