
Nature重磅:AI又一突破,穿越千年,填补人类缺失的历史
Nature重磅:AI又一突破,穿越千年,填补人类缺失的历史AI 正在扩展人类认知。 人类历史始于书写。铭文是最早的书写形式之一,提供了关于古代文明思想、语言和历史的直接洞见。
来自主题: AI资讯
10489 点击 2025-07-24 10:46
 搜索
搜索
AI 正在扩展人类认知。 人类历史始于书写。铭文是最早的书写形式之一,提供了关于古代文明思想、语言和历史的直接洞见。

7月2日,一个跨国团队在Nature杂志发表了一项开创性研究,宣称其推出的AI系统能够“模拟人类心智”。该系统在实验中可以“扮演”人类,生成逼真的人类行为。
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。
借助AI,新型蛋白质合成周期大幅降低!
AI现在有味觉了!
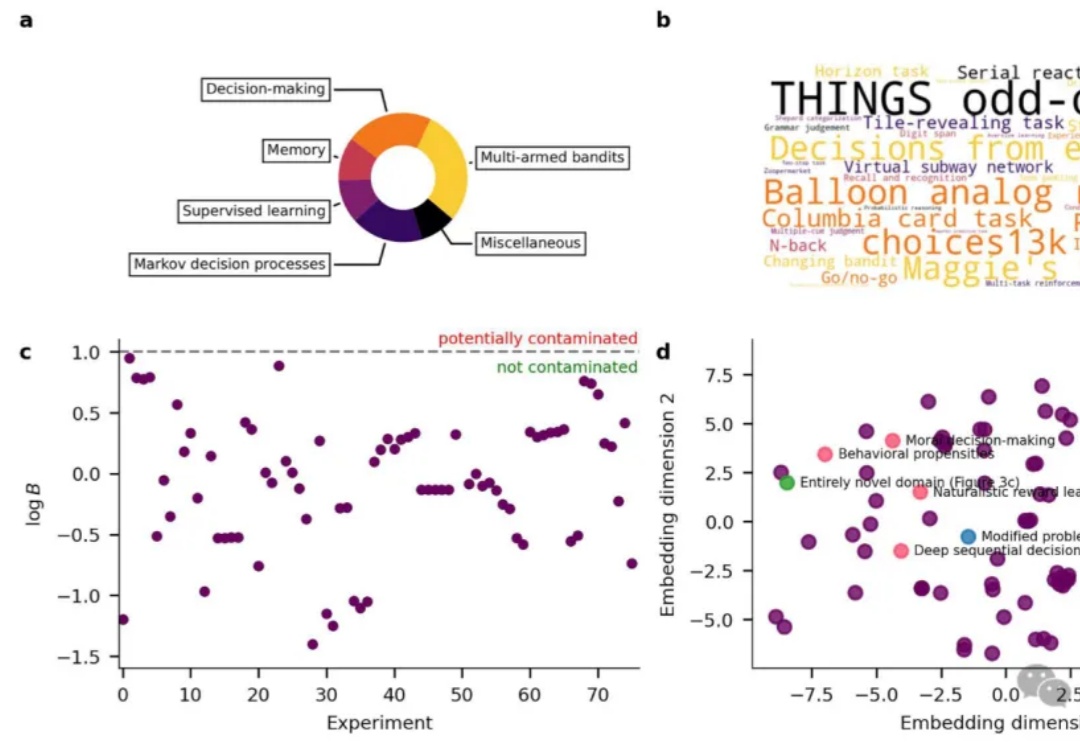
首个能跨领域精准预测人类认知的基础模型诞生!
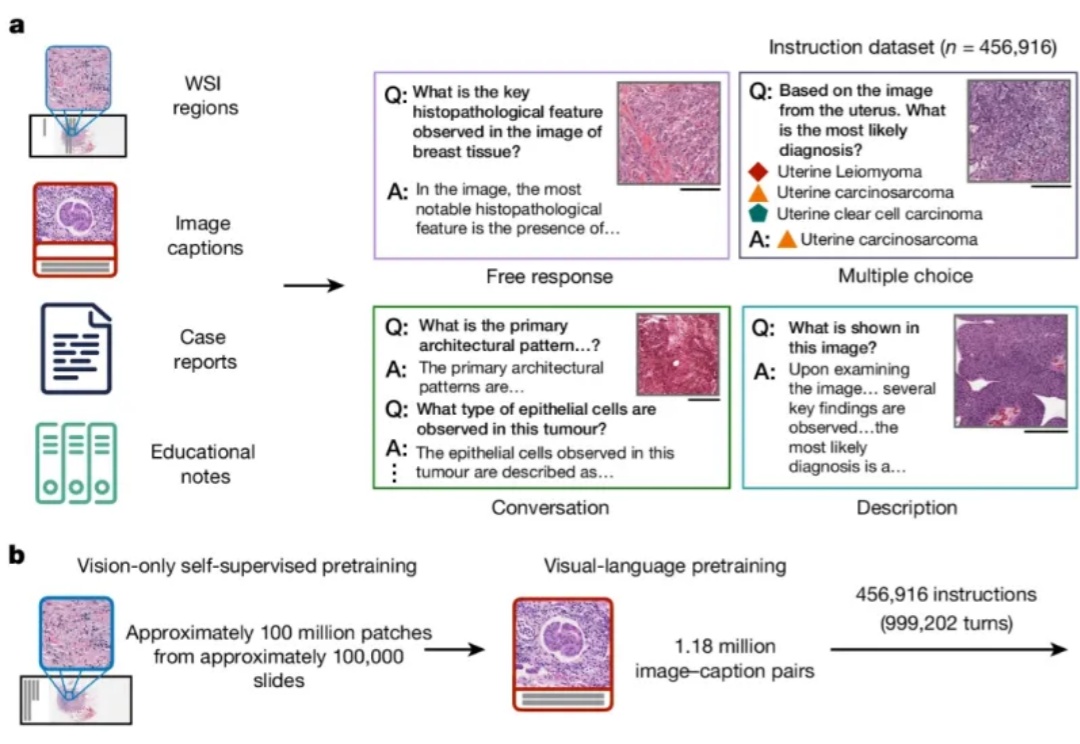
近日,AI医疗初创企业Modella AI宣布与阿斯利康一项多年期协议。

AI现在真能救命!传统的心脏MRI(磁共振成像)检查可能遗漏的关键风险信号,现在能够被AI捕捉了。
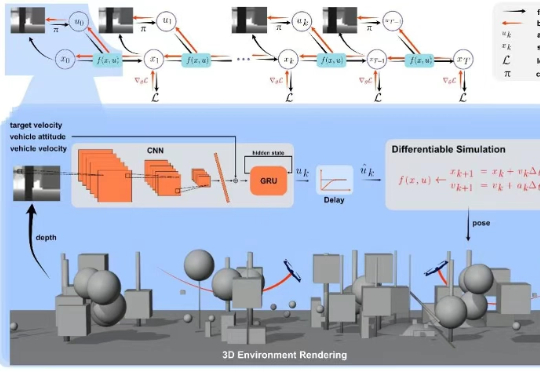
上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,该研究首次将可微分物理训练的策略成功部署到现实机器人中,实现了无人机集群自主导航,并在鲁棒性、机动性上大幅领先现有的方案。

近日,上海举办了2025生物科学智能产业生态创新发展高峰论坛。