3B Image Captioning小钢炮重磅来袭,性能比肩Qwen2.5-VL-72B
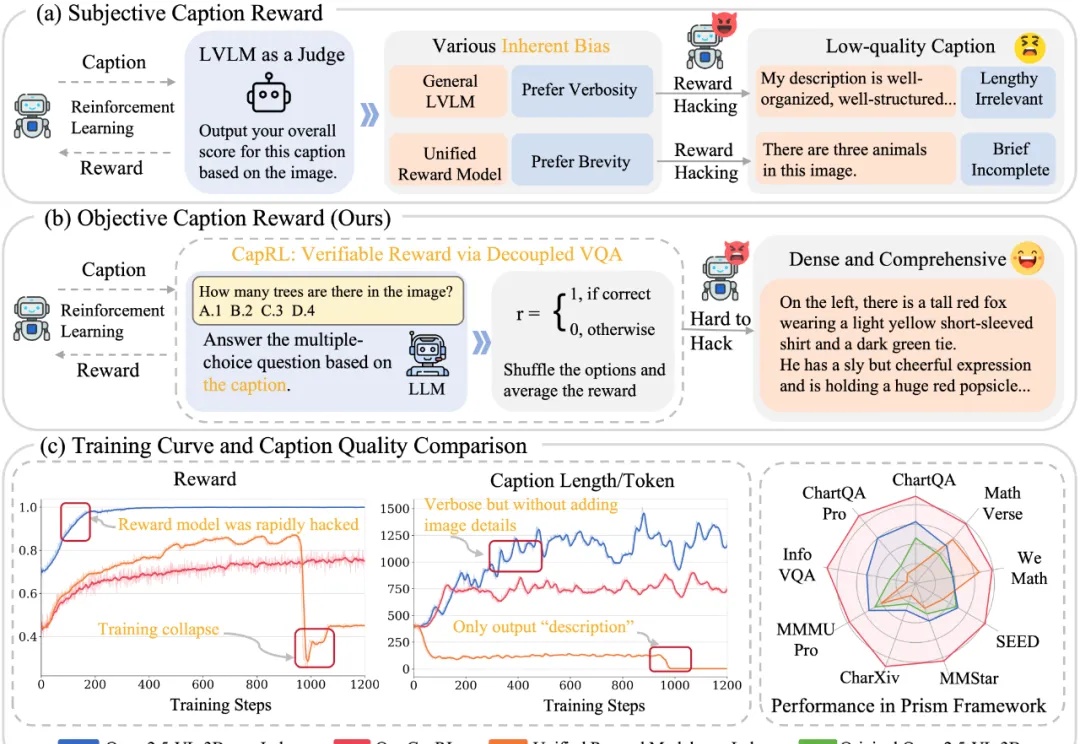
3B Image Captioning小钢炮重磅来袭,性能比肩Qwen2.5-VL-72B今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
来自主题: AI技术研报
10595 点击 2025-10-29 10:24