
又一苹果华人AI高管被Meta高薪挖走了,这次是清华校友CMU博士
又一苹果华人AI高管被Meta高薪挖走了,这次是清华校友CMU博士苹果又一华人AI高管被Meta挖走了!据彭博社爆料,这次被挖的是Ke Yang(杨克),负责AI搜索与问答系统,几周前刚被任命为AKI团队负责人,负责让Siri追赶上ChatGPT等主流大模型的能力。而离职消息一出,苹果AI的未来或又将添上许多变数。
来自主题: AI资讯
8488 点击 2025-10-16 15:51
 搜索
搜索
苹果又一华人AI高管被Meta挖走了!据彭博社爆料,这次被挖的是Ke Yang(杨克),负责AI搜索与问答系统,几周前刚被任命为AKI团队负责人,负责让Siri追赶上ChatGPT等主流大模型的能力。而离职消息一出,苹果AI的未来或又将添上许多变数。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。

全球首个AI Agent交易市场MuleRun(骡子快跑)正式上线,面向所有用户开放使用。MuleRun的Logo是一个像素风骡子,平台上集合了不同类型的多个Agent。Agent的创作者多为各领域中懂得某个具体流程、有经验的人,他们将自己的技能变为工作流后做成Agent。
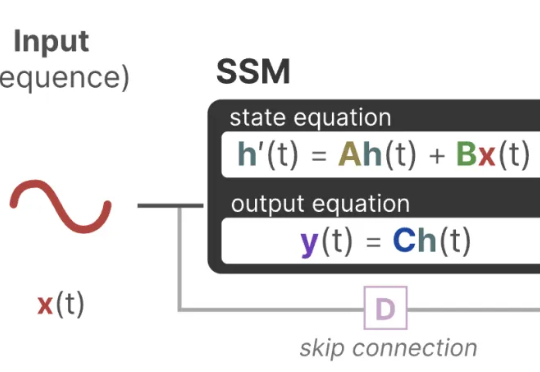
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。
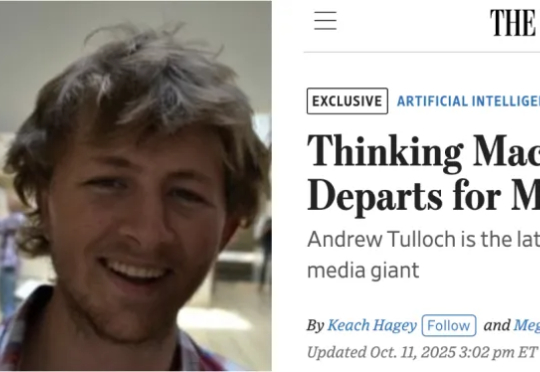
那个拒绝了小扎15亿美元薪酬包的机器学习大神,还是加入Meta了。OpenAI前CTO Mira Murati创业公司Thinking Machines Lab证实,联创、首席架构师Andrew Tulloch已经离职去了Meta。
Prezent 是一家为企业提供人工智能演示文稿制作工具的初创公司,今日宣布完成 3000 万美元融资。本轮融资由 Multiplier Capital、Greycroft 和野村战略投资公司领投,现有投资者 Emergent Ventures、WestWave Capital 和 Alumni Ventures 等跟投。
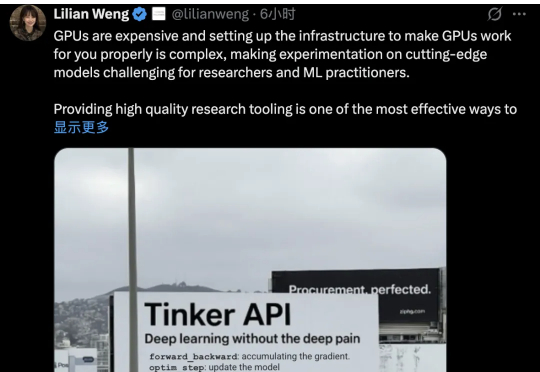
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”
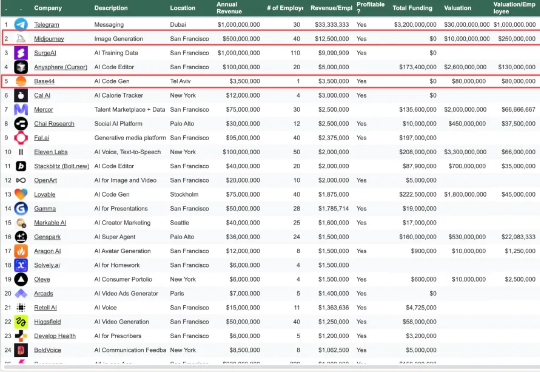
这几天饼干哥哥都在杭州云栖大会,这一届的阿里AI大会,有一种经济上行的感觉,人是真的多,有几次论坛都挤不进去 例如这个AI Coding的交流 今天下午参加了MuleRun的论坛,坐在前排老老实实的听
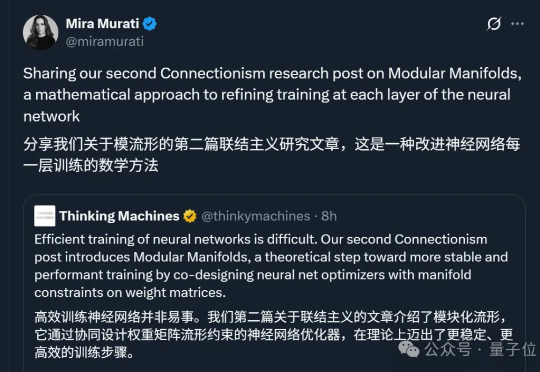
明星创业公司Thinking Machines,第二篇研究论文热乎出炉!公司创始人、OpenAI前CTO Mira Murati依旧亲自站台,翁荔等一众大佬也纷纷转发支持:论文主题为“Modular Manifolds”,通过让整个网络的不同层/模块在统一框架下进行约束和优化,来提升训练的稳定性和效率。

智能体开发平台3.0(ADP3.0)面向全球上线,腾讯优图实验室的关键智能体技术也将持续开源。据说,这次新版本打磨了3个月,完成近600个功能上线,从RAG能力到Workflow,从Multi-Agent协同到应用评测,再到插件生态,看样子是把所有模块都更新了一遍。