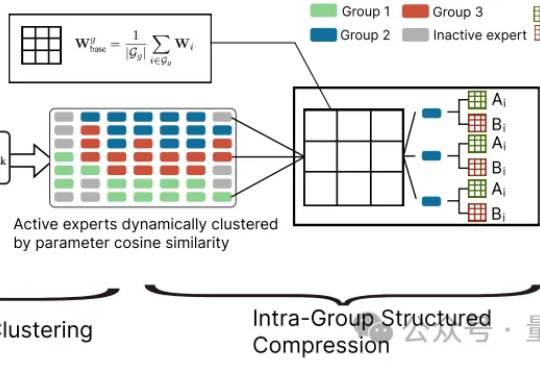
破解MoE模型“规模越大,效率越低”困境!中科院自动化所提出新框架
破解MoE模型“规模越大,效率越低”困境!中科院自动化所提出新框架大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境?中科院自动化所新研究给出破局方案——首次让MoE专家告别“静态孤立”,开启动态“组队学习”。
来自主题: AI技术研报
9075 点击 2025-10-13 10:26
 搜索
搜索
大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境?中科院自动化所新研究给出破局方案——首次让MoE专家告别“静态孤立”,开启动态“组队学习”。
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
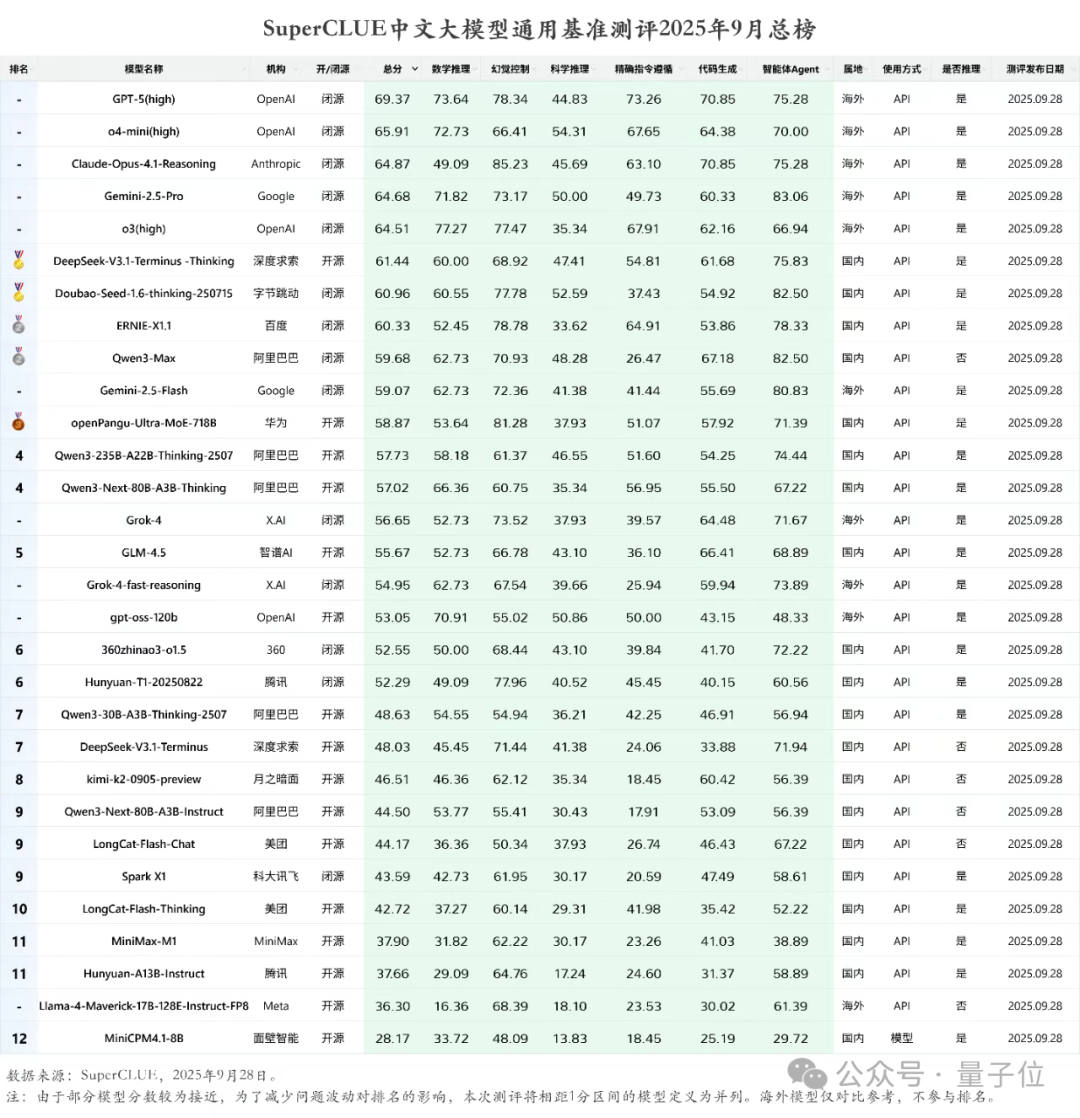
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507
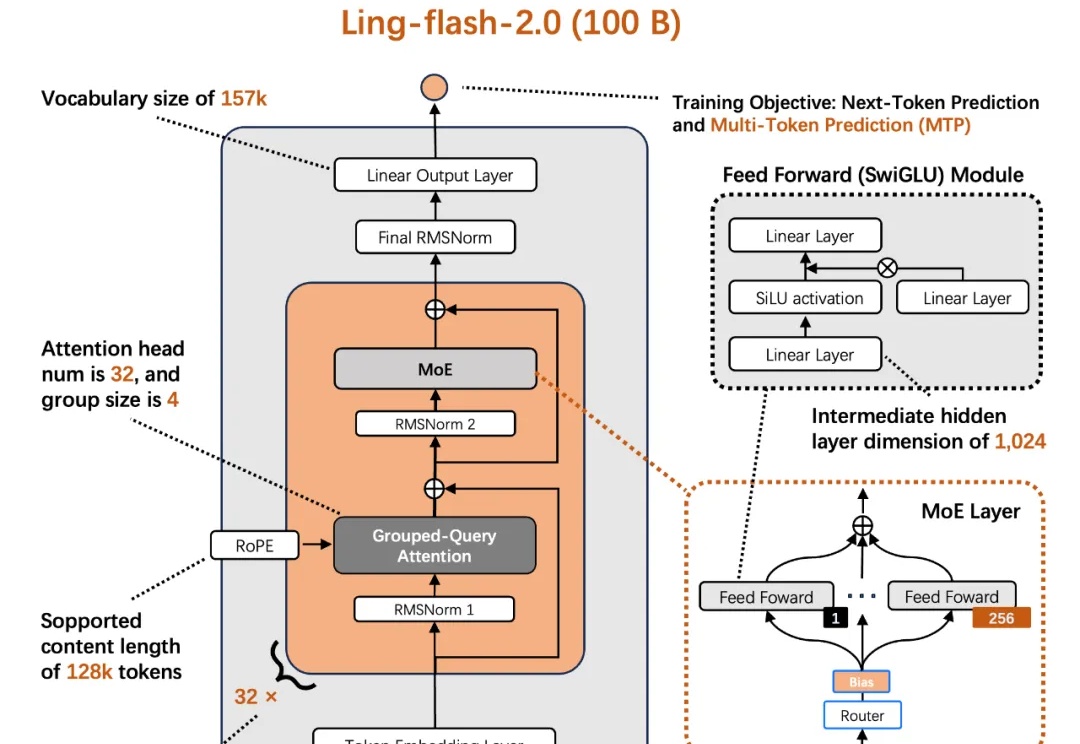
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。

挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。
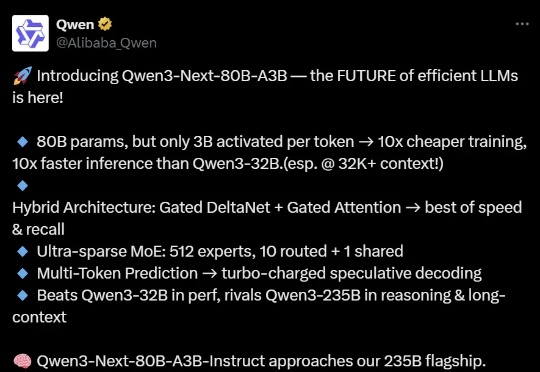
训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。
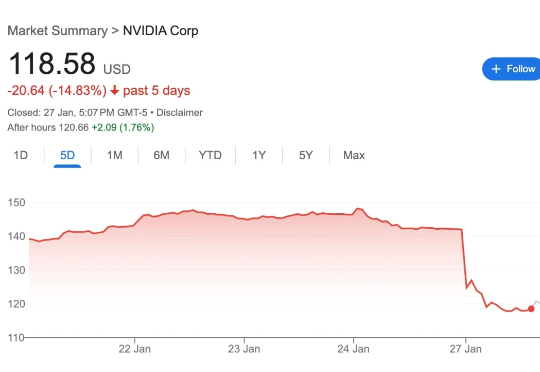
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。

昨天,美团低调地开源了其560B参数的混合专家(MoE)模型——LongCat-Flash。 一时间,大家的目光都被吸引了过去,行业内的讨论大多围绕着它在公开基准测试中媲美顶尖模型的性能数据,以及其精巧的MoE架构设计。
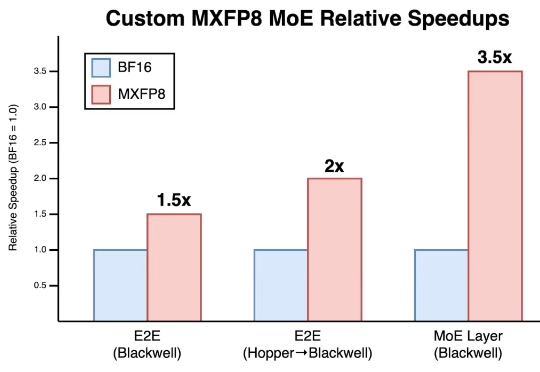
在构建更强大的 AI 模型的这场竞赛中,传统路径很简单:升级到最新最强大的硬件。但 Cursor 发现释放下一代 GPU 的真正潜力远非即插即用那么简单。
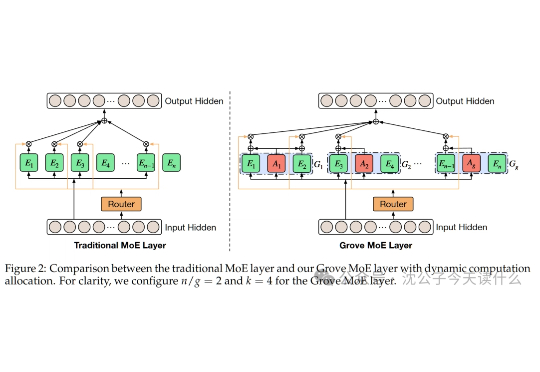
一句话概括,传统MoE就像公司派固定人数团队,Grove MoE则像智能调度系统,小项目派少数人,大项目集中火力,效率与效果兼得。