
用MoE横扫99个子任务!浙大等提出全新通用机器人策略GeRM
用MoE横扫99个子任务!浙大等提出全新通用机器人策略GeRM多任务机器人学习在应对多样化和复杂情景方面具有重要意义。然而,当前的方法受到性能问题和收集训练数据集的困难的限制
来自主题: AI技术研报
8157 点击 2024-04-17 18:16
 搜索
搜索
多任务机器人学习在应对多样化和复杂情景方面具有重要意义。然而,当前的方法受到性能问题和收集训练数据集的困难的限制
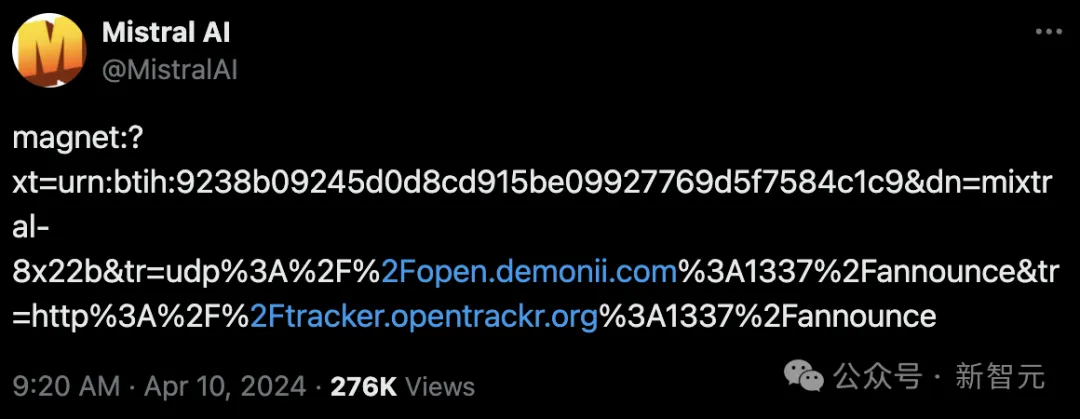
一条磁力链,Mistral AI又来闷声不响搞事情。
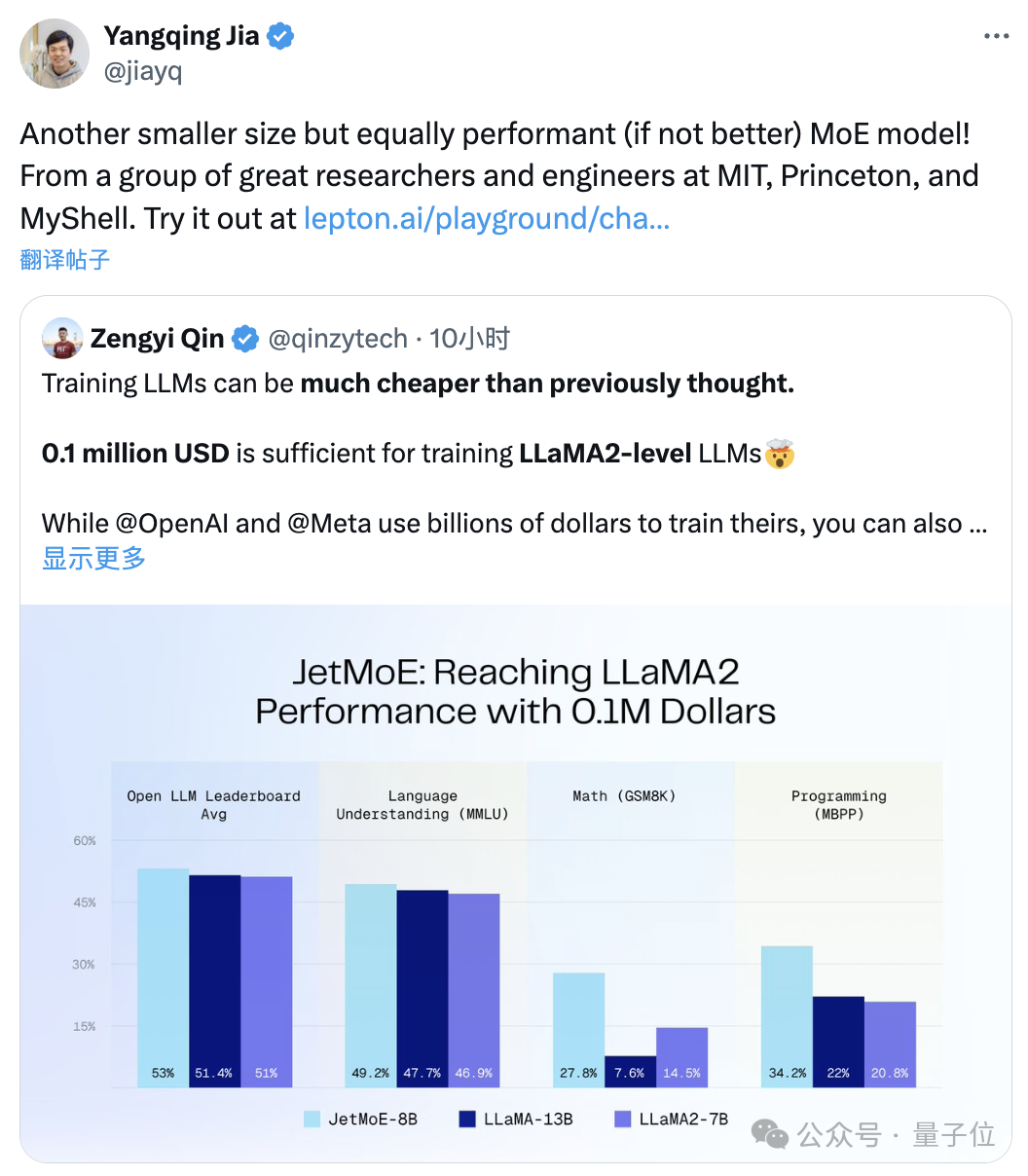
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。

一年一度的CVPR 2024录用结果出炉了。今年,共有2719篇论文被接收,录用率为23.6%。

AI音乐大模型最近有多火,不用多介绍了吧?不过,海外版应用别的先不说,奇奇怪怪的中文AI发音就能把人难受死……好在卷应用嘛,国产大模型厂商没在怕的,这不,国产版音乐“ChatGPT”这就来了~
LLM战场的新玩家,一出手就是王炸!信仰Scaling Law的阶跃星辰,一口气带来了Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型,以及Step-2万亿参数MoE语言大模型的预览版。而阶跃星辰之旅,终点就是AGI。

国内基础大模型创业公司,最后一位强实力选手终于正式来到台前。它就是微软前全球副总裁姜大昕所创办的阶跃星辰。

昆仑万维发布「天工3.0」,开启公测。
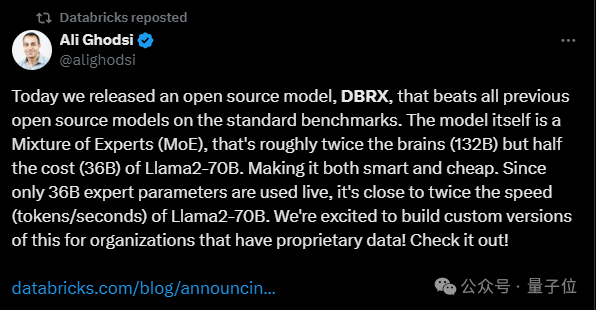
“最强”开源大模型之争,又有新王入局:

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。