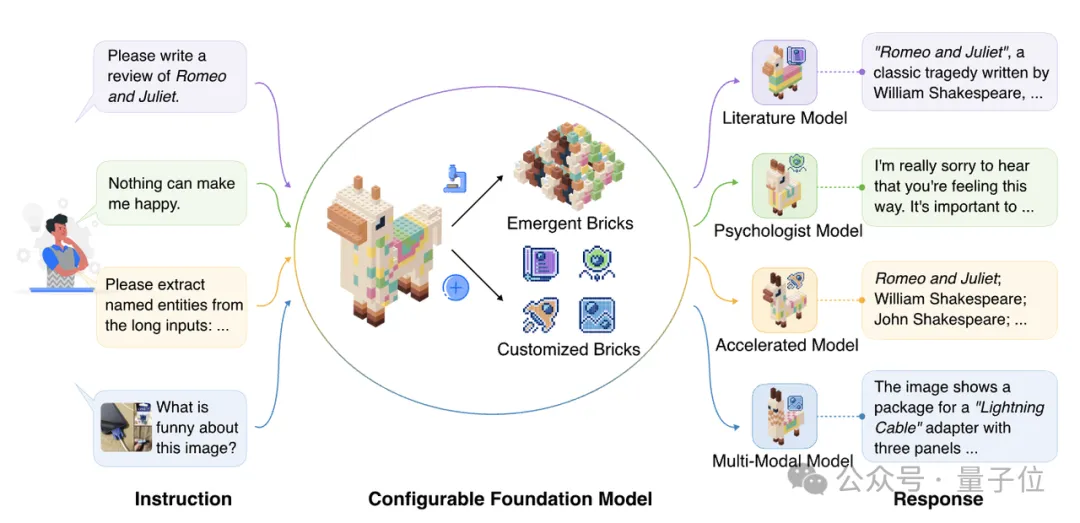
清华团队革新MoE架构!像搭积木一样构建大模型,提出新型类脑稀疏模块化架构
清华团队革新MoE架构!像搭积木一样构建大模型,提出新型类脑稀疏模块化架构探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。
来自主题: AI技术研报
5036 点击 2024-11-01 17:11
 搜索
搜索
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。

时序大模型,参数规模突破十亿级别。 来自全球多只华人研究团队提出了一种基于混合专家架构(Mixture of Experts, MoE)的时间序列基础模型——Time-MoE。

Time-MoE采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。研发团队还发布了Time-300B数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。

比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

7 年前,谷歌在论文《Attention is All You Need》中提出了 Transformer。就在 Transformer 提出的第二年,谷歌又发布了 Universal Transformer(UT)。它的核心特征是通过跨层共享参数来实现深度循环,从而重新引入了 RNN 具有的循环表达能力。
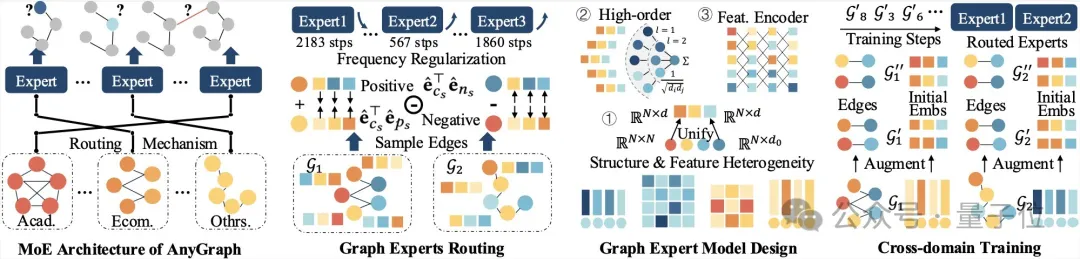
新型图基础模型来了—— AnyGraph,基于图混合专家(MoE)架构,专门为实现图模型跨场景泛化而生。
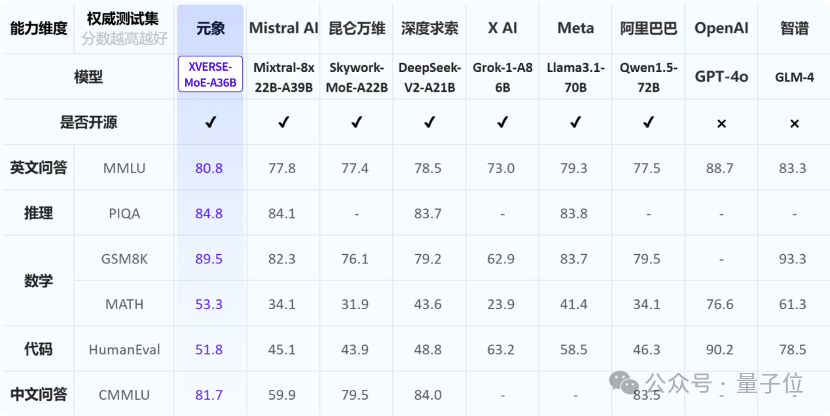
元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。

鹅厂新一代旗舰大模型混元Turbo技术报告首次曝光。模型采用全新分层异构的MoE架构,总参数达万亿级别,性能仅次于GPT-4o,位列国内第一梯队。