
估值飙升,Mistral AI成微软第二条“大腿”
估值飙升,Mistral AI成微软第二条“大腿”2月26日,总部位于巴黎的人工智能公司Mistral AI发布尖端文本生成模型Mistral Large。该模型达到了顶级的推理能力,可用于复杂的多语言推理任务,包括文本理解、转换和代码生成。
来自主题: AI资讯
5196 点击 2024-02-28 16:22
 搜索
搜索
2月26日,总部位于巴黎的人工智能公司Mistral AI发布尖端文本生成模型Mistral Large。该模型达到了顶级的推理能力,可用于复杂的多语言推理任务,包括文本理解、转换和代码生成。

大模型内卷时代,也不断有人跳出来挑战Transformer的统治地位,RWKV最新发布的Eagle 7B模型登顶了多语言基准测试,同时成本降低了数十倍
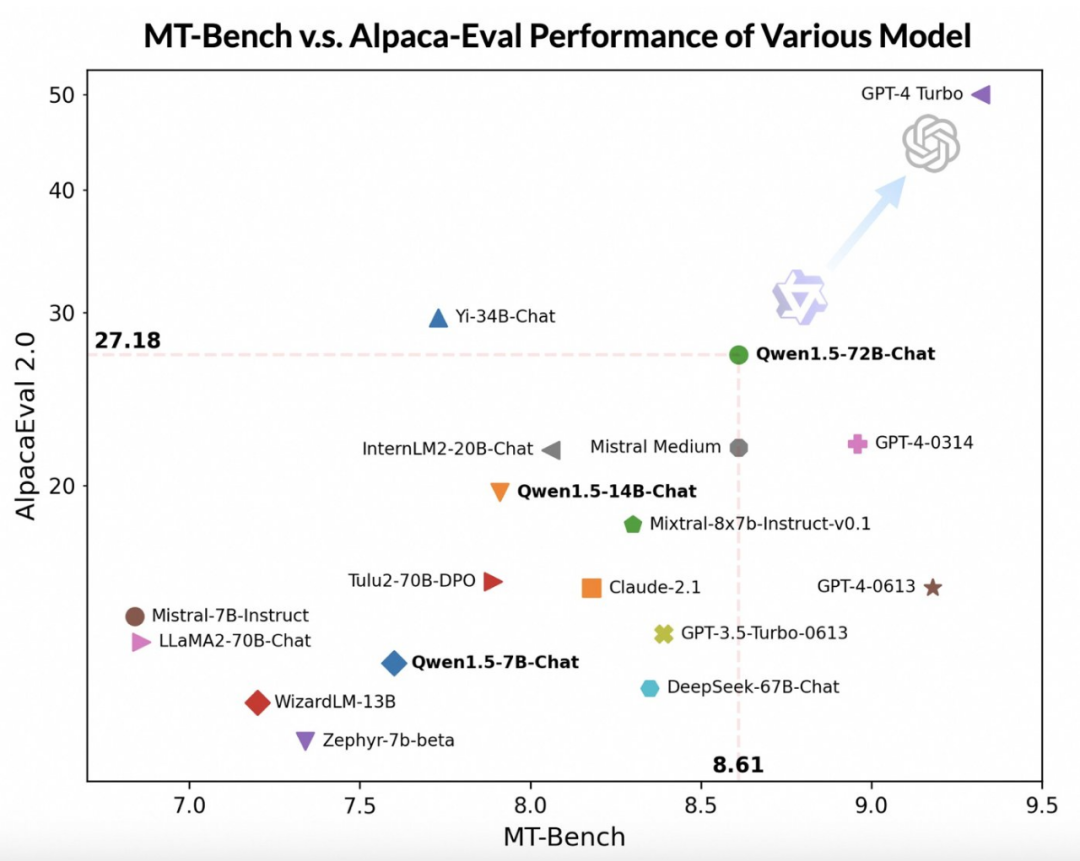
赶在春节前,通义千问大模型(Qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 AI 社区关注。

一个体量仅为2B的大模型,能有什么用?答案可能超出你的想象。
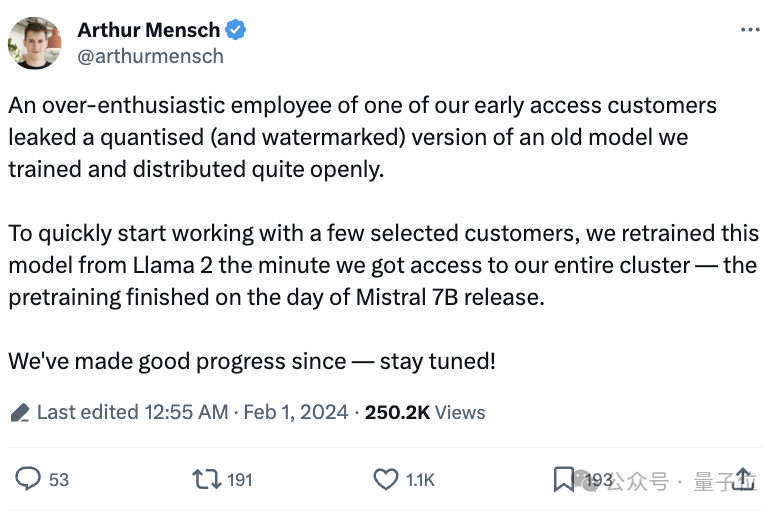
Mistral-Medium竟然意外泄露?此前仅能通过API获得,性能直逼GPT-4。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

2B性能小钢炮来了!刚刚,面壁智能重磅开源了旗舰级端侧多模态模型MiniCPM,2B就能赶超Mistral-7B,还能越级比肩Llama2-13B。成本更是低到炸裂,170万tokens成本仅为1元!
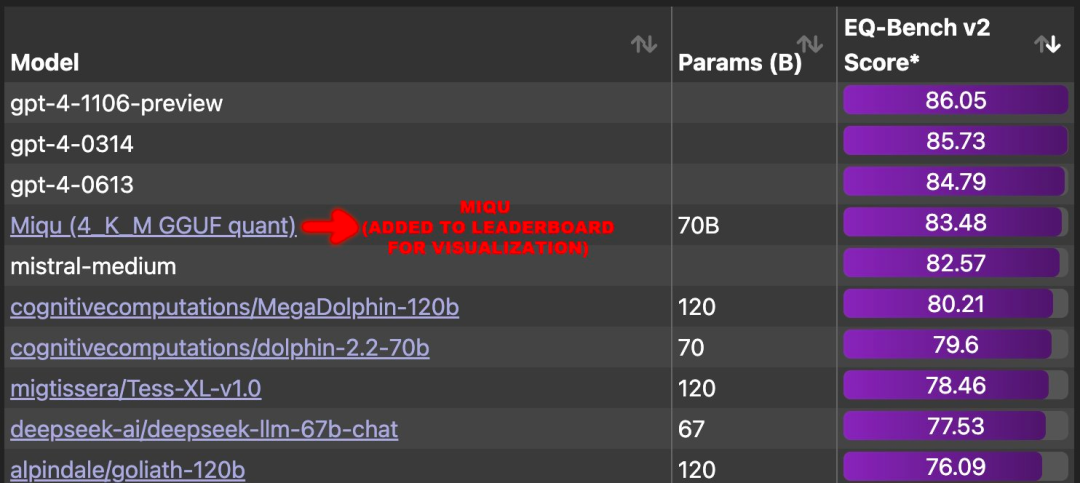
近日,一则关于「Mistral-Medium 模型泄露」的消息引起了大家的关注。

融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM
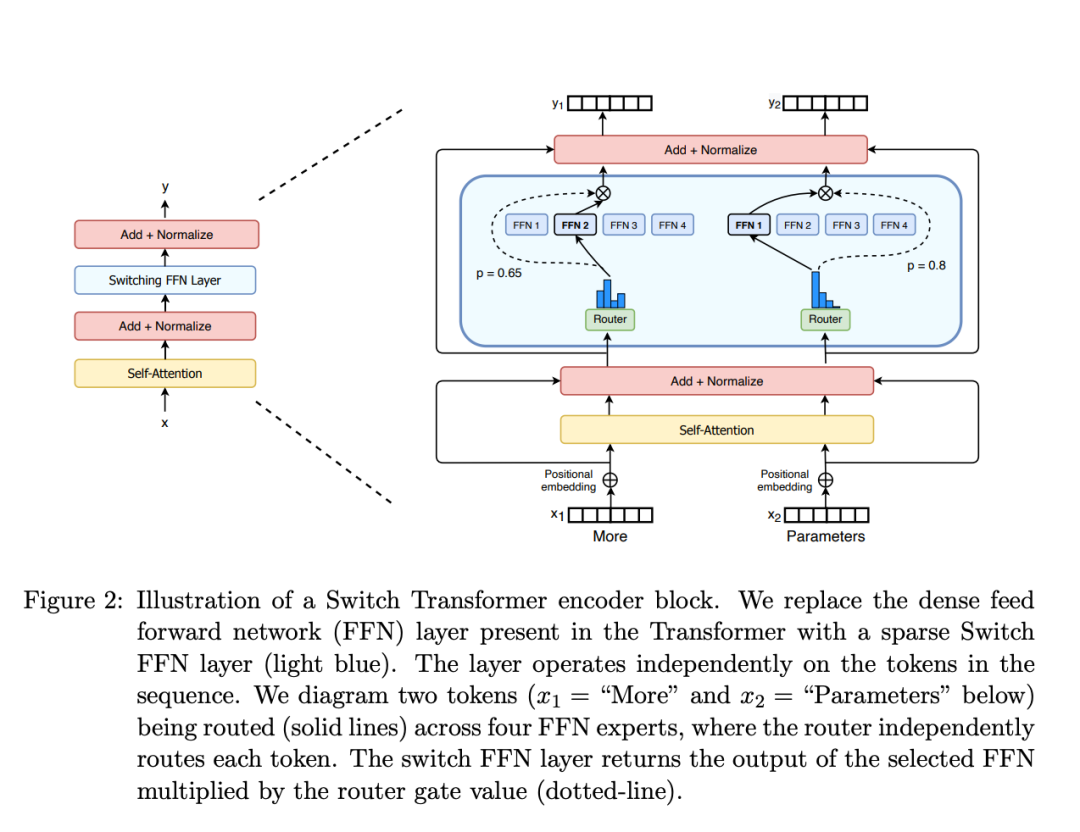
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。