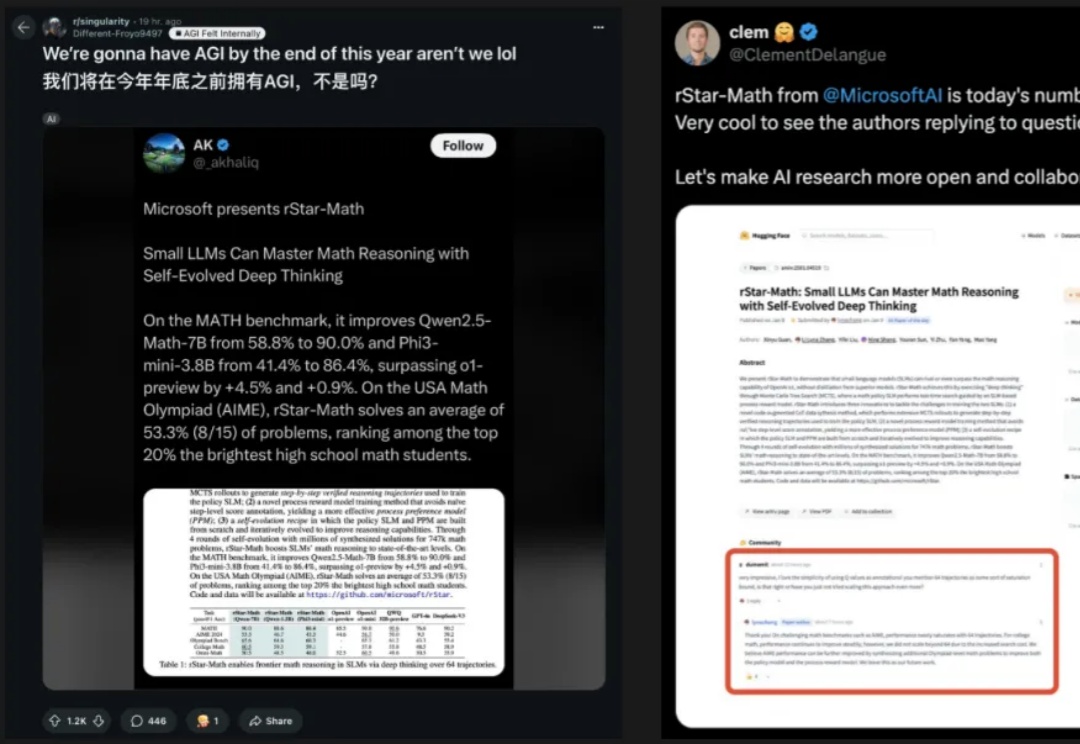
7B模型数学推理击穿o1,直逼全美20%尖子生!四轮进化,微软华人新作爆火
7B模型数学推理击穿o1,直逼全美20%尖子生!四轮进化,微软华人新作爆火小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。
来自主题: AI技术研报
4952 点击 2025-01-10 15:51
 搜索
搜索
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。
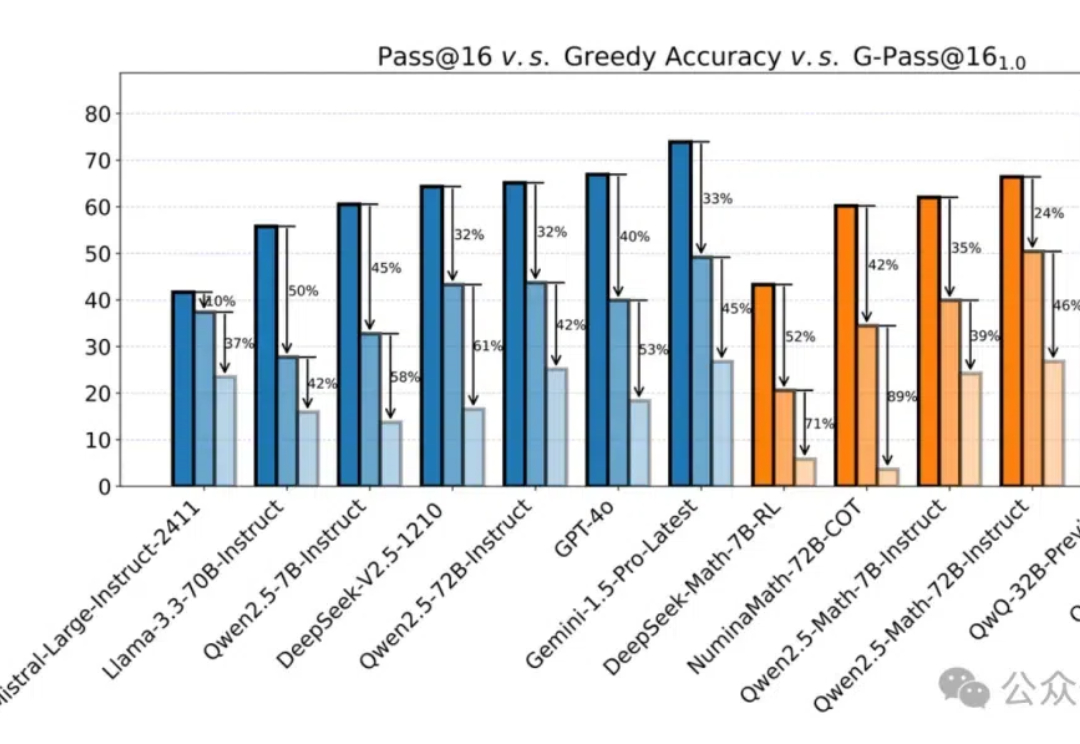
新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。

数学大佬陶哲轩和OpenAI两位高管最近进行了一场线上对谈,主题为“The Future of Math with o1 Reasoning”,即以推理为主的o1模型如何与数学融合,从而解锁突破性的科学进步。
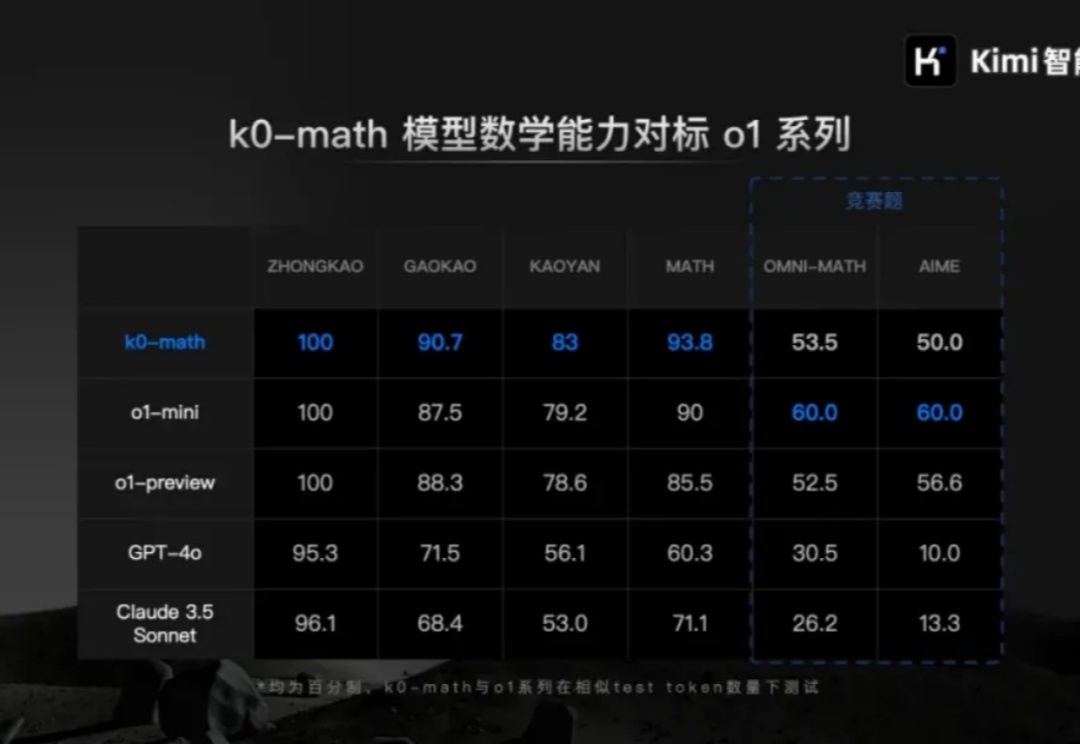
11 月 16 日,久未露面的月之暗面创始人杨植麟突然现身,召开了一场媒体发布会。
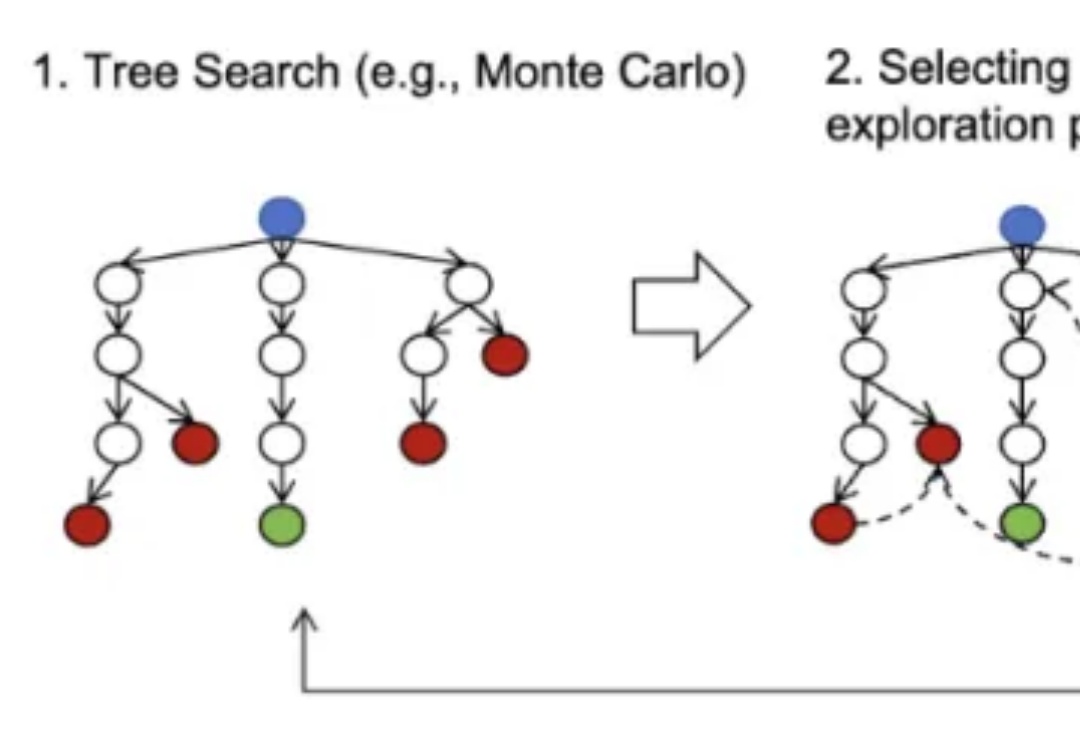
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
11月16日,陷入前投资人仲裁风波的主角杨植麟突然出现,并对外发布了一款数学模型。 杨植麟将自己的数学模型k0-math对标OpenAI o1系列,主打深入思考。
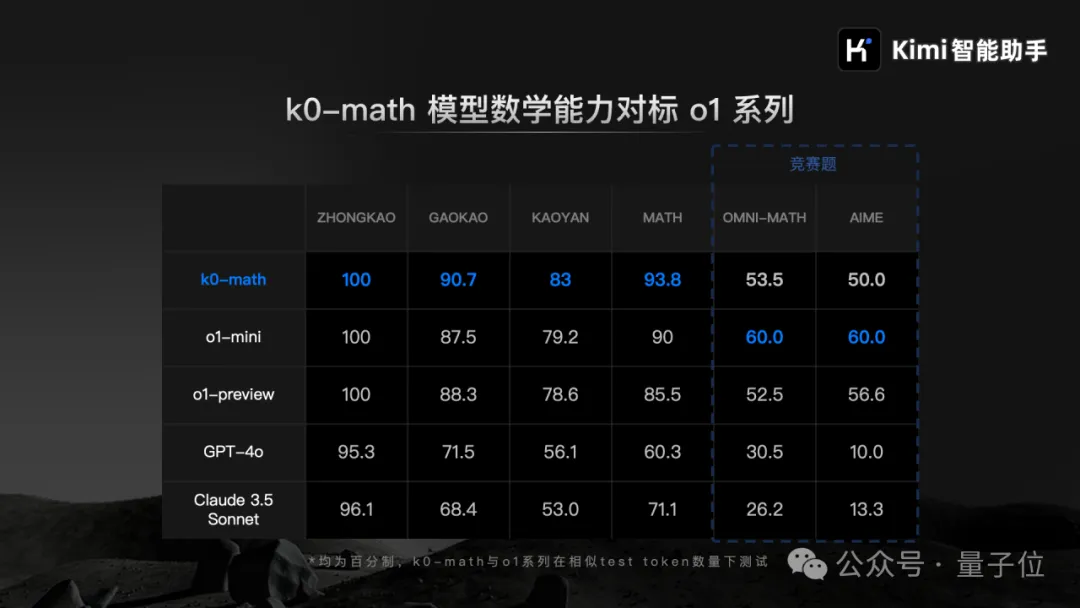
kimi全面开放一周年之际,创始人杨植麟亲自发布新模型—— 数学模型k0-math,对标OpenAI o1系列,主打深入思考。 在MATH、中考、高考、考研4个数学基准测试中,k0-math成绩超过o1-mini和o1-preview。
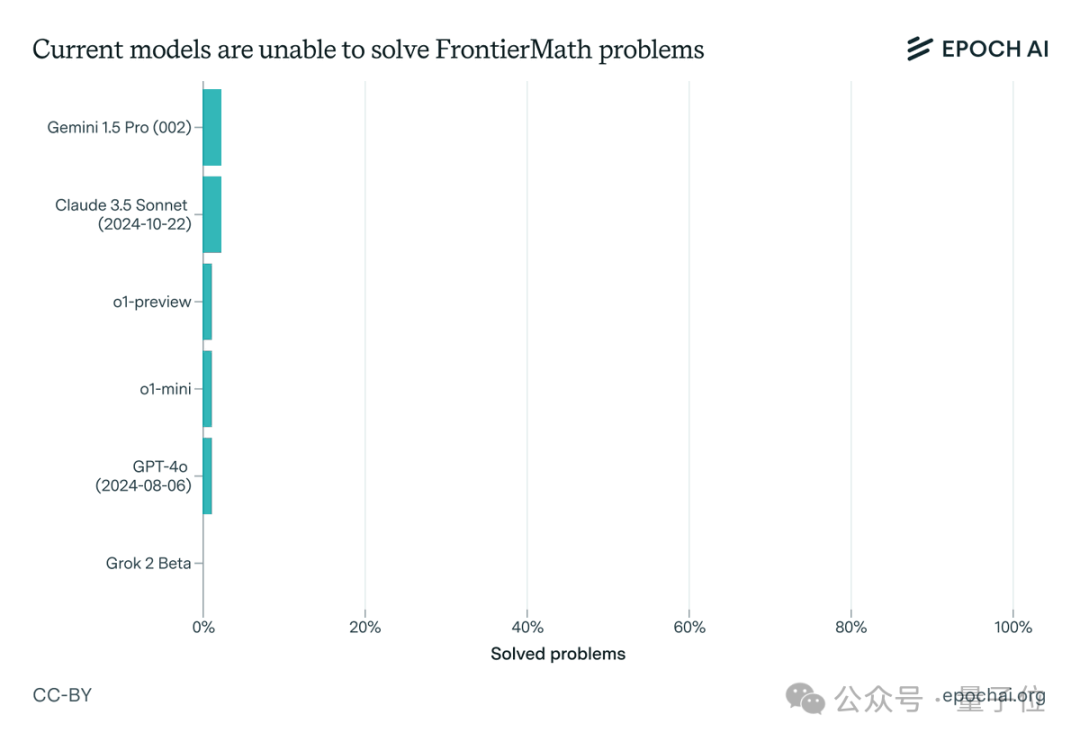
让大模型集体吃瘪,数学题正确率通通不到2%!

Epoch AI推出数学基准FrontierMath,目前前沿模型测试成功率均低于2%!OpenAI研究科学家Noam Brown说道:「我喜欢看到新评估的前沿模型通过率如此之低。这种感觉就像一觉醒来,外面是一片崭新的雪地,完全没有人迹。」或许,FrontierMath测试成功率突破的那一天,会是AI发展过程中一个全新的里程碑。
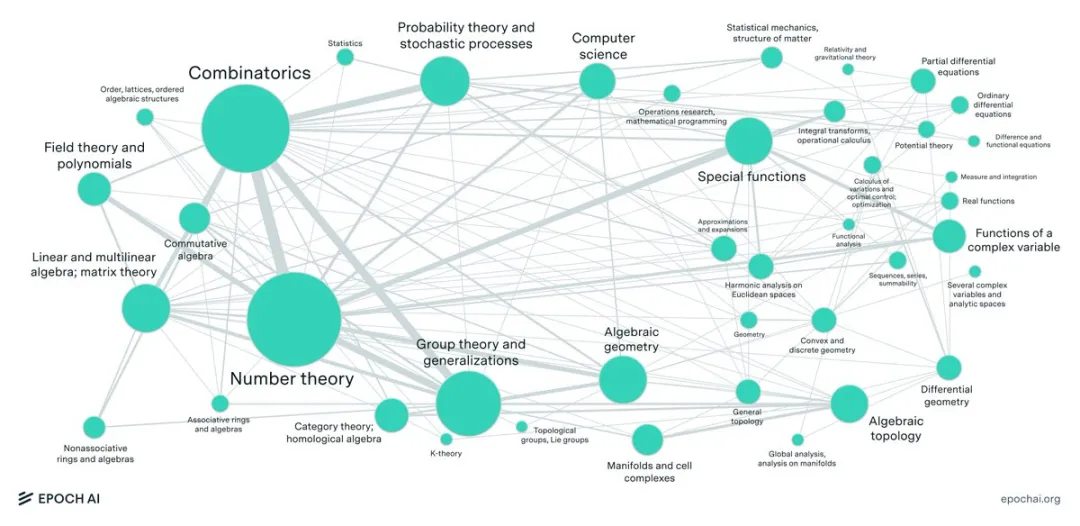
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!