
GPT-5被吐槽没进步?Epoch年终报告打脸:AI在飞速狂飙,ASI更近了!
GPT-5被吐槽没进步?Epoch年终报告打脸:AI在飞速狂飙,ASI更近了!Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。
来自主题: AI技术研报
8213 点击 2025-12-25 10:49
 搜索
搜索
Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。

昨晚,数学界炸了!由HarmonicMath开发的AI数学家「亚里士多德」(Aristotle),100%独立完成了埃尔德什问题#124。它在Lean证明系统中,耗时仅6个小时,验证只需1分钟。

沉寂许久的DeepSeek又回来了!今天,DeepSeekMath-V2重磅登场,一举夺下IMO 2025金牌,实力媲美甚至超越了谷歌的IMO金牌模型,开源AI再次扳回一局。
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。

当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。

一次咖啡馆中的谈话,诞生了一家估值3亿美元的创业公司!2024年,仍为斯坦福大学博士生的Carina Hong与前Meta的AI研究员Shubho Sengupta有过一次数小时的交谈。在那次交谈中二人探讨了如何用AI来解决数学领域的难题。
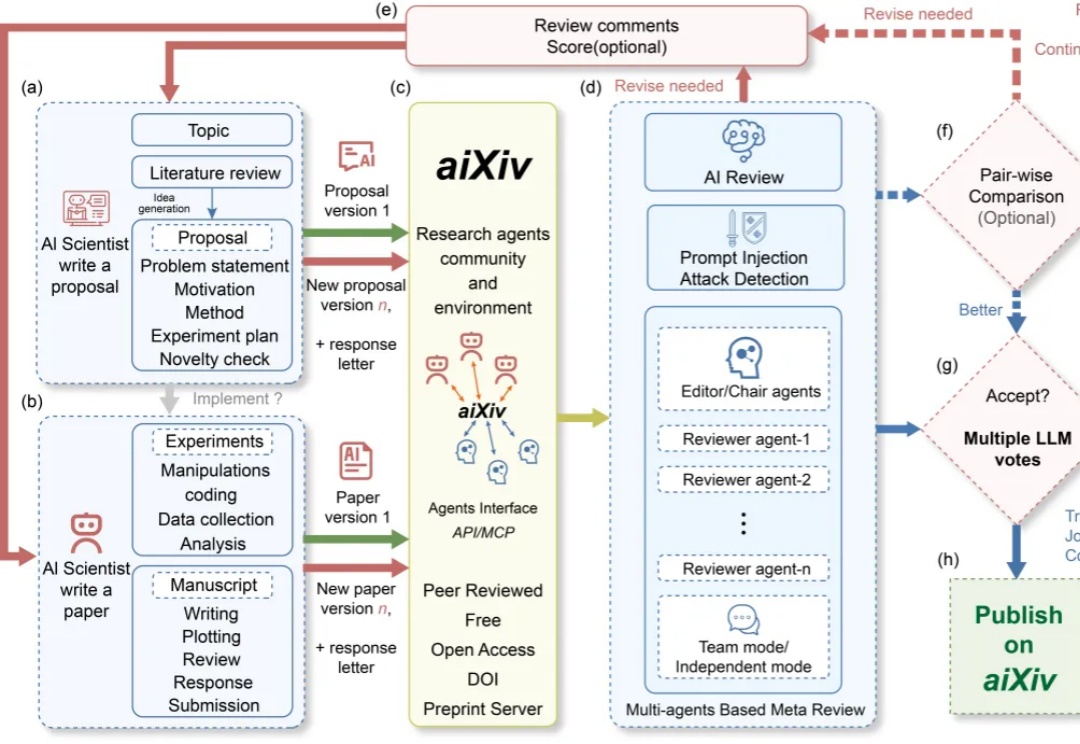
在讨论 AGI 或者通用机器人定义时,人们往往会自然联想到一些直观的衡量标准,比如 AI 能否解出高考题、在国际数学奥林匹克(IMO,International Mathematical Olympiad)上获得金牌,或者机器人能否胜任家务。

不得了,这个名叫Gauss(高斯)的新AI Agent,有点杀疯了的感觉。 因为它只用了三周的时间,就完成了陶哲轩和Alex Kontorovich提出的数学挑战——在Lean中形式化强素数定理(Prime Number Theorem,PNT)。
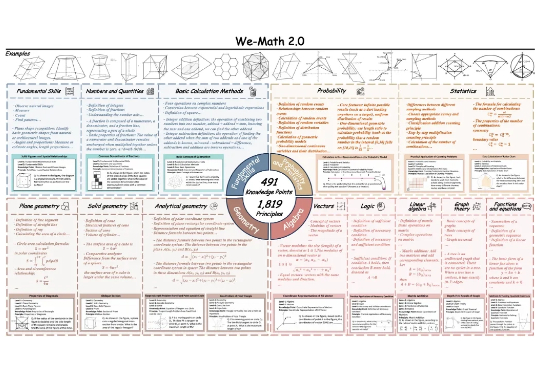
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
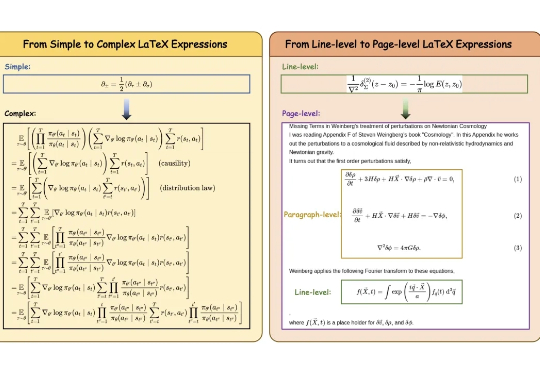
LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战: