
AI模型守法率提升11%,港科大首次用法案构建安全benchmark
AI模型守法率提升11%,港科大首次用法案构建安全benchmark香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。
来自主题: AI技术研报
10016 点击 2025-10-23 12:20
 搜索
搜索
香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。

这世上有太多 AI benchmark 了,但没有一个 benchmark 能让你心跳加速。 直到近日,AlphaArena 出现了。 这是由初创团队 NOF1 推出的一个「AI 炒币实盘竞技场」,现在已开放全网围观:竞技场地址:https://nof1.ai/

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。

Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。

近日,全球权威咨询机构IDC发布《IDC MarketScape: 中国工业大模型及智能体解决方案 2025年厂商评估》。报告选取了中国市场18家工业大模型及智能体解决方案的典型服务商进行重点研究,从现有能力和未来战略两个层面对厂商进行评估,为工业企业选择大模型、智能体服务提供了参考。

采访时间不到1小时,信息密度却堪称爆炸! OpenAI首席科学家Jakub Pachocki和首席研究官Mark Chen开启同台爆料模式:氛围编码的下一步或许是氛围研究(Vibe Researching);
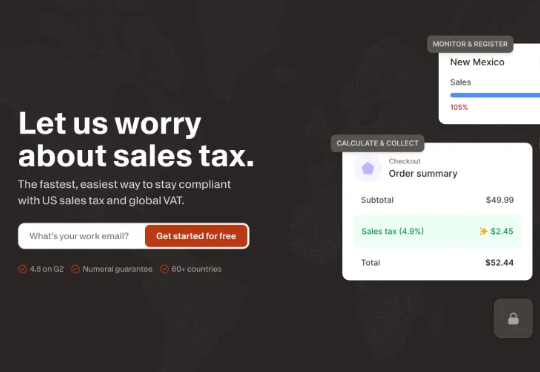
最近,一家叫 Numeral 的公司刚刚完成了 3500 万美元的 B 轮融资,由 Mayfield 领投,Benchmark、Uncork Capital、Y Combinator 和 Mantis 参与。这轮融资距离他们今年 3 月完成的 1800 万美元 A 轮仅仅过去了 6 个月,公司估值已经达到 3.5 亿美元。
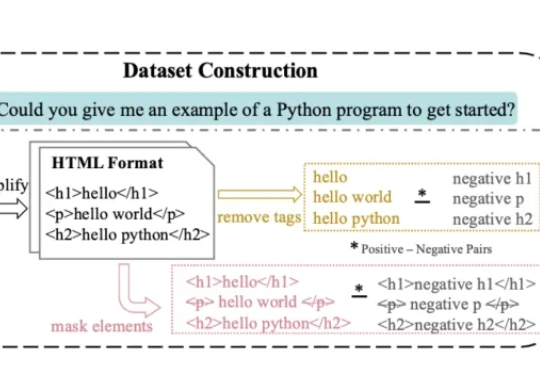
AI读不懂HTML、Markdown长文档的标题和结构,找信息总踩坑?解决方案来了——SEAL全新对比学习框架通过带结构感知+元素对齐,让模型更懂长文。
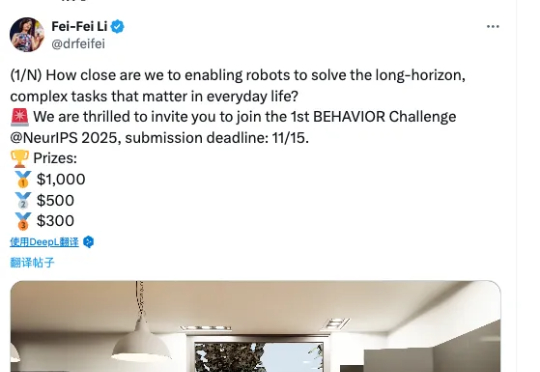
答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。

当Mark Lee 还在哈佛法学院就读时,一门商标法课程让他见识到仿冒产业的惊人规模——这个非法产业年产值超过 3 万亿美元。Sequoia Capital(红杉资本)前亚洲分支机构正在投资一家鲜为人知的初创公司——Marq Vision ,该公司致力于追踪并帮助下架未经授权的 AI 芯片、药品、游戏和奢侈品销售列表。