
苹果 AI 硬件三件套曝光,iPhone 将迎来史诗级加强
苹果 AI 硬件三件套曝光,iPhone 将迎来史诗级加强据彭博社记者 Mark Gurman 爆料,苹果正在加速推进三款全新的 AI 可穿戴设备。这三款产品都将围绕 Siri 数字助手构建,通过摄像头获取视觉上下文来执行各种操作。
来自主题: AI资讯
11147 点击 2026-02-18 13:37
 搜索
搜索
据彭博社记者 Mark Gurman 爆料,苹果正在加速推进三款全新的 AI 可穿戴设备。这三款产品都将围绕 Siri 数字助手构建,通过摄像头获取视觉上下文来执行各种操作。

Cloudflare 宣布推出 Markdown for Agents。只要在 Agent 的请求设置里头加上一句——Accept: text/markdown。网站就会自动返回为 Agent 识别优化的 Markdown 文件,而不是为人类准备的 HTML 文件。

绷不住了!OpenAI深陷高管离职潮,内部“红色警报”再次拉响。

百川智能表示今年上半年,将陆续发布两款 to C 的医疗产品。 作者|Li Yuan 编辑|郑玄 你有没有向 AI 助手问过你的健康问题? 如果你和我一样是一个 AI 的深度用户,大概率你也试过。 O

在文章开始前,请您先打开Claude code,输入/skill,检查一下您的Claude code有多少个skills?是20个?50个?还是已经突破了100个?自从Anthropic推广Agent Skills以来,我们都爱上了这种“即插即用”的模块化体验。它把臃肿的多智能体编排(MAS)变成了一组优雅的Markdown文件调用,让API账单和延迟同时暴跌了50%以上。
今天在X上读到了一个极具启发的Claude Code使用案例。 说起来,我写过很多Claude Code的经验分享了。我现在频繁用它写代码、写文章、分析股票,最近还在尝试用它做Polymarket的预
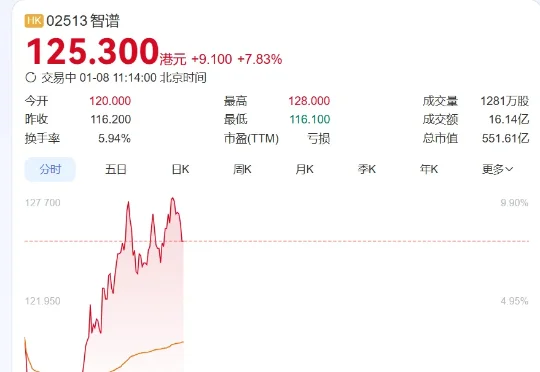
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”
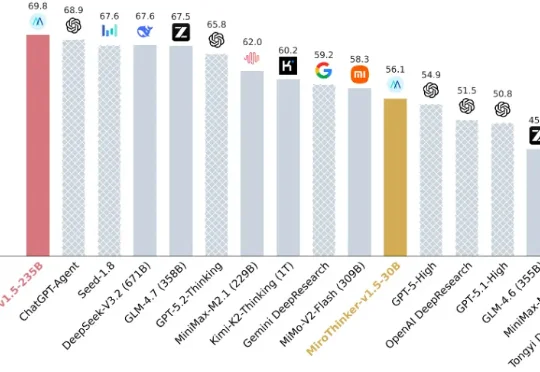
凭借成功预测 Polymarket 题目,连续登顶 Future X 全球榜首的 MiroMind 团队,于今日(1 月 5 日)正式发布其自研旗舰搜索智能体模型 MiroThinker 1.5。MiroThinker-v1.5-30B 仅用 1/30 的参数规模跑出了比肩众多 1T 模型的性能表现,其 235B 的版本在多个搜索智能体基准测试中跻身全球第一梯队。
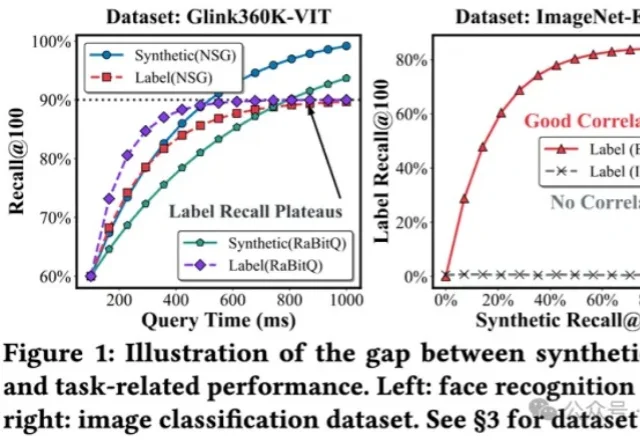
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

年少有为、雄心勃勃的创业者早已不是新鲜事。Bill Gates 19 岁时联合创办了微软;Mark Zuckerberg 也是在 19 岁那年创立了 Facebook。但如今的创业者,年龄更小了,可能还只是个拿着学车许可证、戴着牙套的孩子。