
3天把Llama训成Mamba,性能不降,推理更快!
3天把Llama训成Mamba,性能不降,推理更快!近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。
来自主题: AI技术研报
9365 点击 2024-09-05 15:31
 搜索
搜索
近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

Jamba是第一个基于 Mamba 架构的生产级模型。Mamba 是由卡内基梅隆大学和普林斯顿大学的研究人员提出的新架构,被视为 Transformer 架构的有力挑战者。
Attention is all you need.
Mamba 虽好,但发展尚早。

Mamba 架构的大模型又一次向 Transformer 发起了挑战

TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。
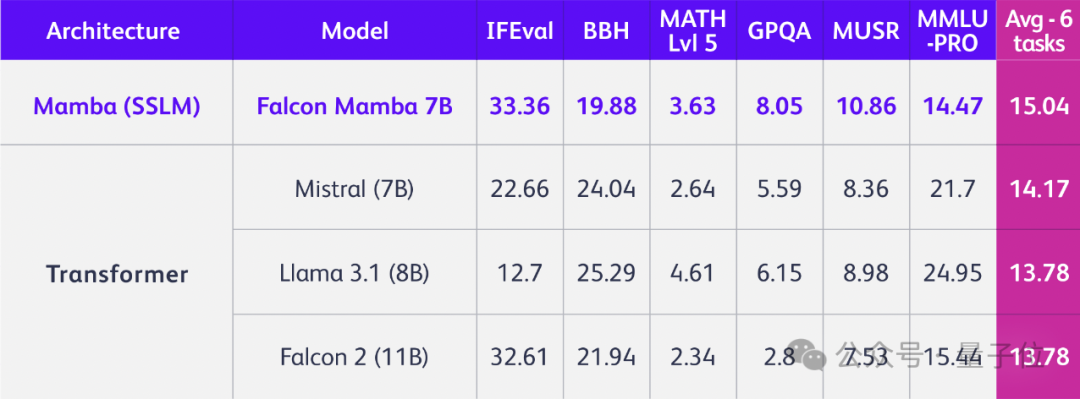
只是换掉Transformer架构,立马性能全方位提升,问鼎同规模开源模型!
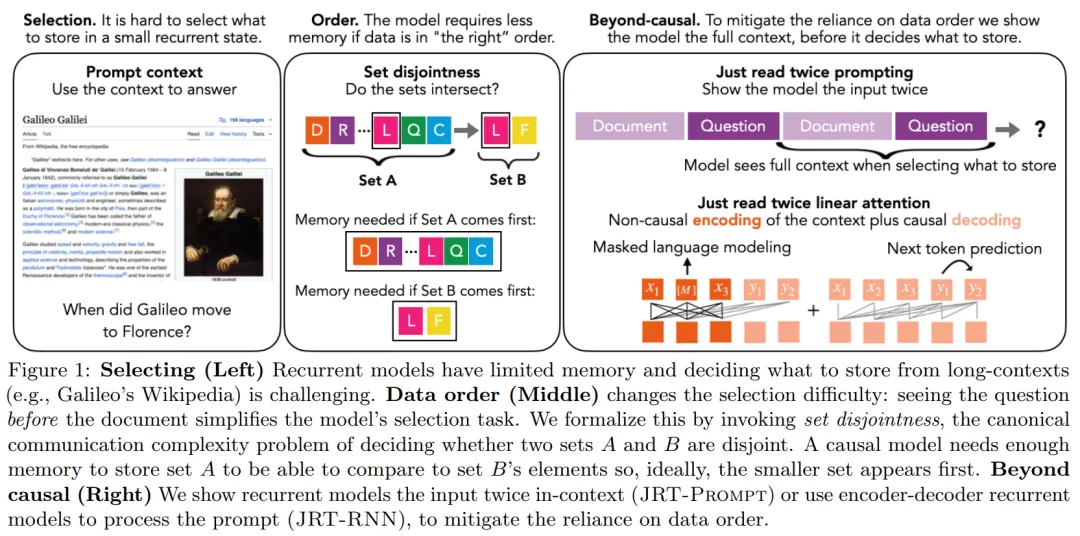
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。
这几日,AI 圈又一“震惊”事件!!