
Seedance 2.0让字节元神启动
Seedance 2.0让字节元神启动Seedance 2.0用了两天,个人感想是,以下几类人群或即将失业:一、把「学好提示词」奉为圭臬,并开班传授佶屈聱牙反逻辑长难句prompt的AI导师。二、成本只有一个自拍杆的所谓短视频博主。三、刚开始做AI社交的小创业者。
来自主题: AI产品测评
9898 点击 2026-02-11 12:38
 搜索
搜索
Seedance 2.0用了两天,个人感想是,以下几类人群或即将失业:一、把「学好提示词」奉为圭臬,并开班传授佶屈聱牙反逻辑长难句prompt的AI导师。二、成本只有一个自拍杆的所谓短视频博主。三、刚开始做AI社交的小创业者。

初创公司 Xmax AI 推出的首个虚实融合的实时交互视频模型 X1,没有复杂的 Prompt,不需要漫长的渲染等待,只需要手势进行交互,就可以让虚拟世界与现实相连,在镜头中令「幻想」成真,让用户体验到实时交互的心流体验。

我们都在System Prompt里写过无数次 You are a helpful assistant,但你是否想过:这行文字在模型的残差流(Residual Stream)中究竟对应着怎样的几何结构?
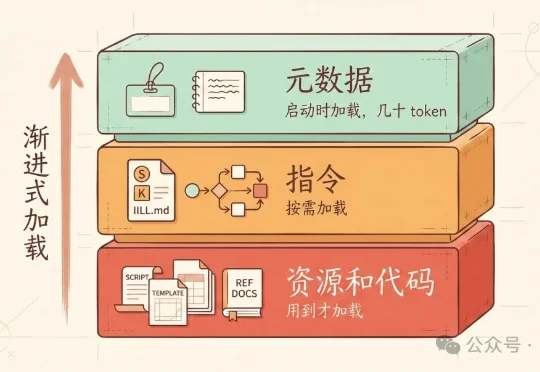
上篇文章别把整个 GitHub 装进 Skills,Skills 的正确用法发出去后,收到一些质疑:“说 skill 能做配图 prompt 不行。本来 skill 就是加载 md,没 skill 之前我们用 prompt 模板照样也是能做流程编排。” “现在大部分 skill 不就是长一点的提示词吗?为什么说'单纯靠提示词做不了'?”
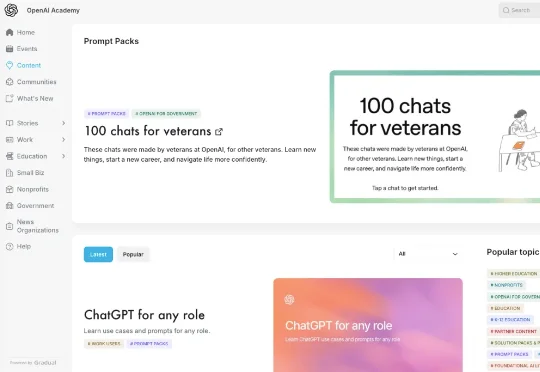
就在最近,OpenAI 终于把"丹炉"和"配方"都端出来了。OpenAI Academy 悄悄上线了一个名为 Prompt Packs(提示词包) 的资源库。
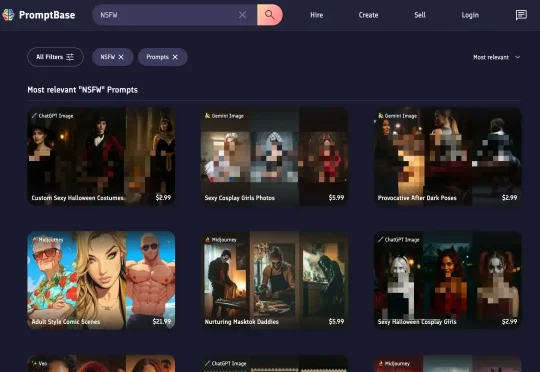
比如说,最近有一个叫做 Unlucid.ai 的视频生成网站流量很好,排名窜的很快,在这个网站主页里,你能看到非常「像片儿」的 AI 生成视频:有人反复试错,研究哪些描述可以通过,哪些词语组合更容易出结果,怎样的写法既不触发拦截,又能让画面往“成人内容”的方向靠近。
项目缘起:从 0 到 1 的 PromptTuner 诞生之路 随着大模型技术的普及,AI 交互已成为日常工作的重要组成部分。然而,如何写出高质量的提示词(Prompt)却成为普通用户面临的新挑战。
新年第一天,DeepSeek 发布了一篇艰深晦涩的技术论文,不少网友直呼「看不懂」。

最近,一个澳大利亚的养羊大叔用5行代码捅破AI编程天花板的故事,彻底火出圈了。2025年底,在铲羊粪的间隙,Geoffrey Huntley写出了下面这个仅含5行代码的Bash脚本while :; do cat PROMPT.md | claude-code ; done

已经2026年了,其实还是看到很多朋友,说不知道怎么能更好的跟AI对话。