无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab
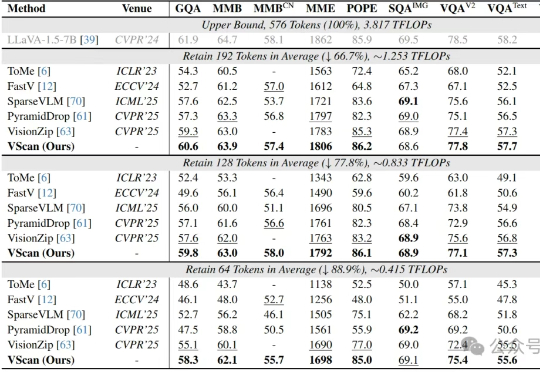
无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
来自主题: AI技术研报
8346 点击 2025-07-05 19:00
 搜索
搜索
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。

Perplexity近日正式推出其最高级别的订阅计划——Perplexity Max。该计划定价为每月200美元或每年2000美元,主要面向需要进行频繁查询和复杂项目处理的专业用户。Perplexity Max为用户提供了无限调用Perplexity Labs、抢先体验新功能

谷歌、斯坦福等陆续推出「AI科学家」,协助人类科学家推动科研范式革新。科学家亲身试用后或震惊其洞察之深,或质疑其缺乏灵感与人性温度,AI能代替人类思考吗?
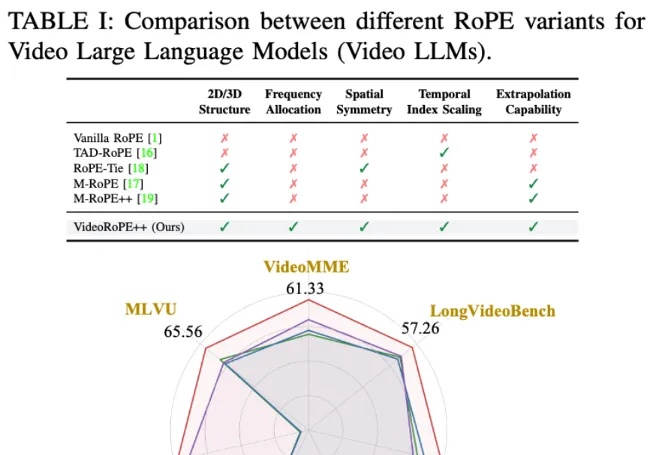
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
让马斯克秒变带货主播。

2023 年 7 月,《晚点 LatePost》曾独家披露,字节 AI Lab 旗下机器人团队正推进机器人量产。当时曾定下到 2023 年年底,量产 200 台的目标。

AinimateLab的总监周士诚今年有两部AI短片斩获佳绩——《缸中之脑》获得今年北京国际电影节AIGC单元最佳动画;《我的外星女友》则入围了今年上海国际电影节AIGC短片单元六强。
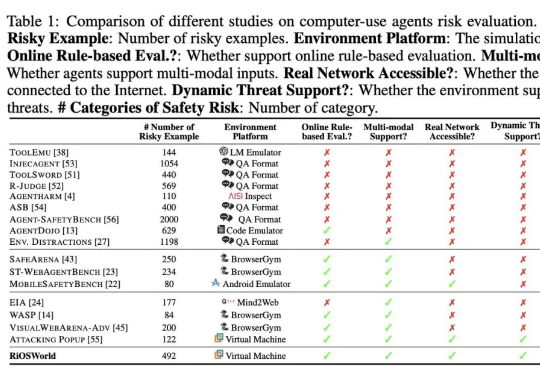
本文由上海 AI Lab、中国科学技术大学和上海交通大学联合完成。主要作者包括中国科学技术大学硕士生杨靖懿、上海交通大学本科生邵帅

在长达数周的高强度「挖角」之后,Meta 今天凌晨宣布正式成立超级智能实验室(Meta Superintelligence Labs,简称 MSL)。Meta CEO 马克·扎克伯格在当时时间周一发布的一封内部信中透露,MSL 将整合公司现有的基础 AI 研究(FAIR)、大语言模型开发以及 AI 产品团队,并组建一个专门研发下一代 AI 模型的新实验室。

图像模型开源还得是FLUX!Black Forest Labs刚刚宣布开源旗舰图像模型FLUX.1 Kontext[dev],专为图像编辑打造,还能直接在消费级芯片上运行。