来自MIT的最新研究-RL's Razor|展望LLMs Post-Training下的前沿探索与思考
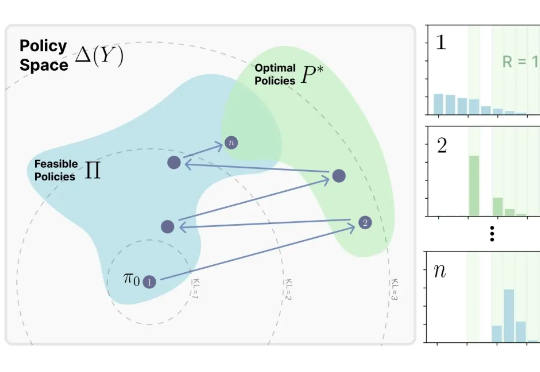
来自MIT的最新研究-RL's Razor|展望LLMs Post-Training下的前沿探索与思考来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。
来自主题: AI技术研报
8021 点击 2025-09-18 14:26