
用LLaVA解读数万神经元,大模型竟然自己打开了多模态智能黑盒
用LLaVA解读数万神经元,大模型竟然自己打开了多模态智能黑盒以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
来自主题: AI技术研报
8159 点击 2024-12-07 15:02
 搜索
搜索
以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
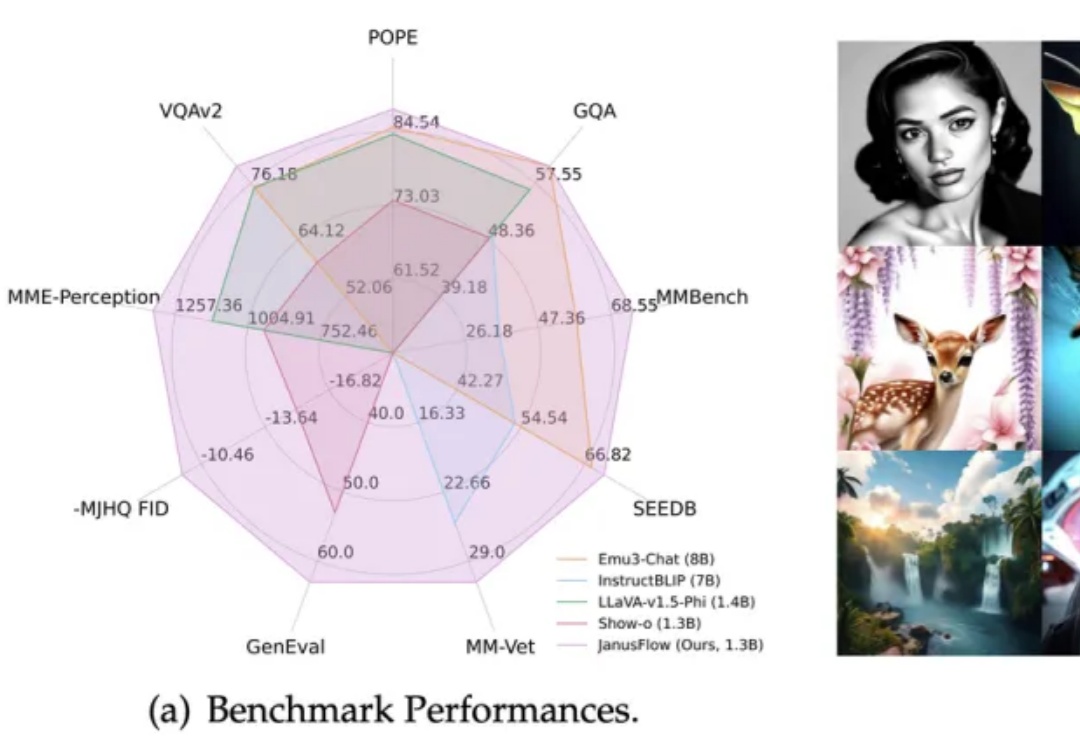
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
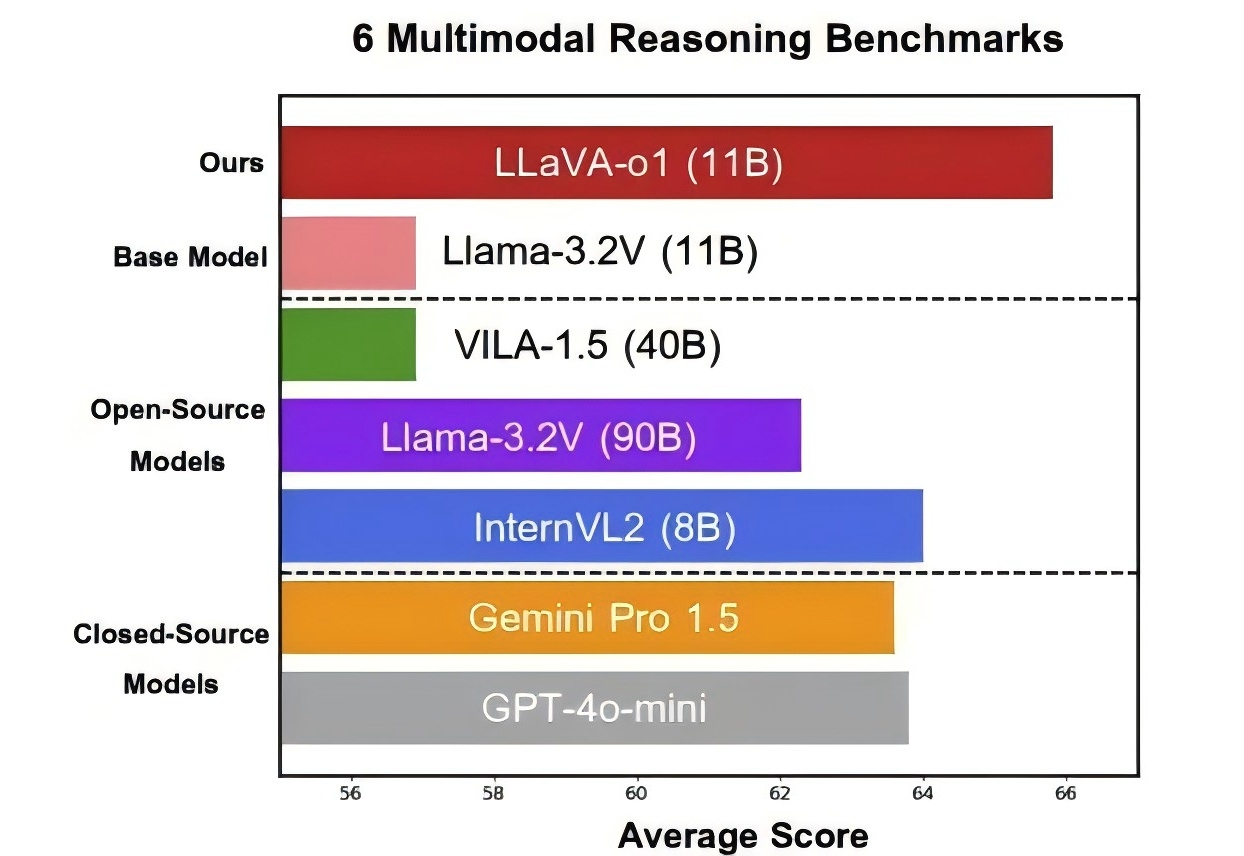
北大等出品,首个多模态版o1开源模型来了—— 代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。

自从 Sora 发布以来,AI 视频生成领域变得更加「热闹」了起来。过去几个月,我们见证了即梦、Runway Gen-3、Luma AI、快手可灵轮番炸场。

TinyLLaVA 项目由清华大学电子系多媒体信号与智能信息处理实验室 (MSIIP) 吴及教授团队和北京航空航天大学人工智能学院黄雷老师团队联袂打造。清华大学 MSIIP 实验室长期致力于智慧医疗、自然语言处理与知识发现、多模态等研究领域。北航团队长期致力于深度学习、多模态、计算机视觉等研究领域。