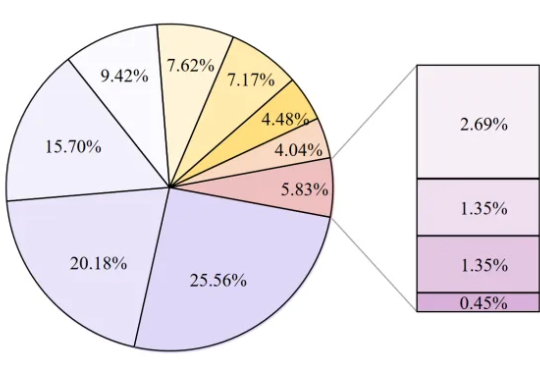
北大发布学术搜索评测ScholarSearch:难倒一众DeepResearch的“开卷考试”
北大发布学术搜索评测ScholarSearch:难倒一众DeepResearch的“开卷考试”LLMs能当科研助手了? 北大出考题,结果显示:现有模型都不能胜任。
来自主题: AI技术研报
10548 点击 2025-06-27 10:06
 搜索
搜索
LLMs能当科研助手了? 北大出考题,结果显示:现有模型都不能胜任。
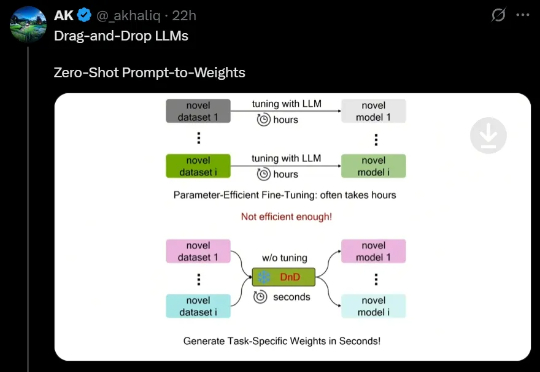
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。
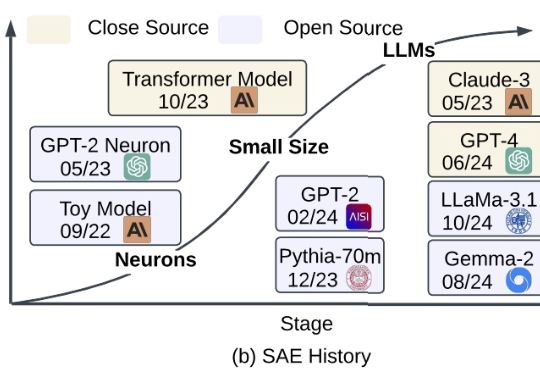
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,

通过这份全面指南探索大语言模型(LLMs)的关键概念、技术和挑战,专为AI爱好者和准备面试的专业人士精心打造。
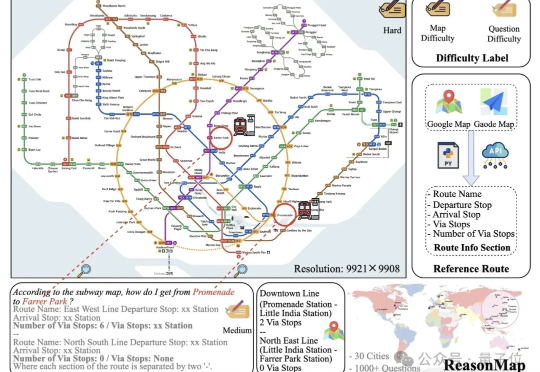
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
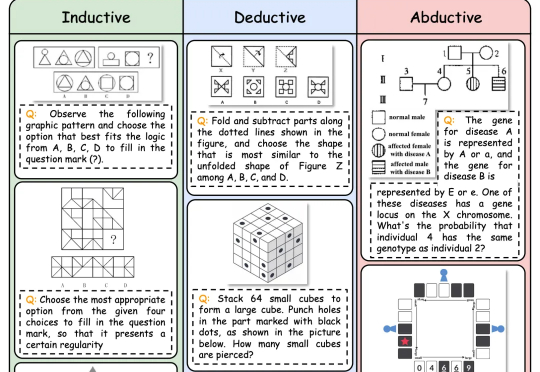
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)