破解多模态大模型“选择困难症”!内部决策机制首次揭秘:在冲突信息间疯狂"振荡"
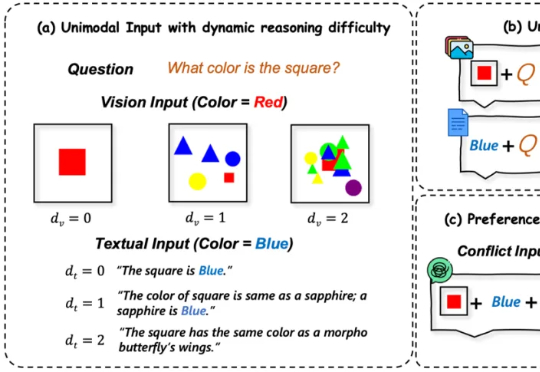
破解多模态大模型“选择困难症”!内部决策机制首次揭秘:在冲突信息间疯狂"振荡"多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
来自主题: AI技术研报
8825 点击 2025-11-14 13:54