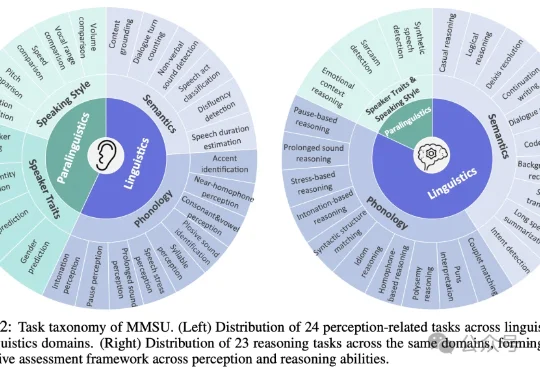
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
来自主题: AI技术研报
10830 点击 2026-02-24 15:35
 搜索
搜索
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
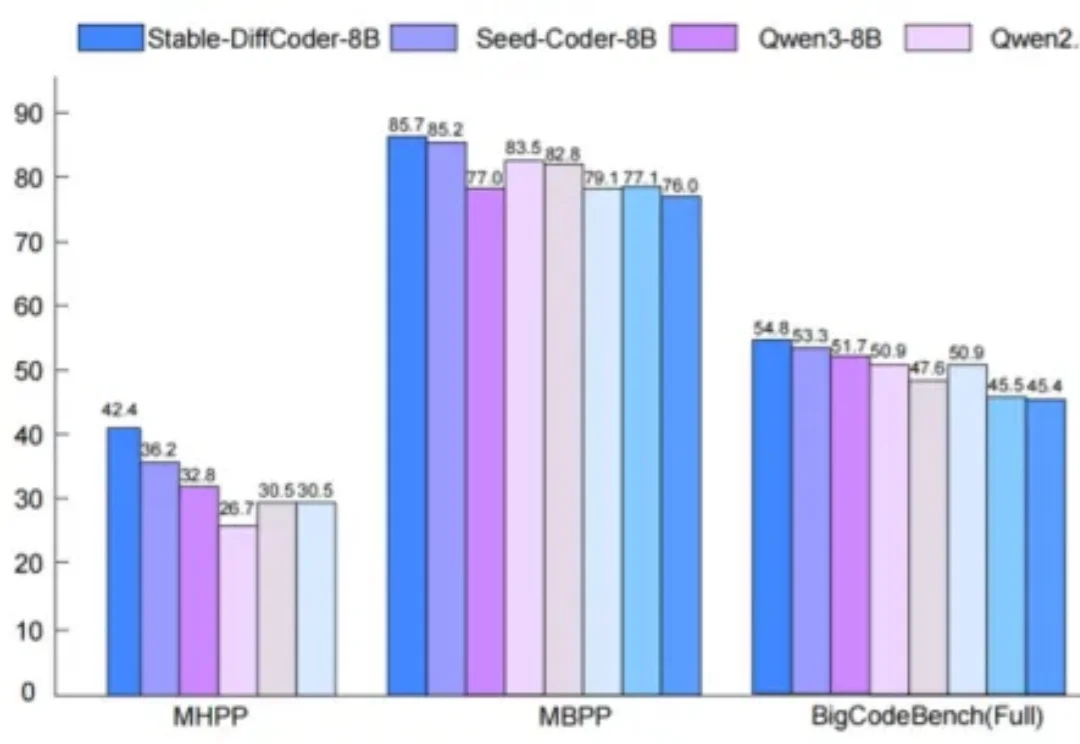
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
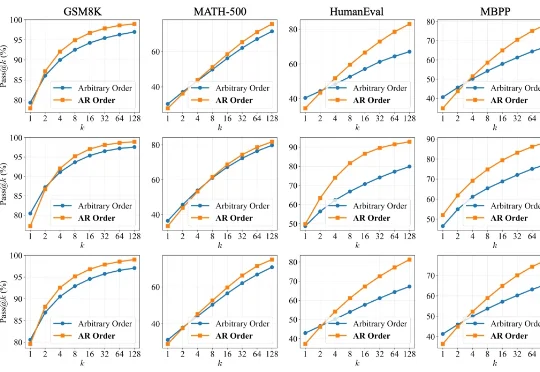
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
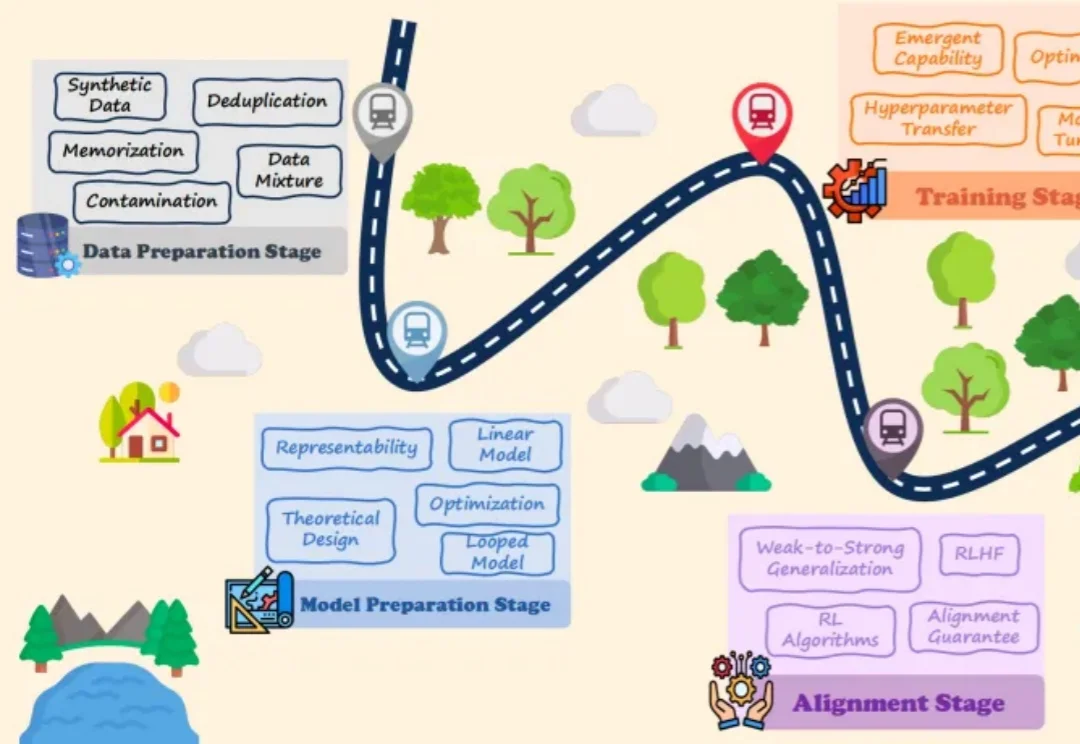
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。

最近,一篇由中国团队领衔全球24所TOP高校机构发布,用于评测LLMs for Science能力高低的论文,在外网炸了!当晚,Keras (最高效易用的深度学习框架之一)缔造者François Chollet转发论文链接,并喊出:「我们迫切需要新思路来推动人工智能走向科学创新。」
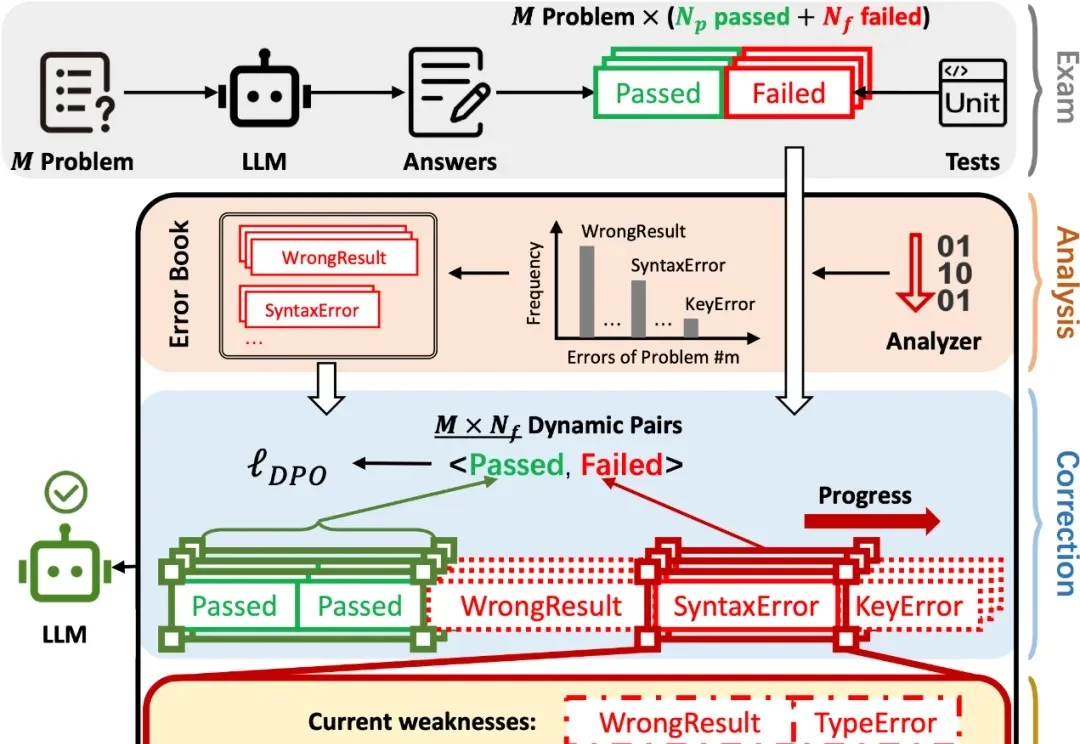
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
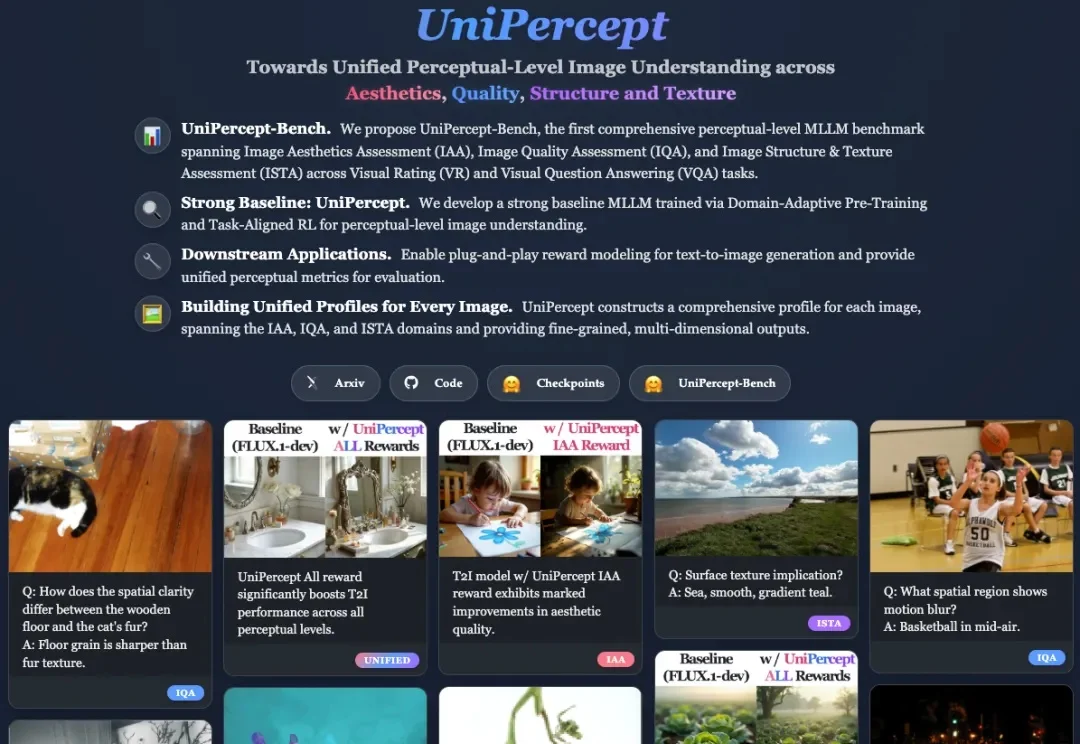
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
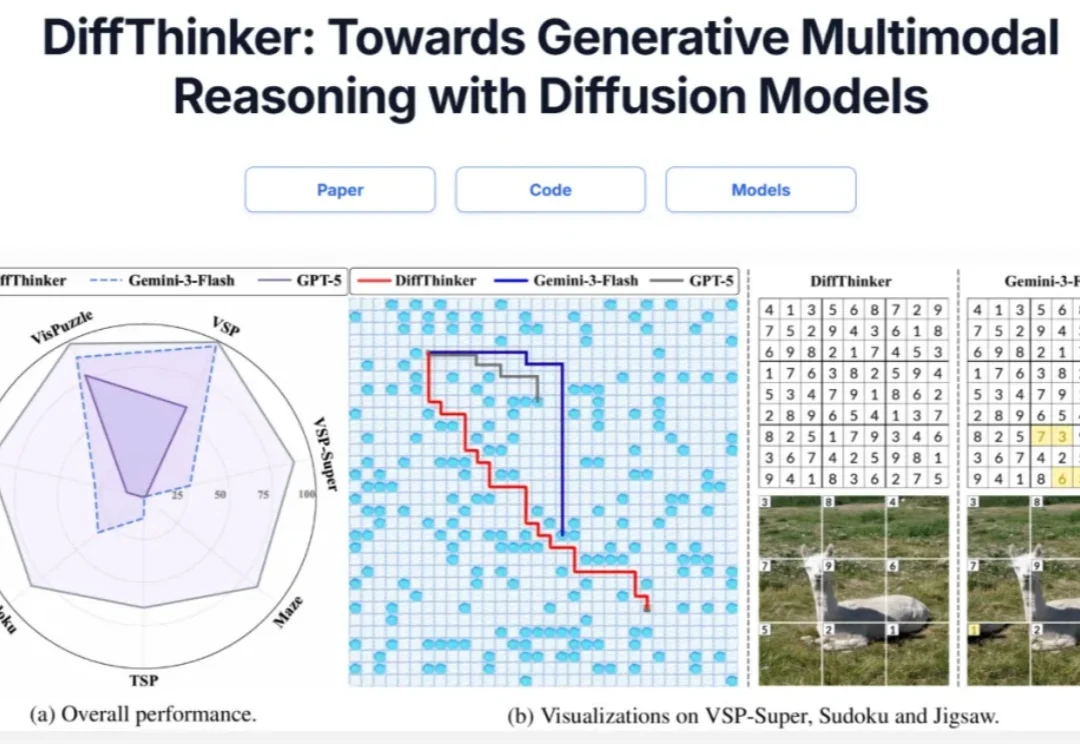
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。