
PyTorch官宣:告别CUDA,GPU推理迎来Triton加速新时代
PyTorch官宣:告别CUDA,GPU推理迎来Triton加速新时代用英伟达的GPU,但可以不用CUDA?PyTorch官宣,借助OpenAI开发的Triton语言编写内核来加速LLM推理,可以实现和CUDA类似甚至更佳的性能。
来自主题: AI技术研报
6185 点击 2024-09-07 11:26
 搜索
搜索
用英伟达的GPU,但可以不用CUDA?PyTorch官宣,借助OpenAI开发的Triton语言编写内核来加速LLM推理,可以实现和CUDA类似甚至更佳的性能。

本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天内在 github 上斩获 1000+ 星标。

头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。
我个人不是喜欢打听这些公司八卦的人,前些年移动互联网时代就已经有太多这样的小道消息,但最终都没有没什么用。重要的信息迟早会变成公开,最多晚几个月而已,又不是要考虑抢时间窗口投这些公司,花时间去探究ROI不高。
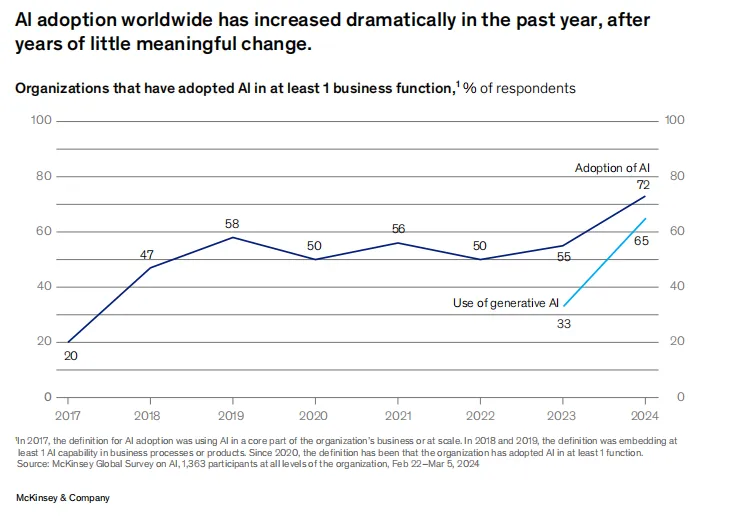
企业要用好 LLM 离不开高质量数据。和传统机器学习模型相比,LLM 对于数据需求量更大、要求更高,尤其是非结构化数据。而传统 ETL 工具并不擅长非结构化数据的处理,因此,企业在部署 LLM 的过程中,数据科学家们往往要耗费大量的时间精力在数据处理环节。这一环节既关系到 LLM 部署的效率和质量,也对数据科学家人力的 ROI 产生影响。

内含一键部署教程

近日,清华大学电子系城市科学与计算研究中心的研究论文《EconAgent: Large Language Model-Empowered Agents for Simulating Macroeconomic Activities》获得自然语言处理顶会 ACL 2024杰出论文奖(Outstanding Paper Award)。

知识管理软件,也上大模型了。
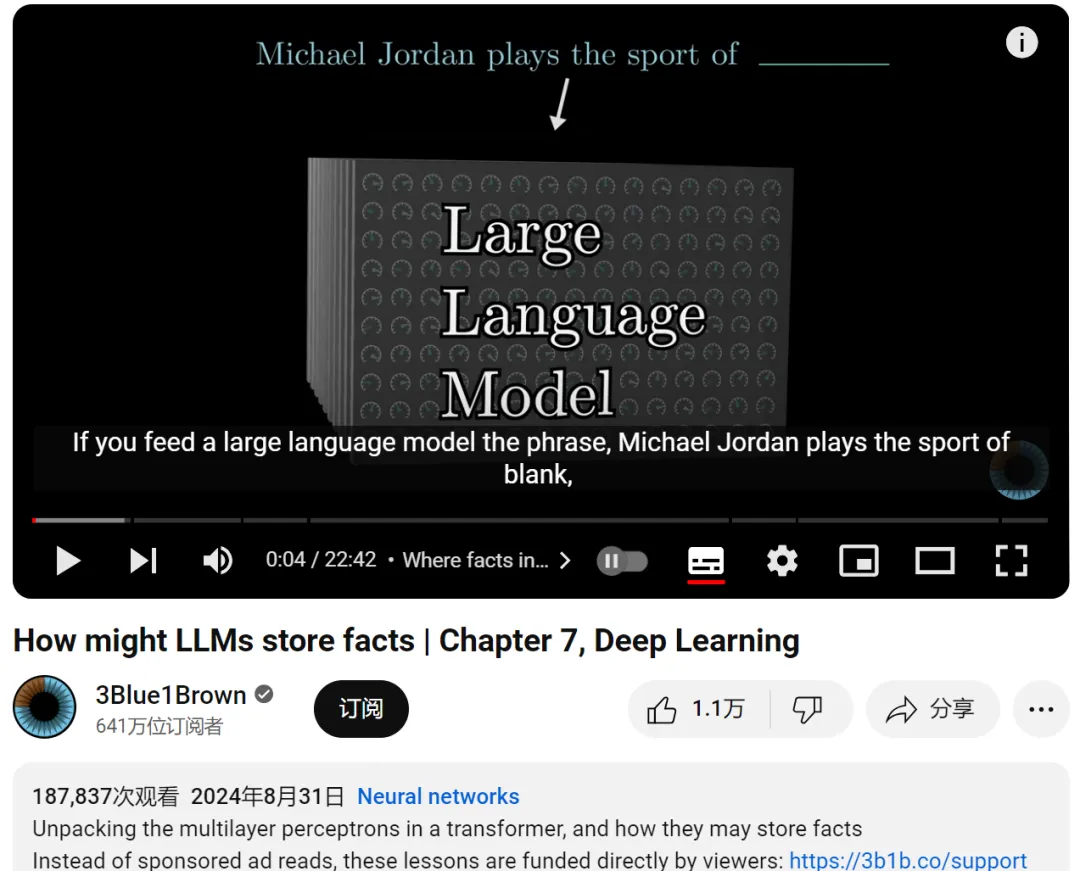
向大模型输入「Michael Jordan plays the sport of _____(迈克尔・乔丹从事的体育运动是……)」,然后让其预测接下来的文本,那么大模型多半能正确预测接下来是「basketball(篮球)」。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。