
调研180多篇论文,这篇综述终于把大模型做算法设计理清了
调研180多篇论文,这篇综述终于把大模型做算法设计理清了算法设计(AD)对于各个领域的问题求解至关重要。大语言模型(LLMs)的出现显著增强了算法设计的自动化和创新,提供了新的视角和有效的解决方案。
来自主题: AI技术研报
4790 点击 2024-11-06 15:29
 搜索
搜索
算法设计(AD)对于各个领域的问题求解至关重要。大语言模型(LLMs)的出现显著增强了算法设计的自动化和创新,提供了新的视角和有效的解决方案。
Ichigo[1] 是一个开放的、持续进行的研究项目,目标是将基于文本的大型语言模型(LLM)扩展,使其具备原生的“听力”能力。
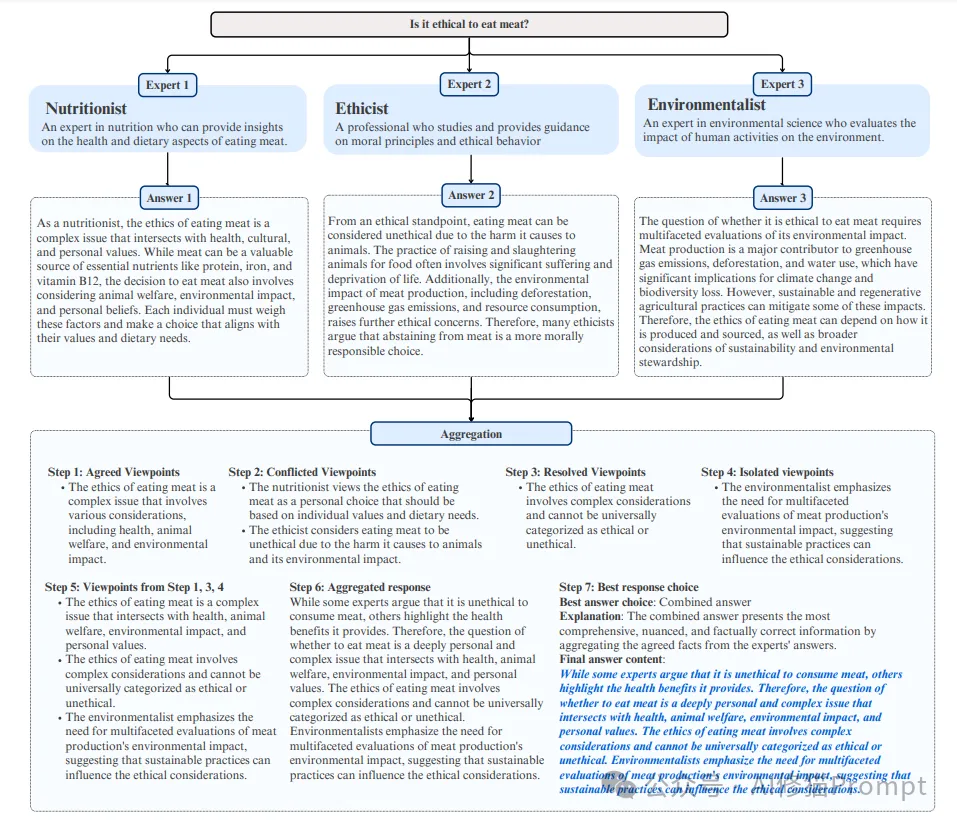
在当前的LLM应用开发中,工程师们通常通过使用单一角色或专家视角的方式来处理复杂问题。这种单一视角虽然能够提供一定的专业性,但也经常因为专家视角的局限性带来偏见,影响输出的全面性和可靠性。
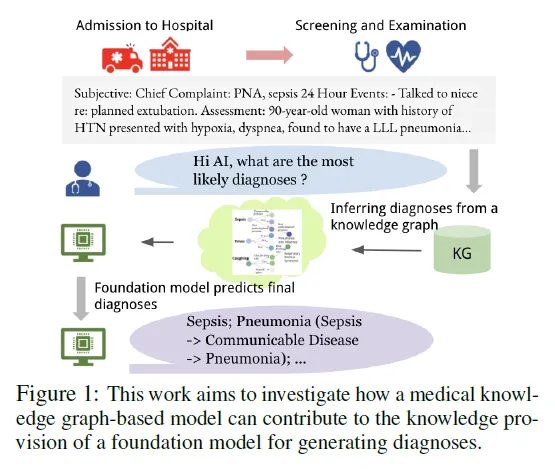
近年来,生成式大型语言模型(LLMs)在各类语言任务中的表现令人瞩目,但在医疗领域的应用面临诸多挑战,尤其是在减少诊断错误和避免对患者造成伤害方面。
让 LLM 在自我进化时也能保持对齐。

斯坦福大学奥马尔(Omar)的DSPy研究团队最近更新了他们的项目文档,发了很多不错的案例,以及很多国际知名企业的DSPy用例,这些可能对您的项目有启发。

AI,LLM,模型训练,人工智能

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。
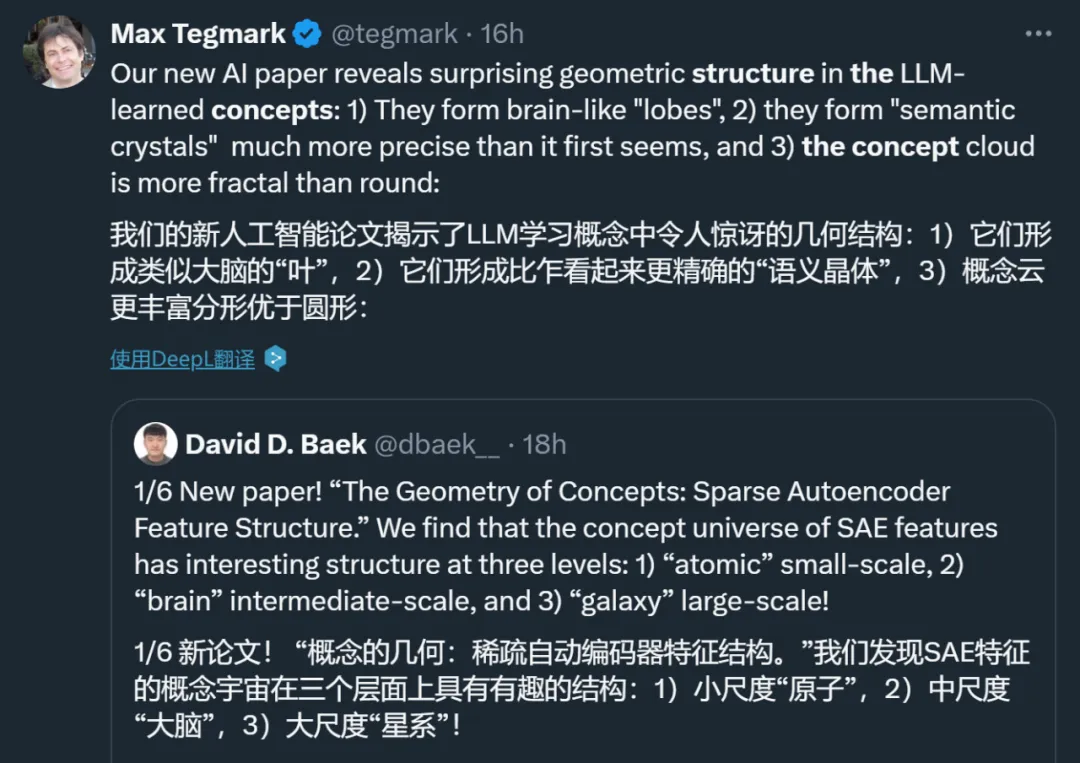
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?

Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。