
这篇综述,LLM代理的方法、应用和挑战,2025的Agent势头特别猛。| 重磅
这篇综述,LLM代理的方法、应用和挑战,2025的Agent势头特别猛。| 重磅2025年,人工智能领域正在经历一场由LLM Agent引发的深刻变革,不管普通人的衣食住行还是研究者的尖端研究,都很难不受Agent的影响。
来自主题: AI技术研报
12573 点击 2025-04-01 10:06
 搜索
搜索
2025年,人工智能领域正在经历一场由LLM Agent引发的深刻变革,不管普通人的衣食住行还是研究者的尖端研究,都很难不受Agent的影响。

你是否曾对着一个繁复的AI框架,无奈地想:"真有必要搞得这么复杂吗?"在与臃肿框架斗争一年后,Zachary Huang博士决定大刀阔斧地革新,剔除所有花里胡哨的部分。于是Pocket Flow诞生了——一个仅有100行代码的超轻量级大语言模型框架!
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。
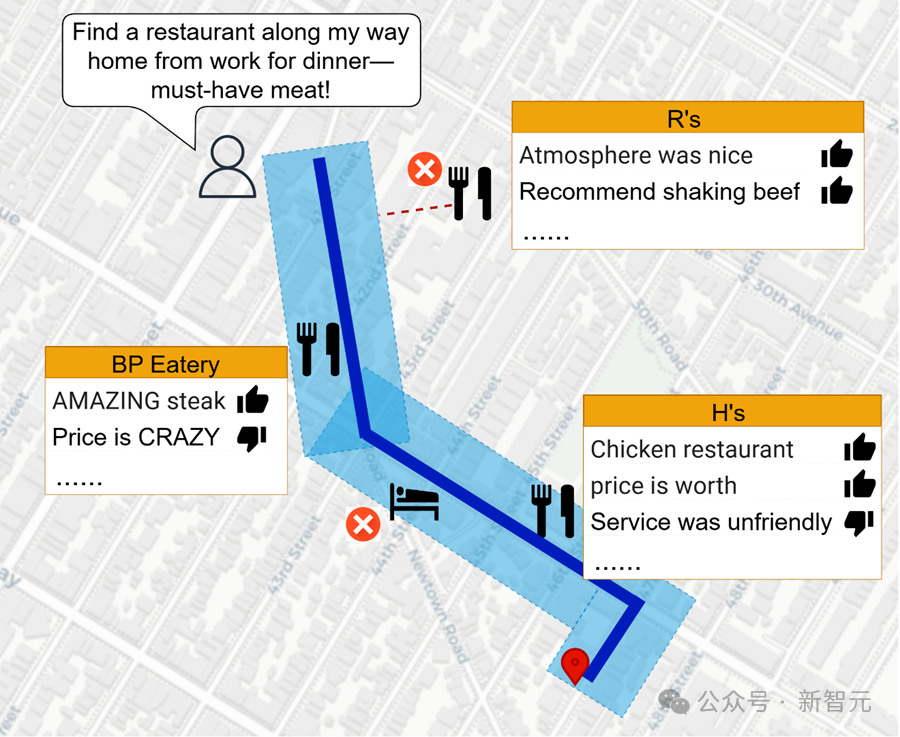
Spatial-RAG结合了空间数据库和大型语言模型(LLM)的能力,能够处理复杂的空间推理问题。通过稀疏和密集检索相结合的方式,Spatial-RAG可以高效地从空间数据库中检索出满足用户查询的空间对象,并利用LLM的语义理解能力对这些对象进行排序和生成最终答案。

强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。
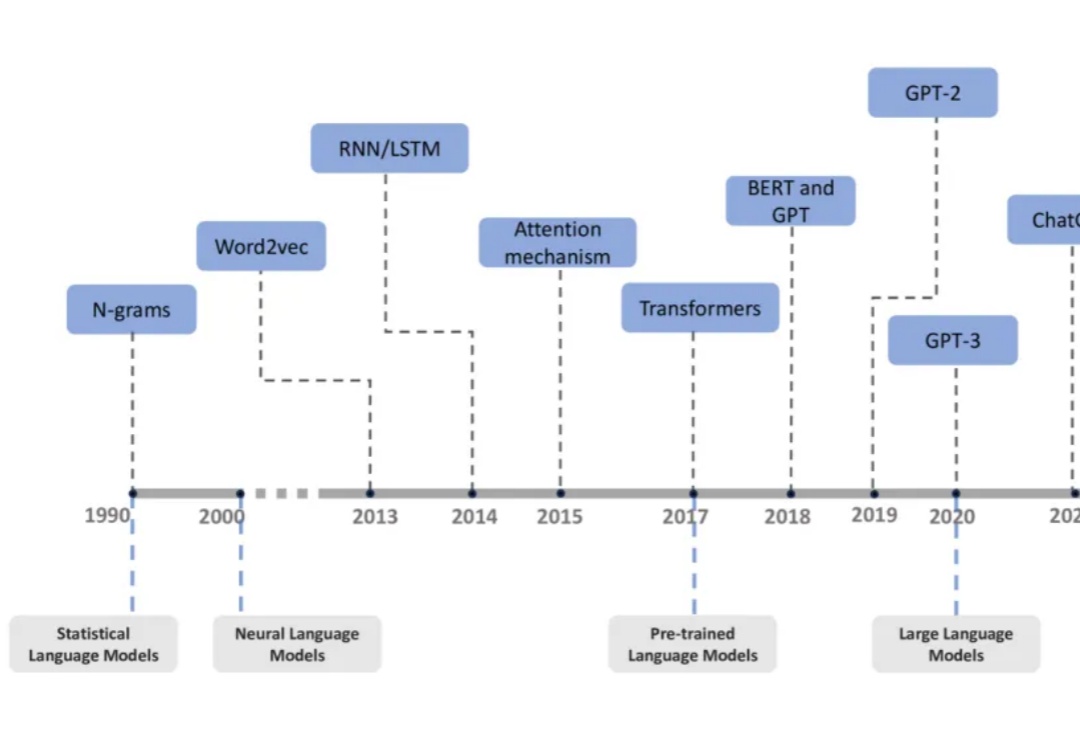
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。
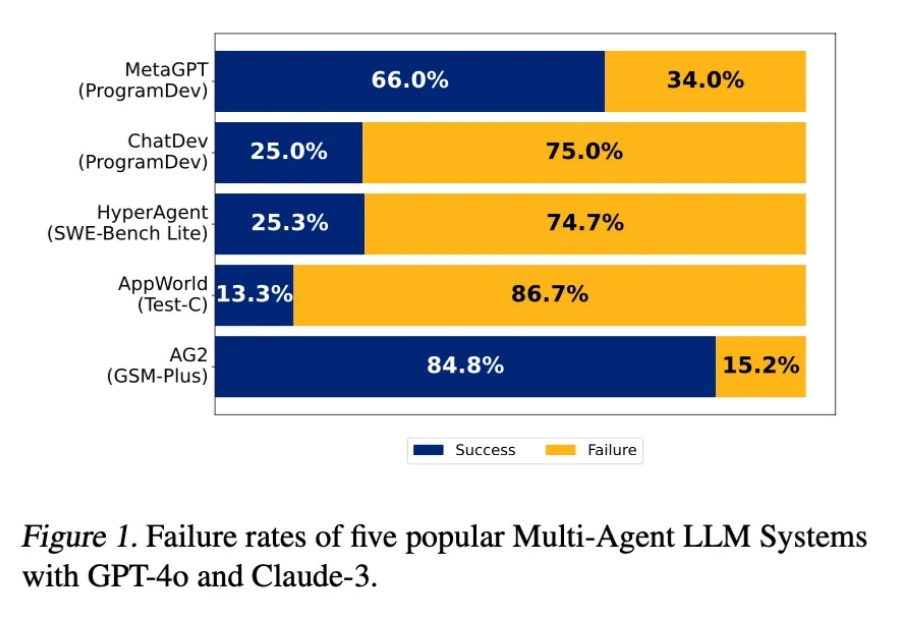
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。

今天字节暴了一个八卦,豆包LLM技术负责人乔某婚内出轨HRBP程某某,还不给原配自己亲女儿抚养费。据说乔某已经结婚11年了,2014年进入字节,有两个女儿,而程之前还和乔下属谈过恋爱,也知道他有妻子,知三当三啊,有人还说乔还公款带着程一起去美国出差。
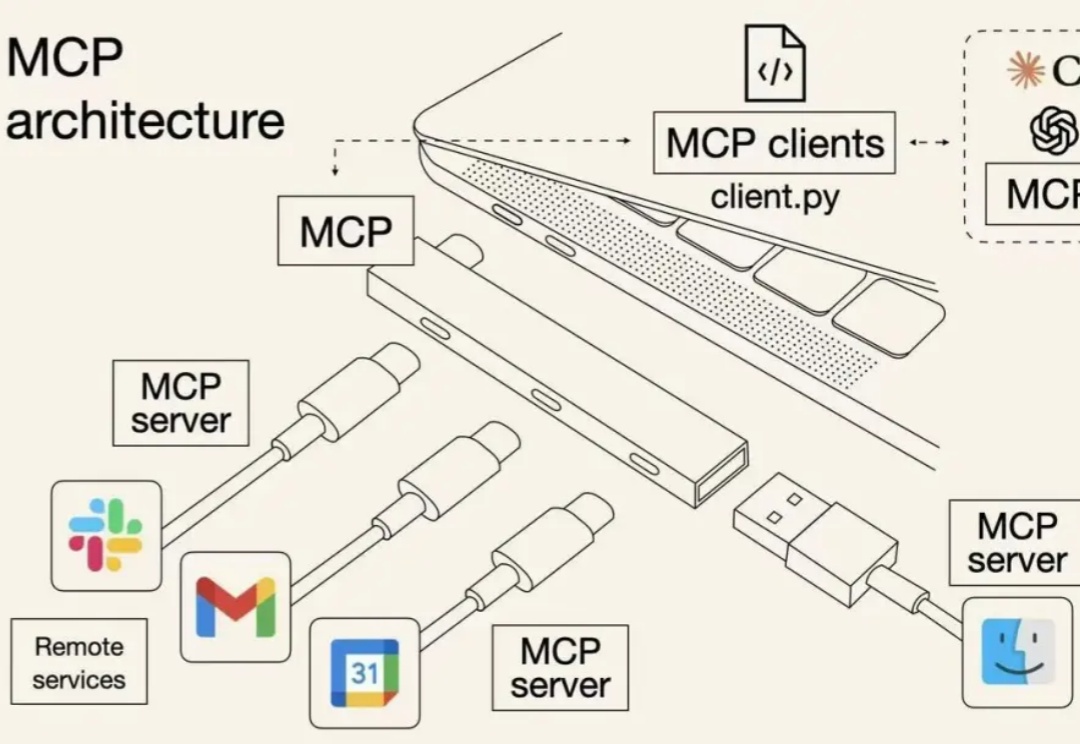
在拾象团队的 2025 的 AI 关键预测中,我们提到:随着 Agent 时代到来,OS 才是 LLM 厂商们最高的护城河,从 computer use 到 MCP,Anthropic 构建 OS 的决心是 AI labs 中最强、最明显的。

AI界「智商大考」ARC-AGI-2重磅出炉了!一个人类用5分钟轻松解开的谜题,却让最顶尖LLM全线崩盘得分挂零,o3更是从曾经76%暴跌至4%。它正式宣告,人类还未实现AGI。