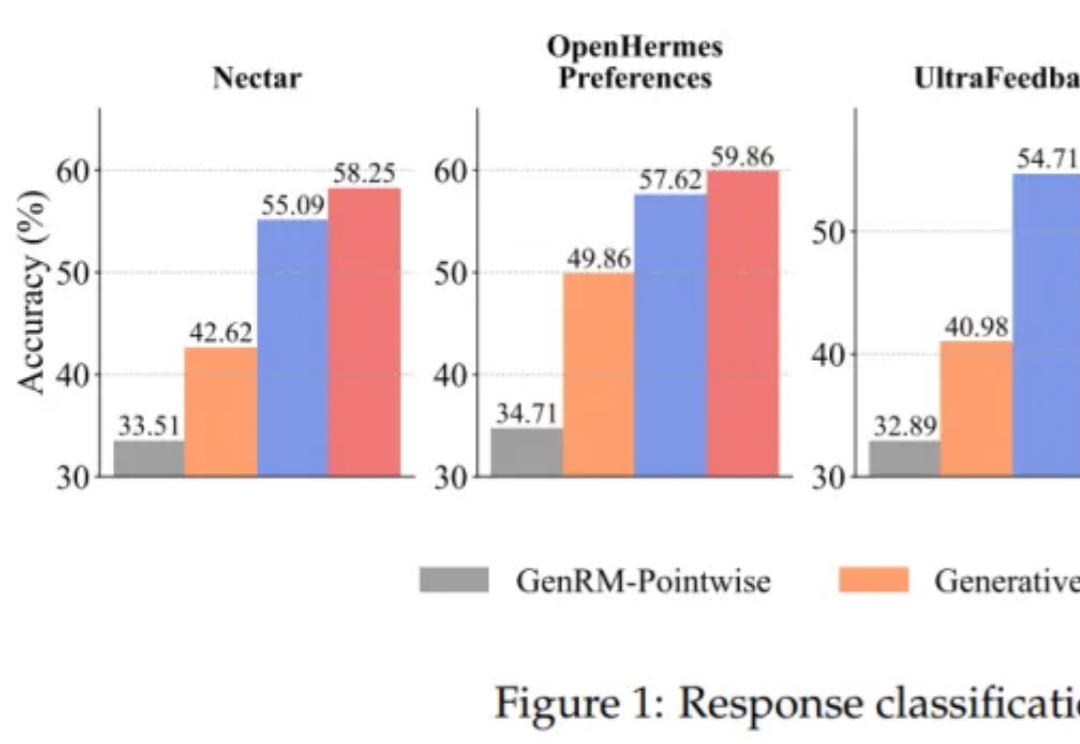
周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性
周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。
来自主题: AI技术研报
10089 点击 2025-07-03 10:00
 搜索
搜索
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越
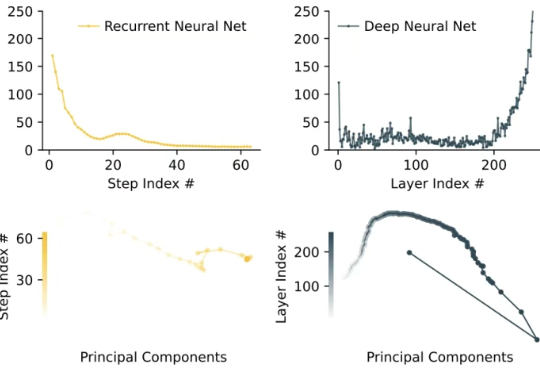
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
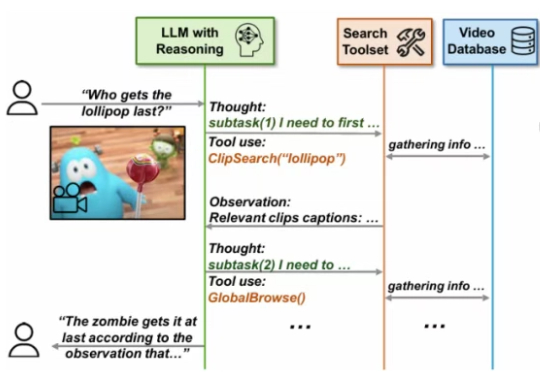
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。

继女皇报告后,硅谷财富管理巨头Iconiq Capital发布《2025年AI现状报告》!实测300家AI公司落地路径,聚焦成本结构、技术选型与人才构建,揭示AI从概念走向实战的七大真问题。

What?LLM也要看出身!确实,不同的数据集训出的模型“个性”会有大不同,尤其在加之权衡方面。这就像我们经常与自己内心相互竞争的目标和价值观作斗争。

这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
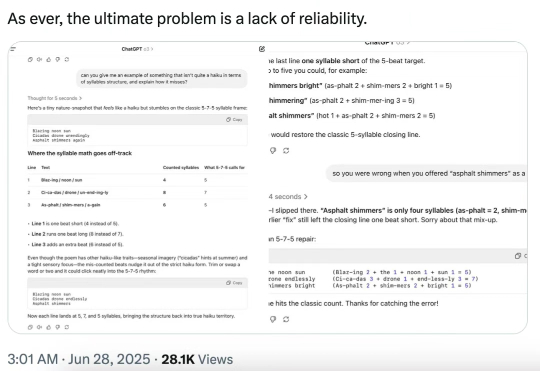
今天,著名的人工智能学者和认知科学家 Gary Marcus 转推了 MIT、芝加哥大学、哈佛大学合著的一篇爆炸性论文,称「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」
只需一眨眼的功夫,Mercury 就把任务完成了。「我们非常高兴地推出 Mercury,这是首款专为聊天应用量身定制的商业级扩散 LLM!Mercury 速度超快,效率超高,能够为对话带来实时响应,就像 Mercury Coder 为代码带来的体验一样。」
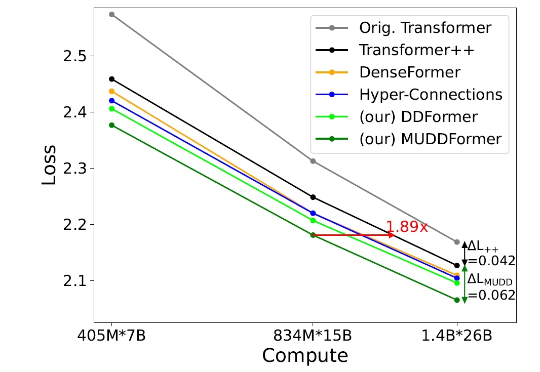
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。