
延迟下降20×,token减少4.4×!突破多智能体「共识」瓶颈
延迟下降20×,token减少4.4×!突破多智能体「共识」瓶颈过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
来自主题: AI技术研报
10689 点击 2026-02-07 14:04
 搜索
搜索
过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
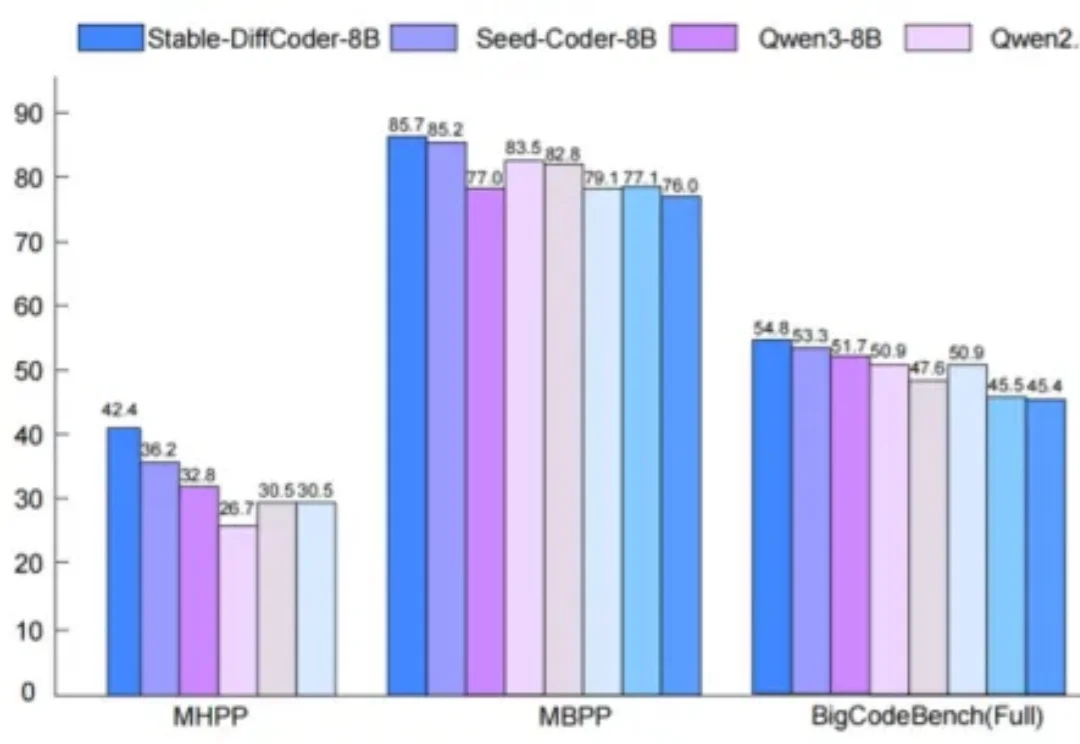
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
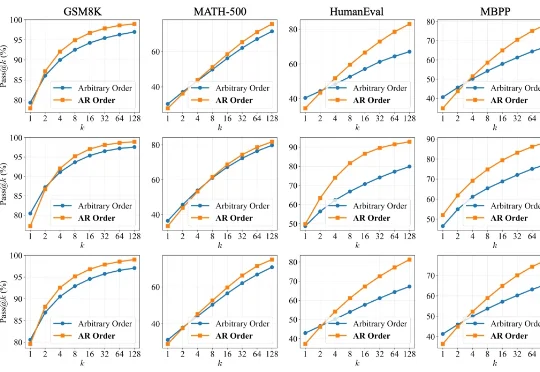
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。

为什么在LLM推理能力大幅跃升的2026,我们依然只有AI Copilot而没有AI Teammate?尽管AI编程工具遍地开花,但不管是Claude Code还是Codex,本质上仍是“单Agent开发”或“主从控制”架构。而“AI结对编程”迟迟无法落地?
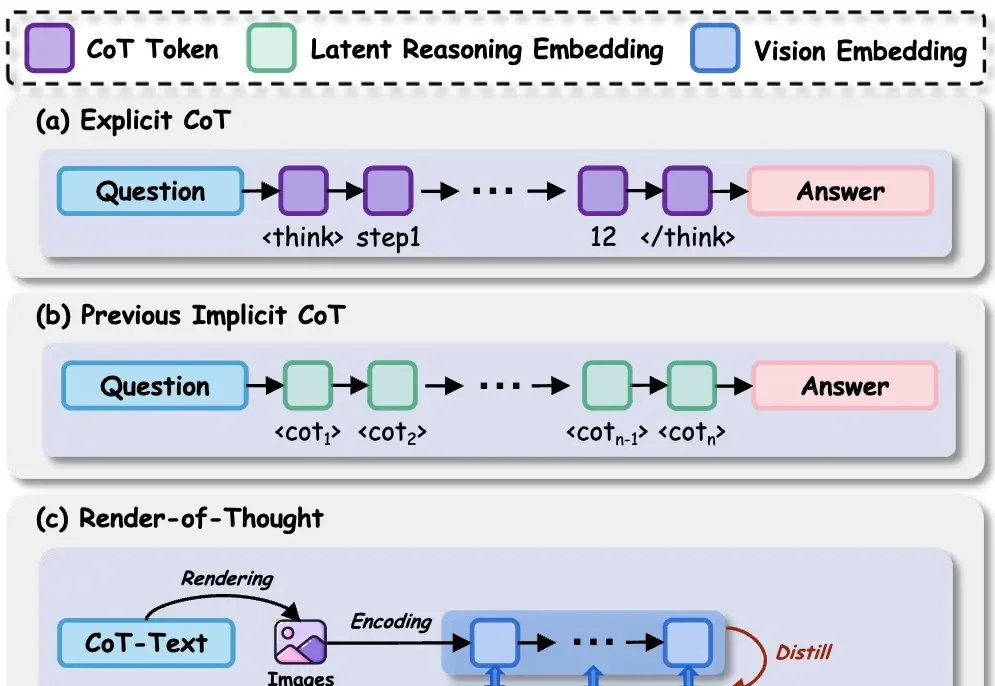
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。
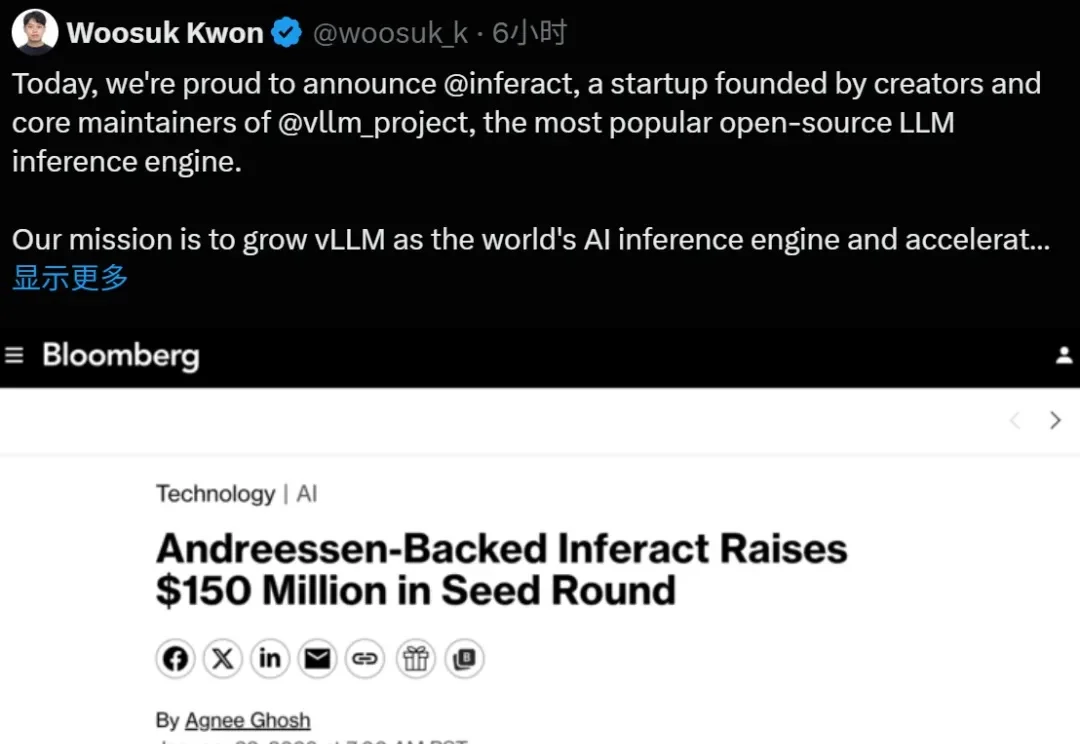
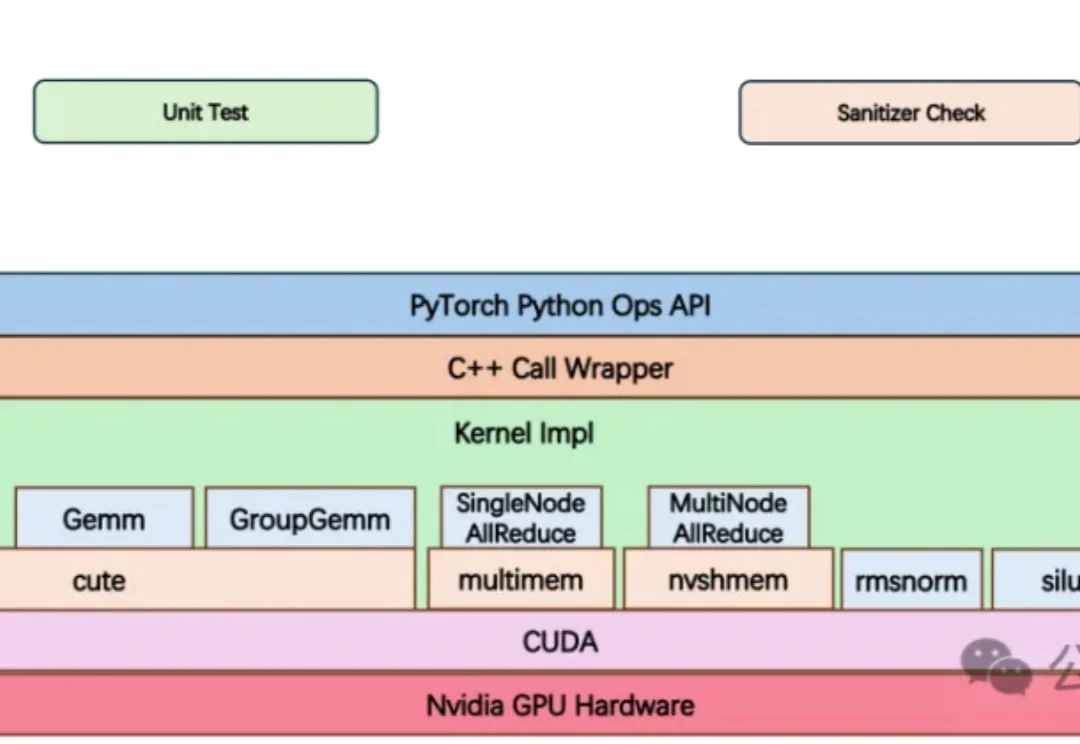
大模型推理的基石 vLLM,现在成为创业公司了。
大模型竞赛中,算力不再只是堆显卡,更是抢效率。

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。

目前已经出现了一些早期迹象,通用LLM助手领域的市场格局,正朝着“赢家通吃”,至少是“赢家通吃大部分市场”的趋势发展。在ChatGPT、Gemini、Claude 3和Cursor这几款产品中,仅有9%的用户会为一款以上的产品付费。