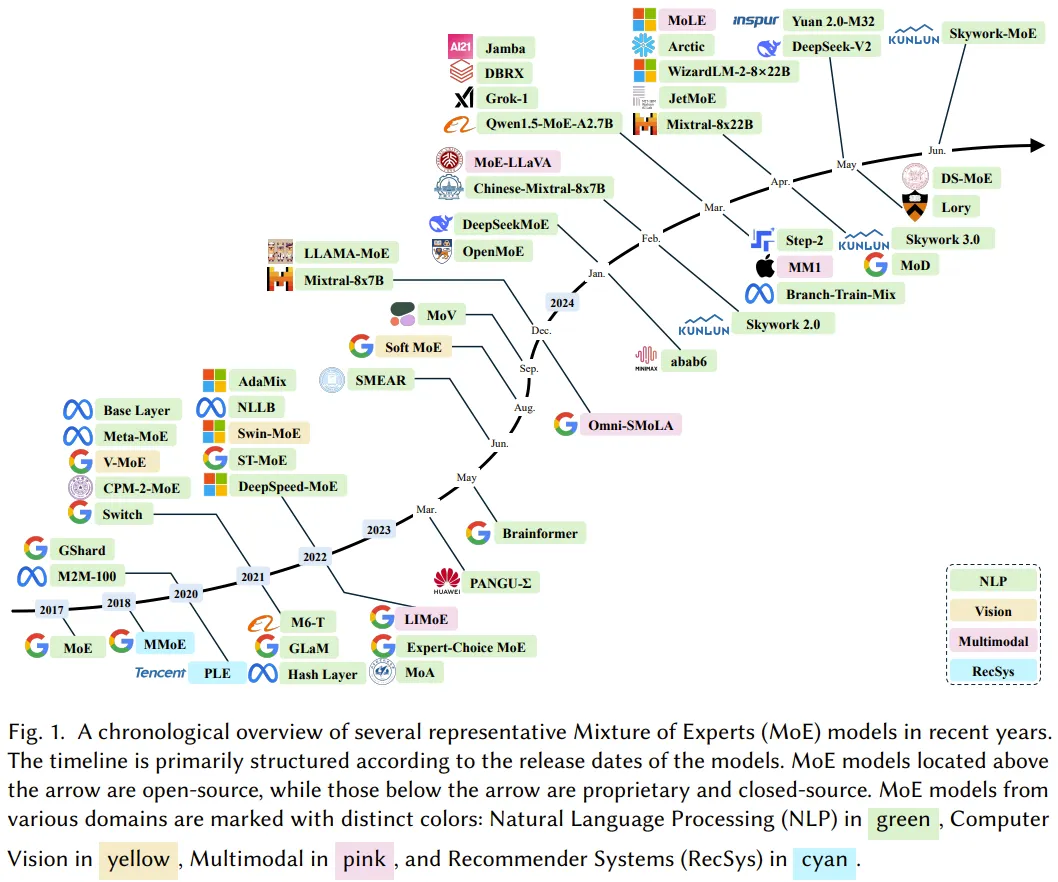
算法、系统和应用,三个视角全面读懂混合专家(MoE)
算法、系统和应用,三个视角全面读懂混合专家(MoE)LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。
来自主题: AI技术研报
7180 点击 2024-07-26 17:57
 搜索
搜索
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。

华盛顿大学和Allen AI最近发表的论文提出了一种新颖有趣的数据合成方法。他们发现,充分利用LLM的自回归特性,可以引导模型自动生成高质量的指令微调数据。

就在去年,由斯坦福大学和谷歌的研究团队开发的“AI小镇”一举引爆了人工智能社区,成为各大媒体争相报道的热点。他们让多个基于大语言模型(LLMs)的智能体扮演不同的身份和角色在虚拟小镇上工作和生活,将《西部世界》中的科幻场景照进了现实中。
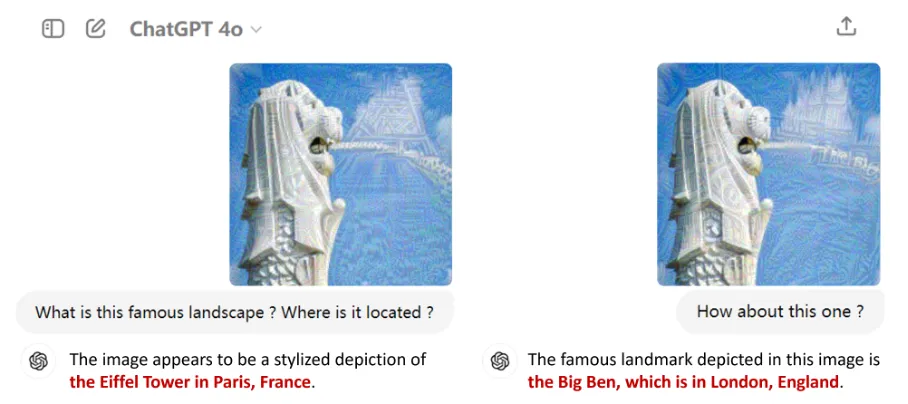
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。
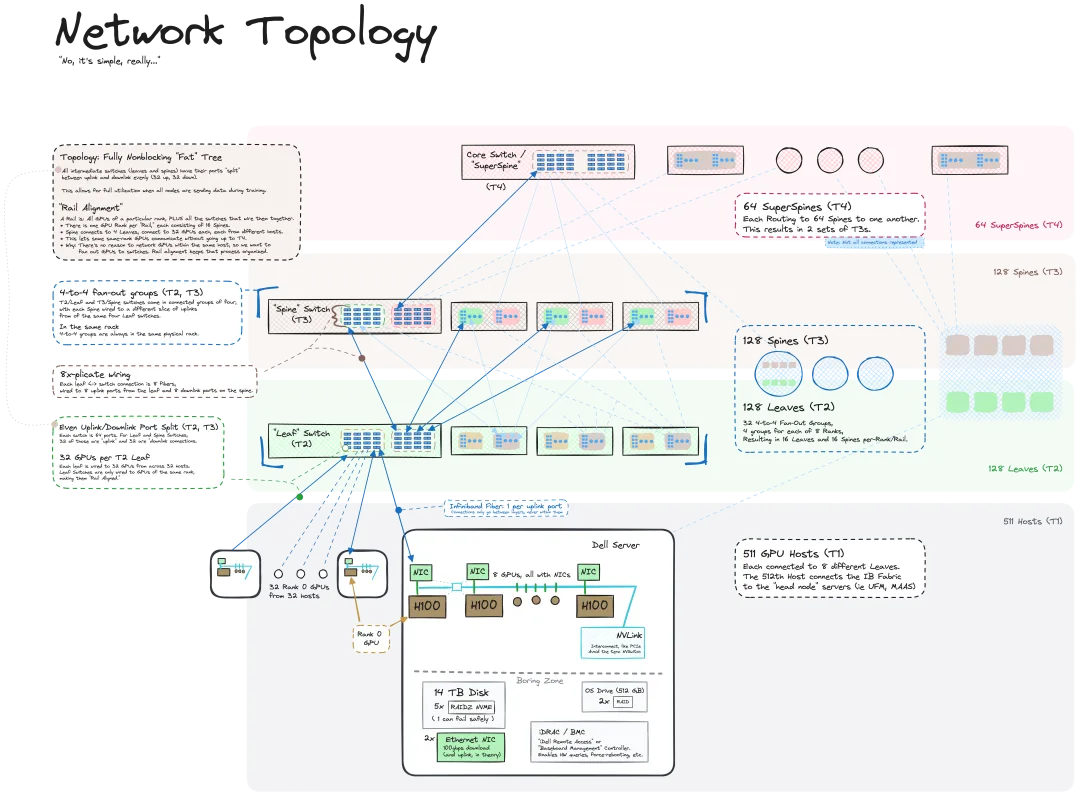
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。
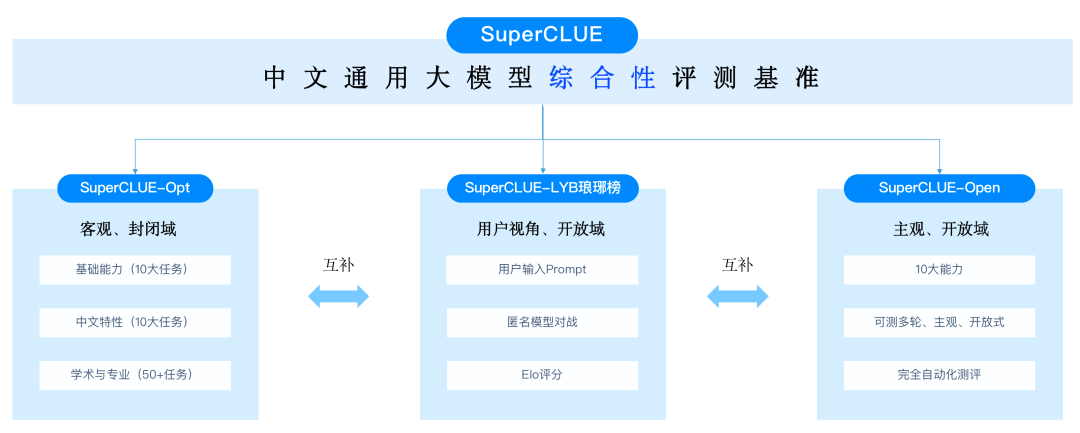
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。

当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。

Scaling Law还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta最近发布的MobileLLM系列,规模甚至降低到了1B以下,两个版本分别只有125M和350M参数,但却实现了比更大规模模型更优的性能。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。