
首届大模型顶会COLM 高分论文:偏好搜索算法PairS,让大模型进行文本评估更高效
首届大模型顶会COLM 高分论文:偏好搜索算法PairS,让大模型进行文本评估更高效大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。
来自主题: AI技术研报
11317 点击 2024-08-03 14:29
 搜索
搜索
大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。

大语言模型 (LLM) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?
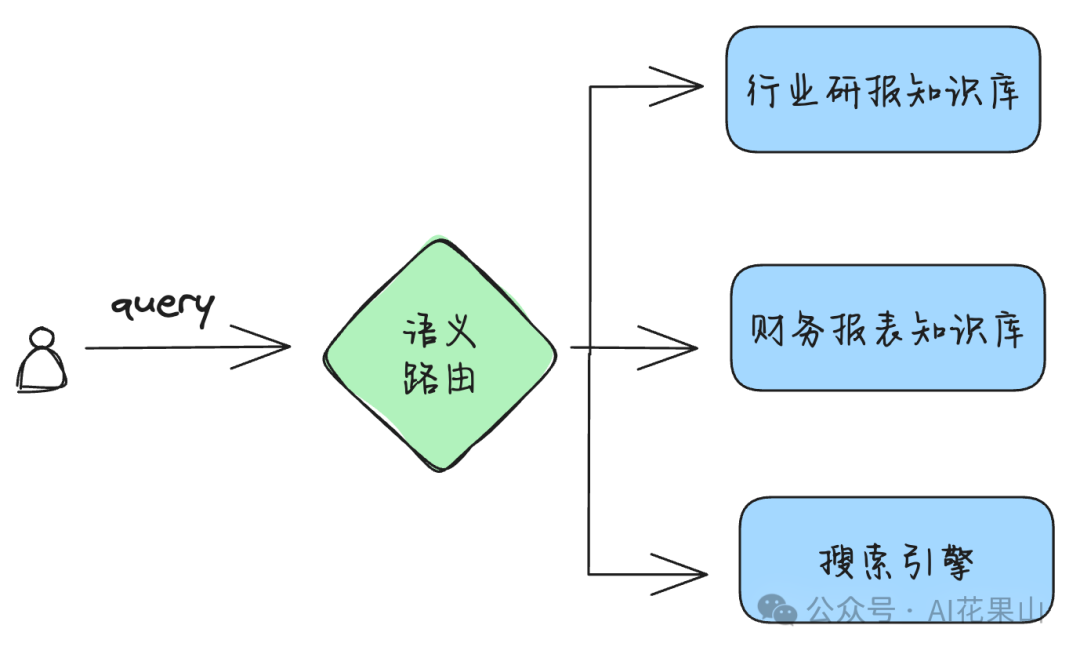
在这篇文章中,笔者将讨论以下几个问题: • 什么是语义路由 • RAG 路由的不同场景
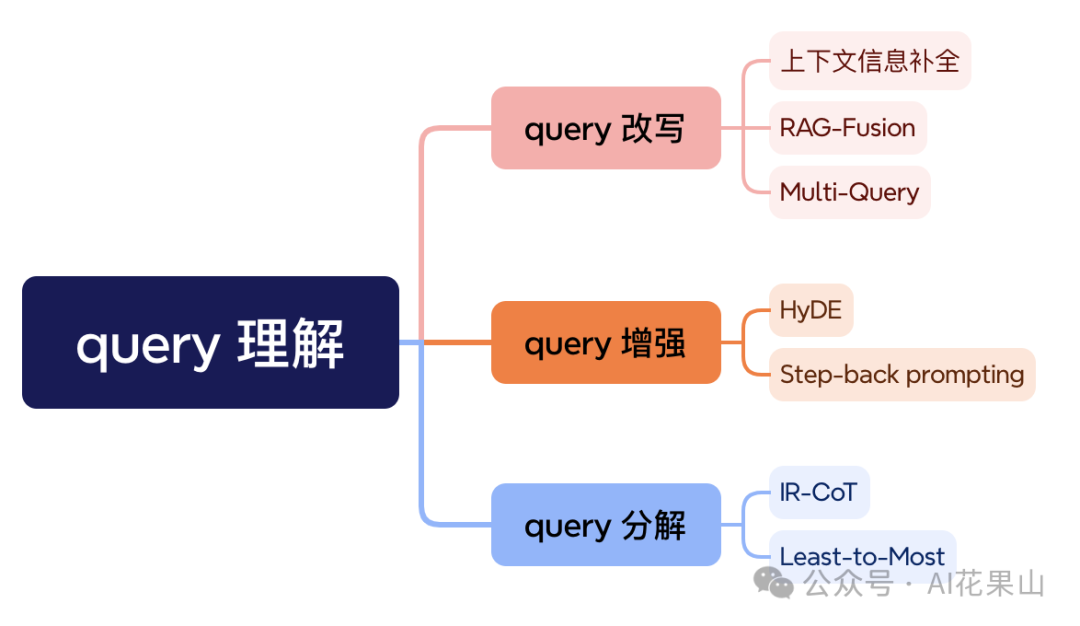
在这篇文章中,笔者将讨论以下几个问题: • 为什么要进行 query 理解 • query 理解有哪些技术(从 RAG 角度) • 各种 query 理解技术的实现(基于 LangChain)
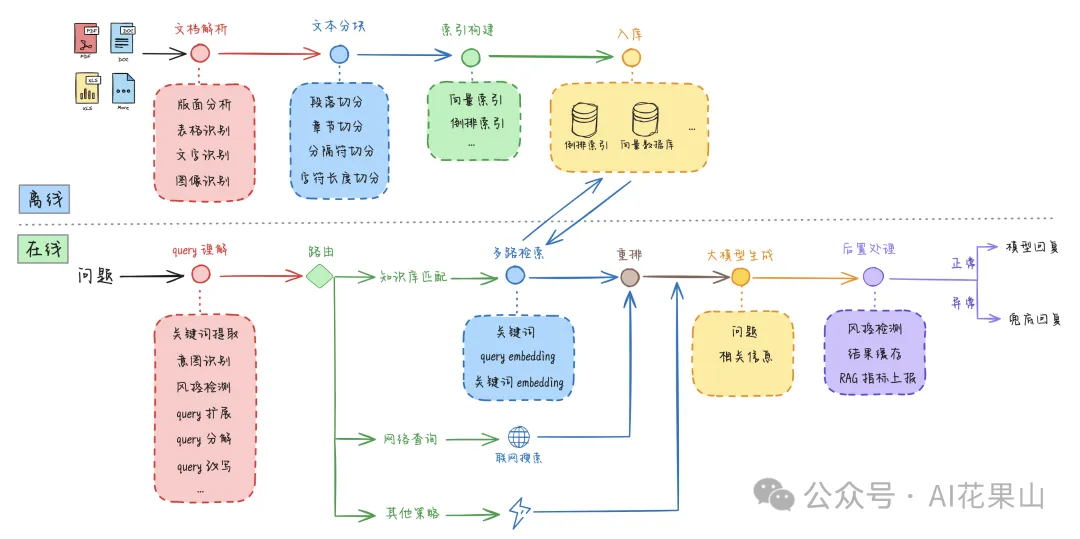
『RAG 高效应用指南』系列将就如何提高 RAG 系统性能进行深入探讨,提供一系列具体的方法和建议。同时读者也需要记住,提高 RAG 系统性能是一个持续的过程,需要不断地评估、优化和迭代。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。
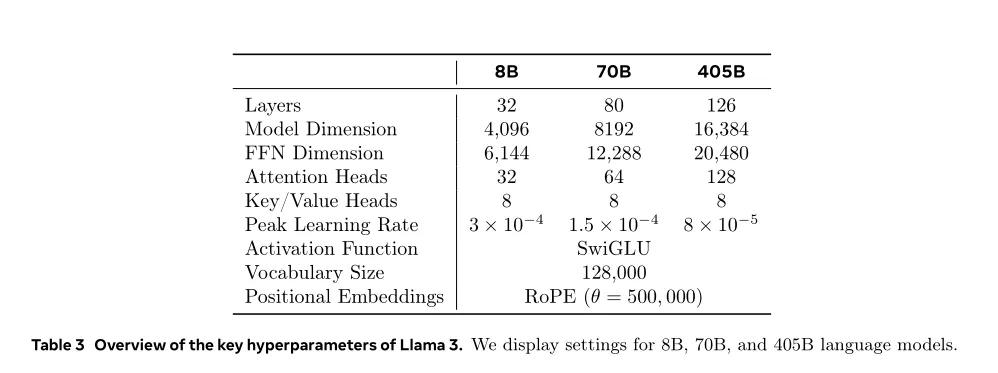
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。

谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。