32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世
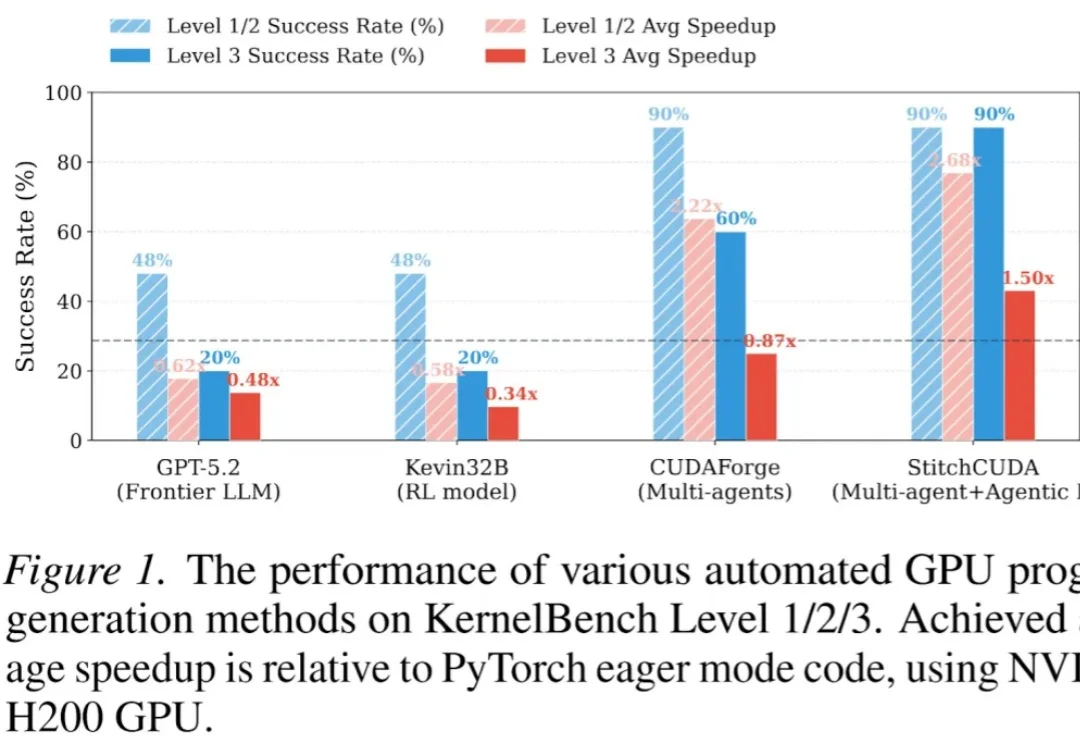
32B逆袭GPT-5.2:首个端到端GPU编程智能体框架StitchCUDA问世现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
来自主题: AI技术研报
8574 点击 2026-03-05 14:28
 搜索
搜索
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
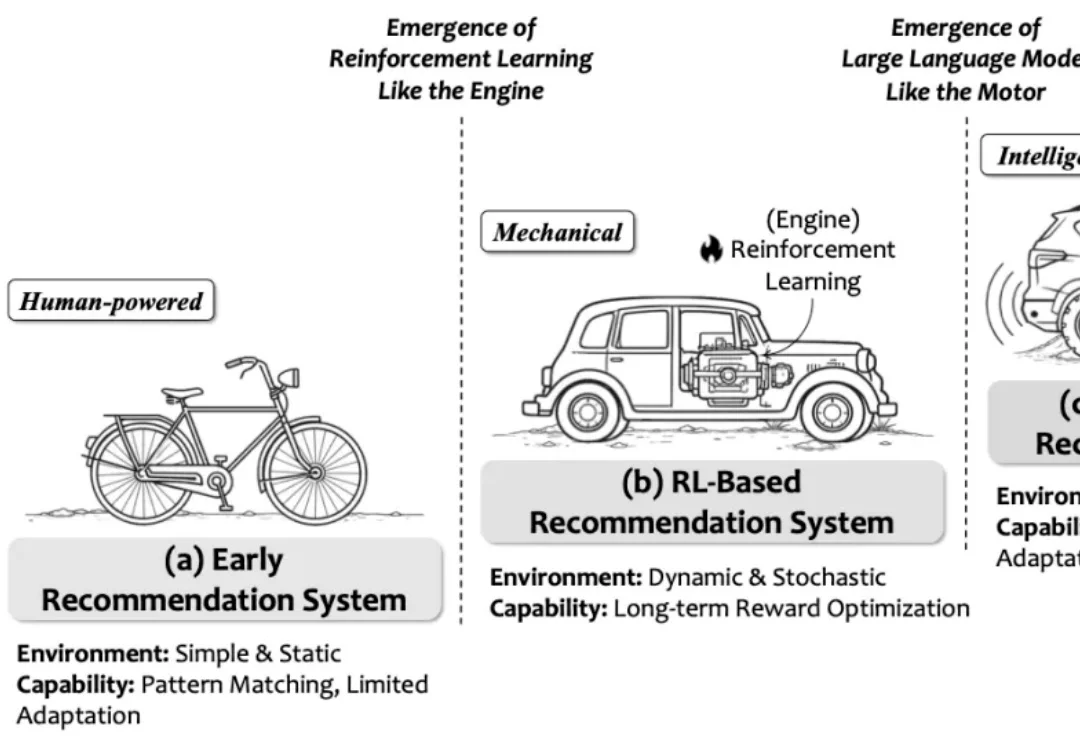
强化学习(RL)将推荐系统建模为序列决策过程,支持长期效益和非连续指标的优化,是推荐系统领域的主流建模范式之一。然而,传统 RL 推荐系统受困于状态建模难、动作空间大、奖励设计复杂、反馈稀疏延迟及模拟环境失真等瓶颈。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。

我天!感觉 Seed 1.8 发布还没多久,没想到 Doubao-Seed-2.0 这么快就杀到了…今天发都算是晚讯了。据官方介绍,这次 Seed 2.0 多模态理解能力全面升级,还强化了 LLM 与 Agent 能力,模型在真实长链路任务中可以稳定推进。
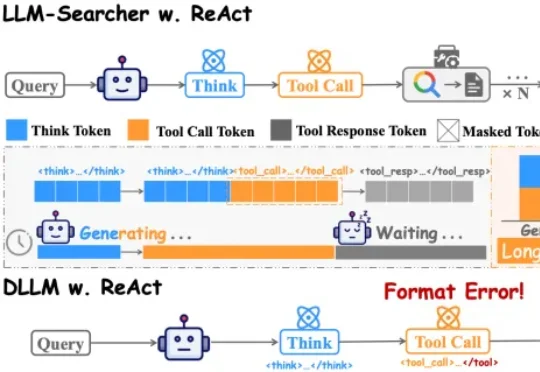
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
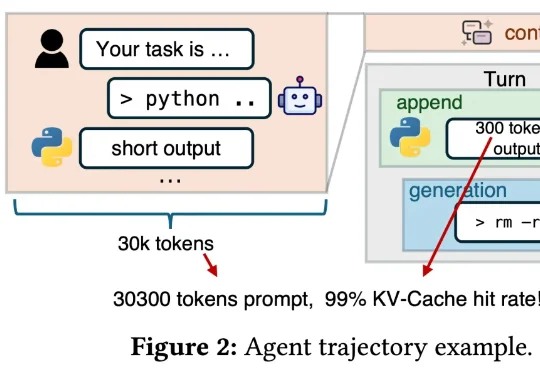
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
在他们看来,真正的胜负手不在于单点技能拉满,而在于能否在同一颗芯片里,把“训练级吞吐”和“推理级低延迟”同时做好——尤其是在长上下文、Agent循环这些更复杂的真实工作流中。
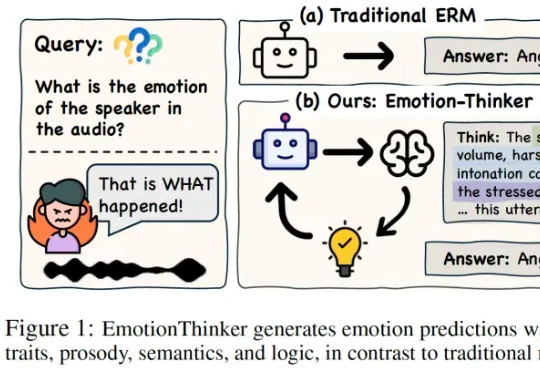
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。

在2026当下的智能体(Agent)开发体系中,“为LLM加Skills”已经成为事实上的行业标准。您的Agent表现不好,是因为底层的LLM参数量不够,还是因为您喂给它的“Skills”写得一塌糊涂?无论是日常使用的各类CLI工具,还是最近的Openclaw,其底层能力的跃升很大程度上都依赖于这些特定领域的Agent Skills。