多模态检索新突破,用软标签打破传统刚性映射约束,全面超越CLIP|AAAI 2026 Oral
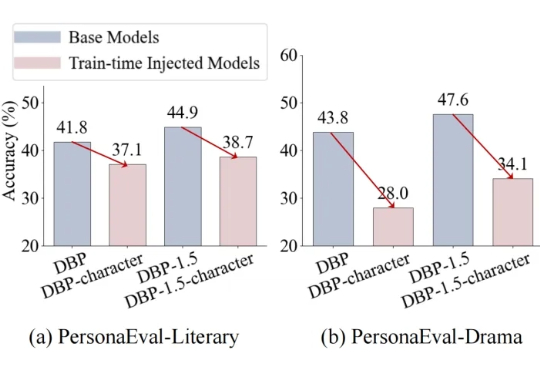
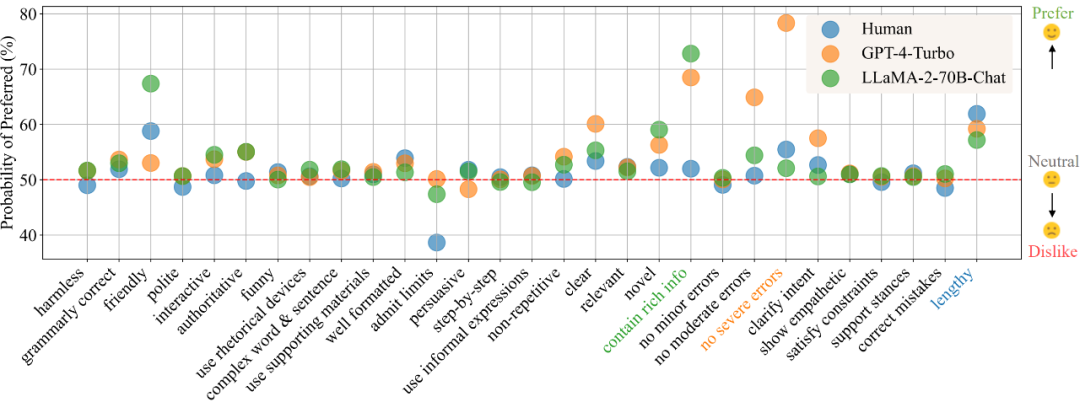
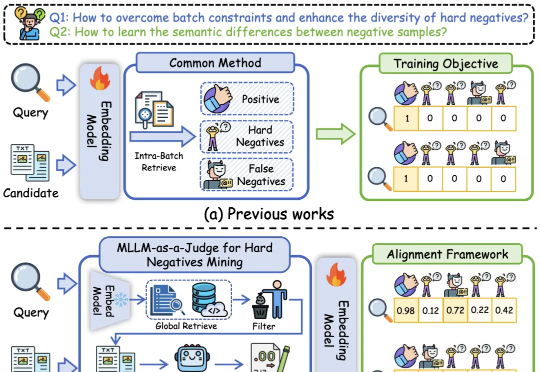
多模态检索新突破,用软标签打破传统刚性映射约束,全面超越CLIP|AAAI 2026 Oral基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
来自主题: AI技术研报
6657 点击 2025-10-06 21:53