本周(4.15-4.21)AI界发生了什么?
本周(4.15-4.21)AI界发生了什么?李彦宏说开源模型将越来越落后,然后Llama 3发布了。
来自主题: AI资讯
10515 点击 2024-04-24 10:31
 搜索
搜索
李彦宏说开源模型将越来越落后,然后Llama 3发布了。

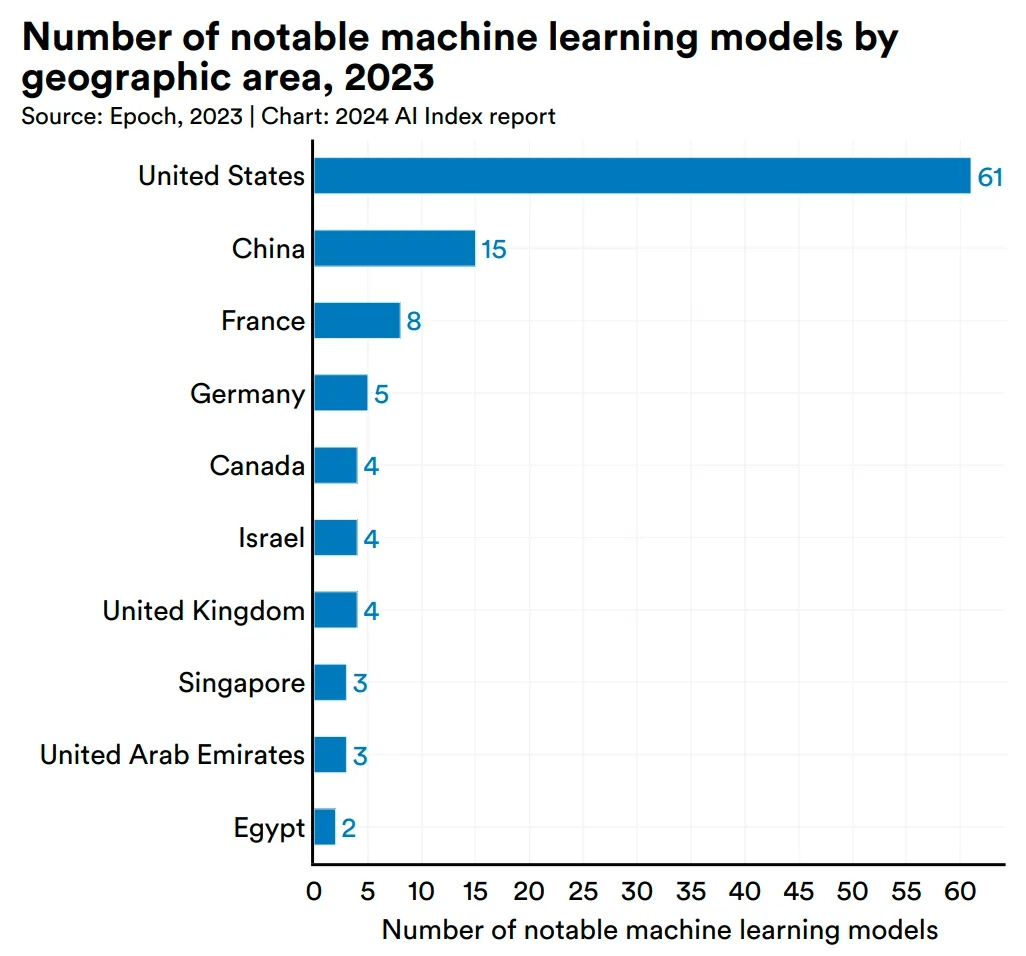
这段时间,AI模型界是真的热闹,新的模型不断涌现,不管是开源还是闭源,都在刷新成绩。就在前几天,Meta就上演了一出“重夺开源铁王座”的好戏。发布了Llama 3 8B和70B两个版本,在多项指标上都超越了此前开源的Grok-1和DBRX,成为了新的开源大模型王者。

Llama 3发布刚几天,微软就出手截胡了?
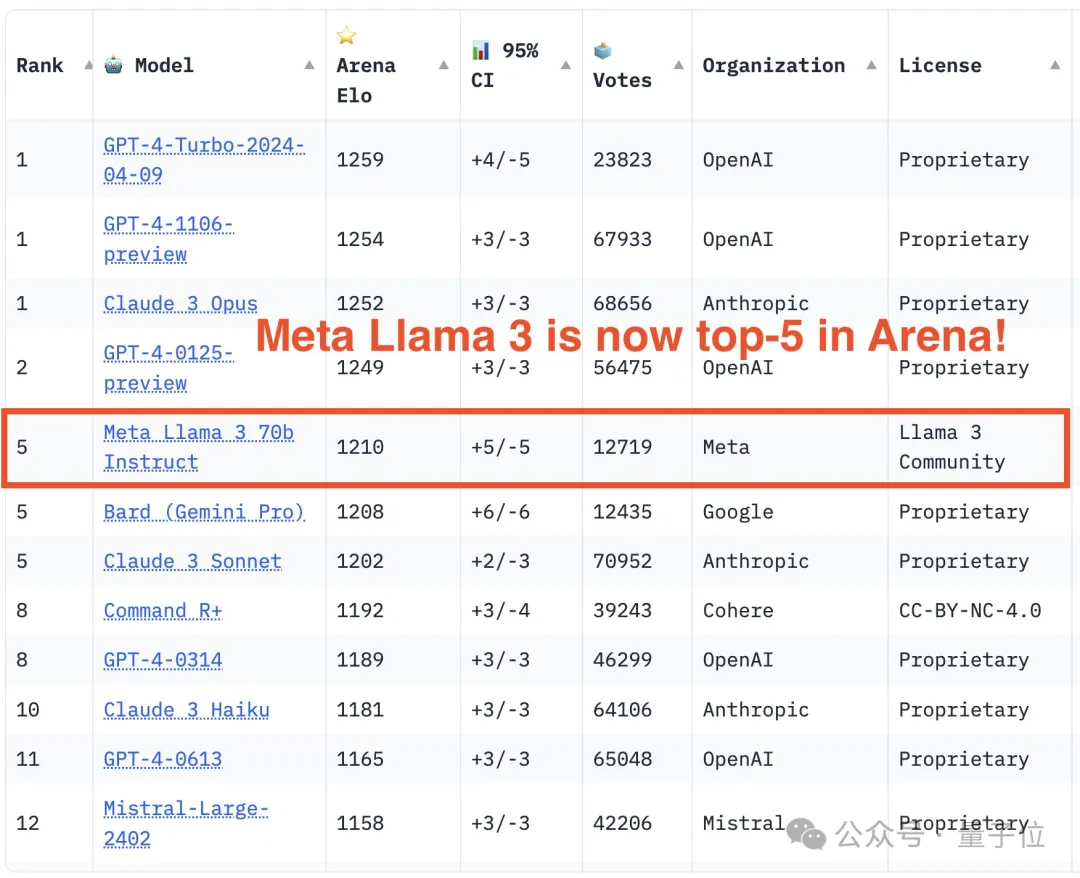
关于Llama 3,又有测试结果新鲜出炉—— 大模型评测社区LMSYS发布了一份大模型排行榜单,Llama 3位列第五,英文单项与GPT-4并列第一。
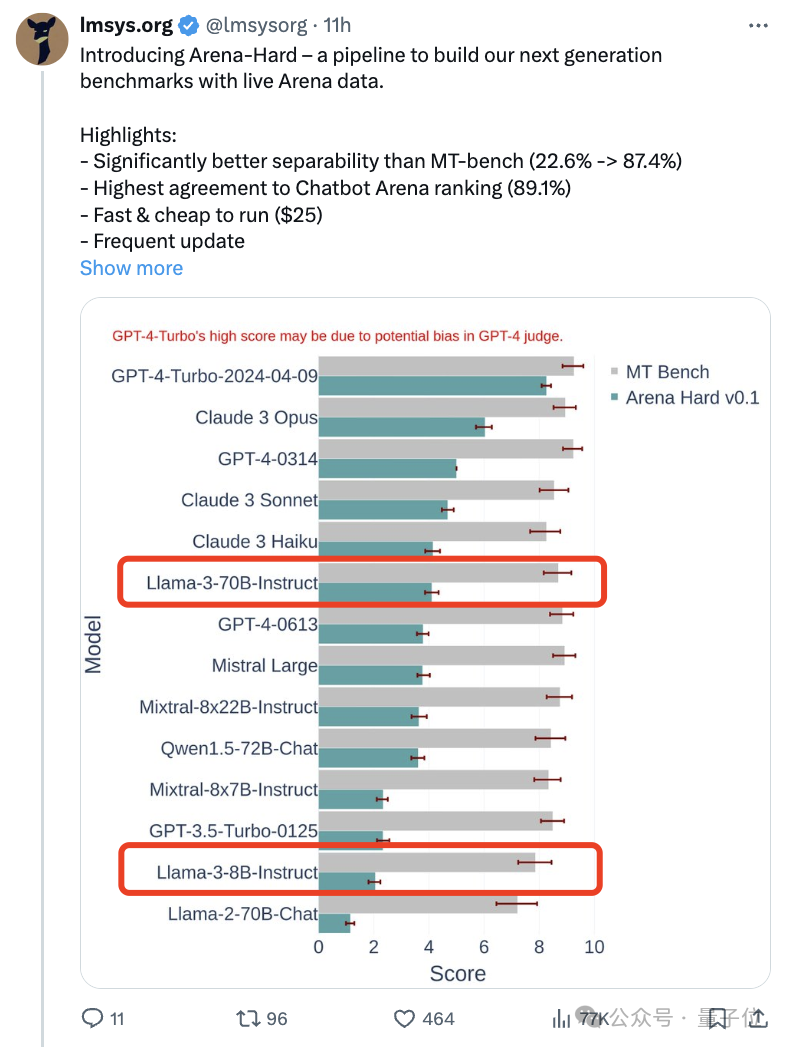
随着Claude 3、Llama 3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。

Llama 3诞生之后便艳压群雄,开源界已无「模」能敌。

就在刚刚,Meta官网上新,官宣了Llama 3 80亿和700亿参数版本
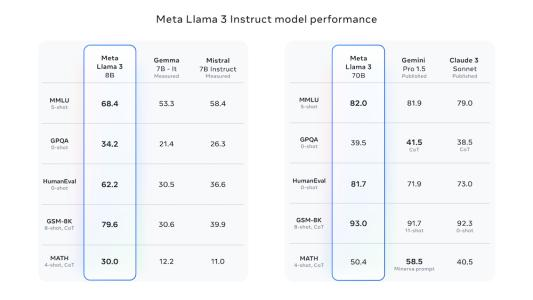
智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。
LLM界的「真·Open AI」,又来整顿AI圈了!

ChatGPT 拉开了大模型竞赛的序幕,Meta 似乎要后来居上了。 本周四,AI 领域迎来重大消息,Meta 正式发布了人们等待已久的开源大模型 Llama 3。