全球开源新王Qwen2-72B诞生,碾压Llama3-70B击败国产闭源模型!AI圈大佬转疯了
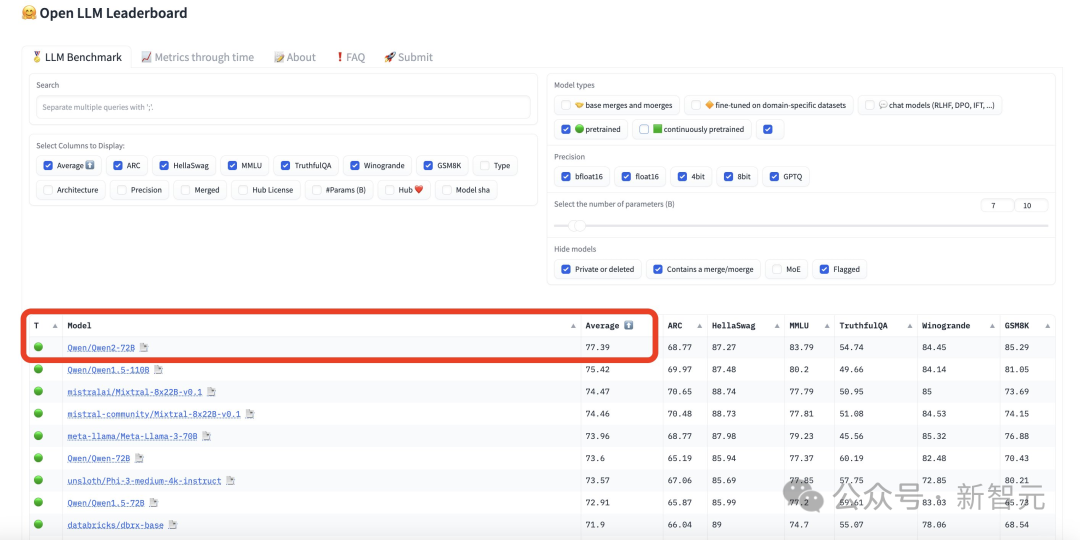
全球开源新王Qwen2-72B诞生,碾压Llama3-70B击败国产闭源模型!AI圈大佬转疯了一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。
来自主题: AI技术研报
11160 点击 2024-06-08 11:44
 搜索
搜索
一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。
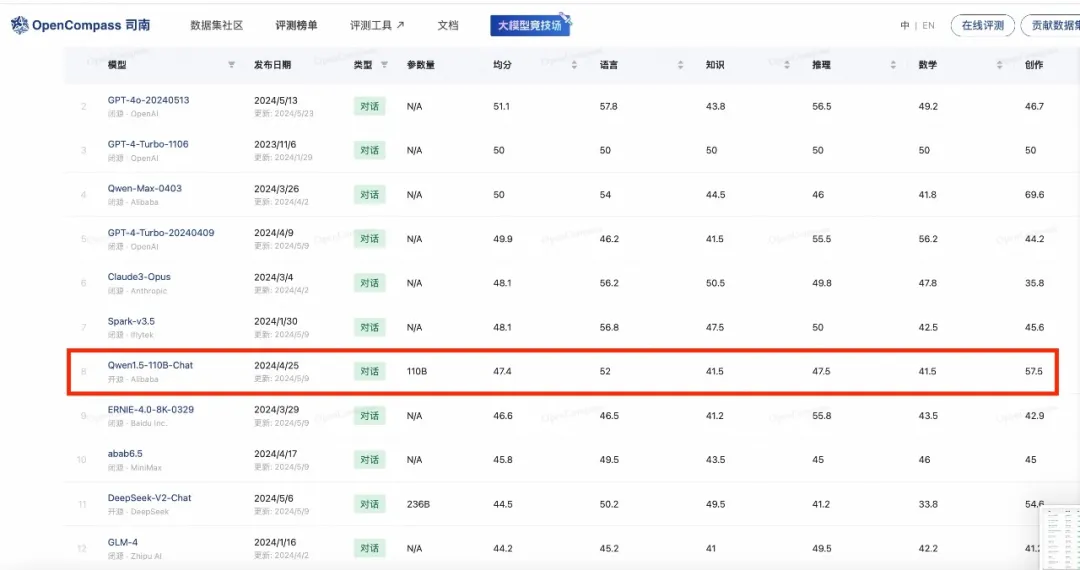
大模型领域,开源与闭源之争一直是技术和产业界关注的焦点。阿里云通义千问最新发布的Qwen2系列模型,为这场争论提供了最新的答案。
Qwen 系列会是众多大学实验室新的默认基础模型吗? 斯坦福团队套壳清华大模型的事件不断发酵后,中国模型在世界上开始得到了更多关注。不少人发现,原来中国已经有不少成熟的大模型正在赶超国外。

终于,AI大神李沐回来了!带着他的大模型创业最新成果——

Rabbit R1 又被扒出了更多伪AI产品的实锤。
最新版本大模型,6 分钱 100 万 Token。
去年10月,硅谷VC巨头Vinod Khosla曾在X发文,“忧心忡忡”地称美国的开源大模型都会被中国抄去。万万没想到,8个多月过去,射出的回旋镖最终扎回了自己的心。

抄袭框架和预训练数据的情况,是更狭义的套壳。
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。
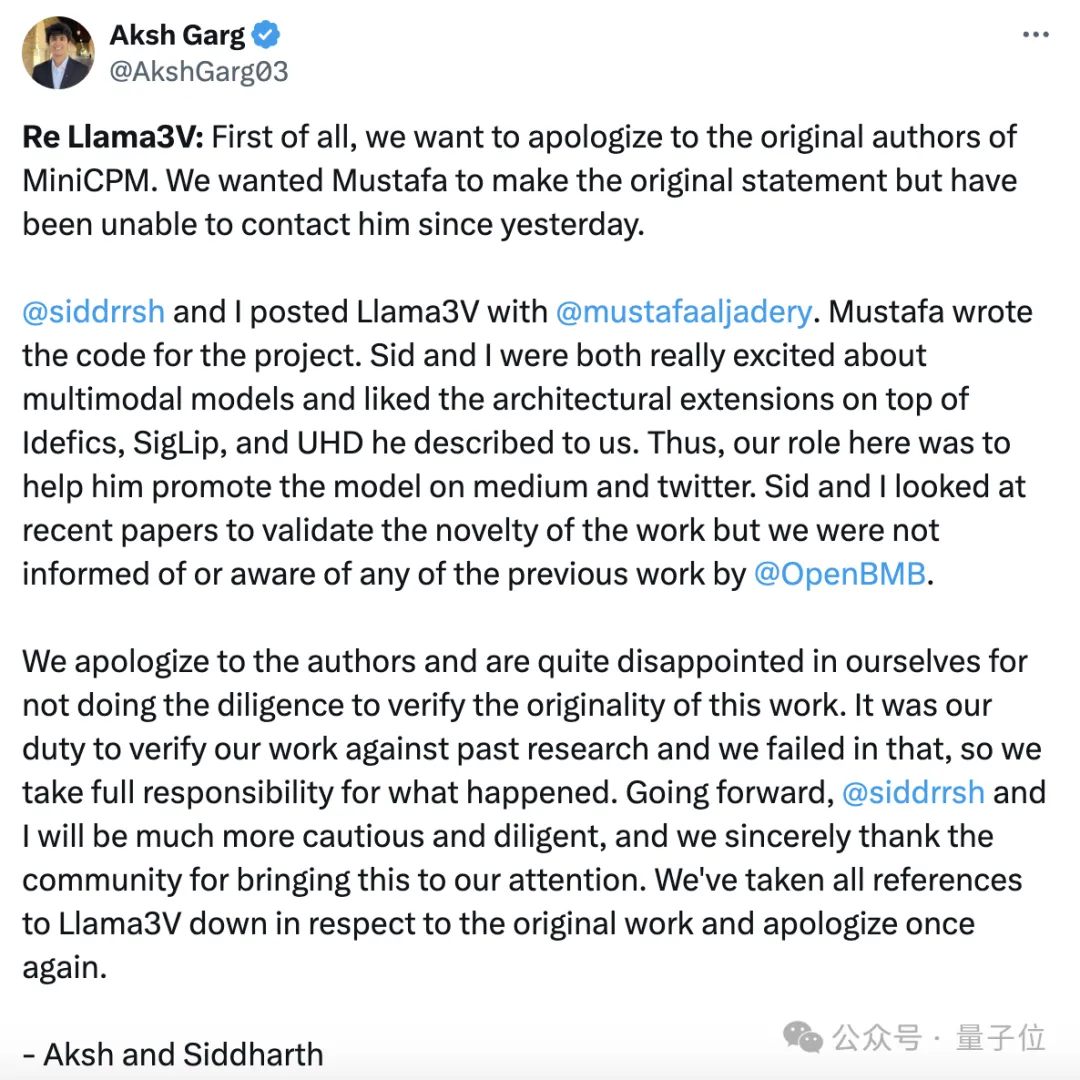
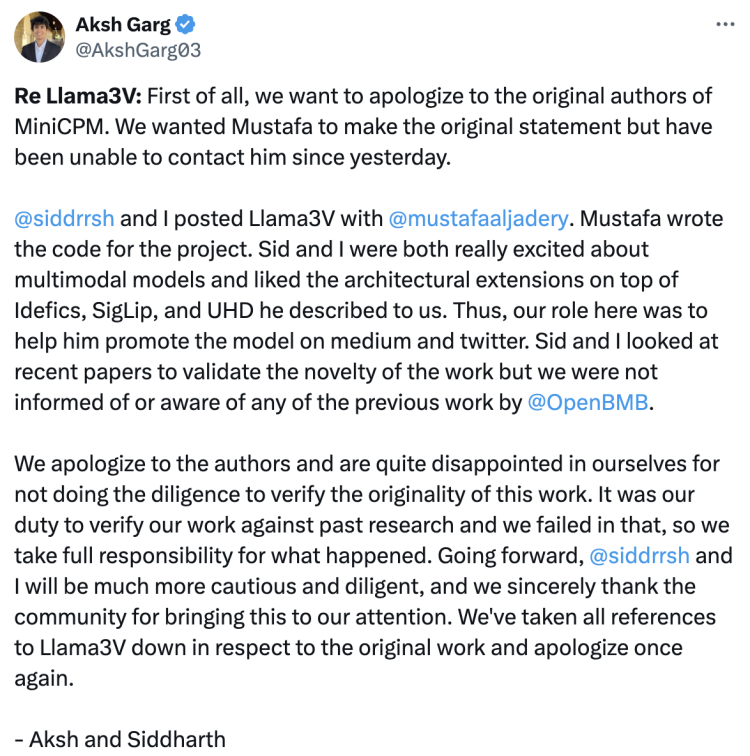
斯坦福团队抄袭清华系大模型事件后续来了—— Llama3-V团队承认抄袭,其中两位来自斯坦福的本科生还跟另一位作者切割了。