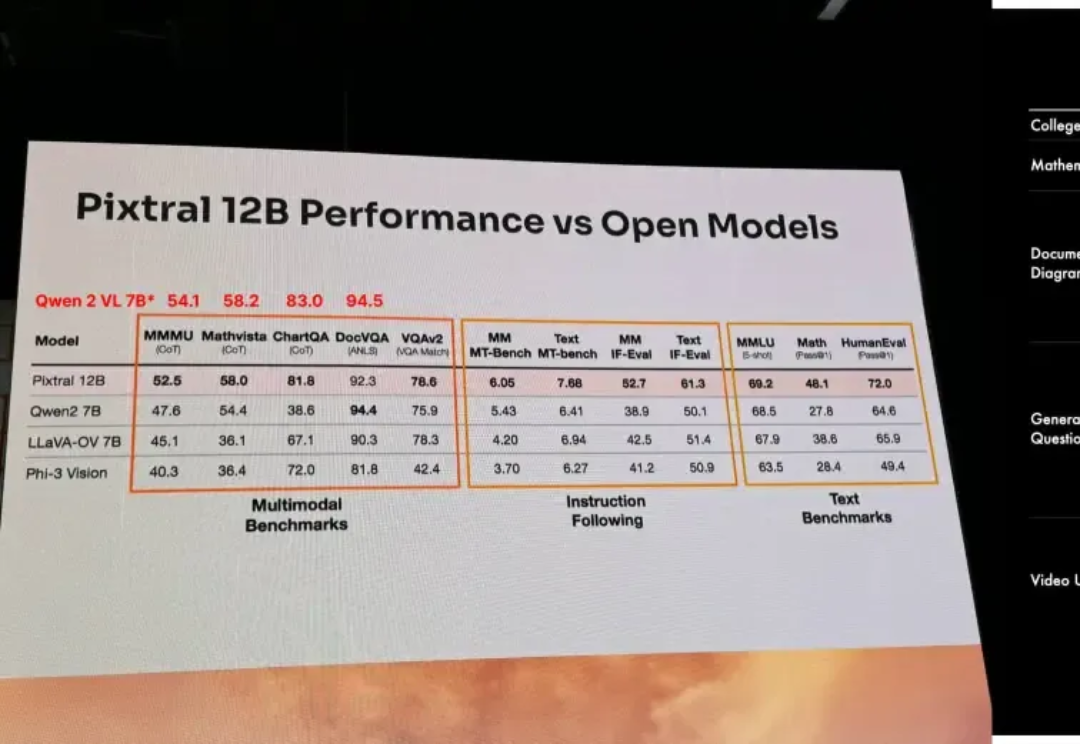
多模态竞技场对标90B Llama 3.2!Pixtral 12B技术报告全公开
多模态竞技场对标90B Llama 3.2!Pixtral 12B技术报告全公开以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。
来自主题: AI技术研报
7462 点击 2024-11-19 17:15
 搜索
搜索
以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。

大模型的记忆限制被打破了,变相实现“无限长”上下文。最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。
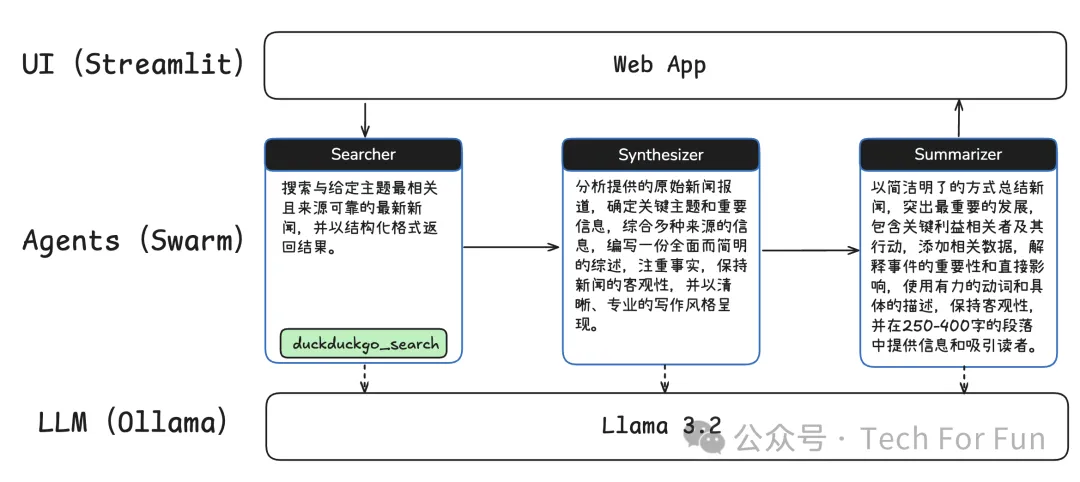
本文将带你构建一个多智能体新闻助理,利用 OpenAI 的 Swarm 框架和 Llama 3.2 来自动化新闻处理工作流。在本地运行环境下,我们将实现一个多智能体系统,让不同的智能体各司其职,分步完成新闻搜索、信息综合与摘要生成等任务,而无需付费使用外部服务。

复刻OpenAI o1推理大模型,开源界传来最新进展: LLaMA版o1项目刚刚发布,来自上海AI Lab团队。
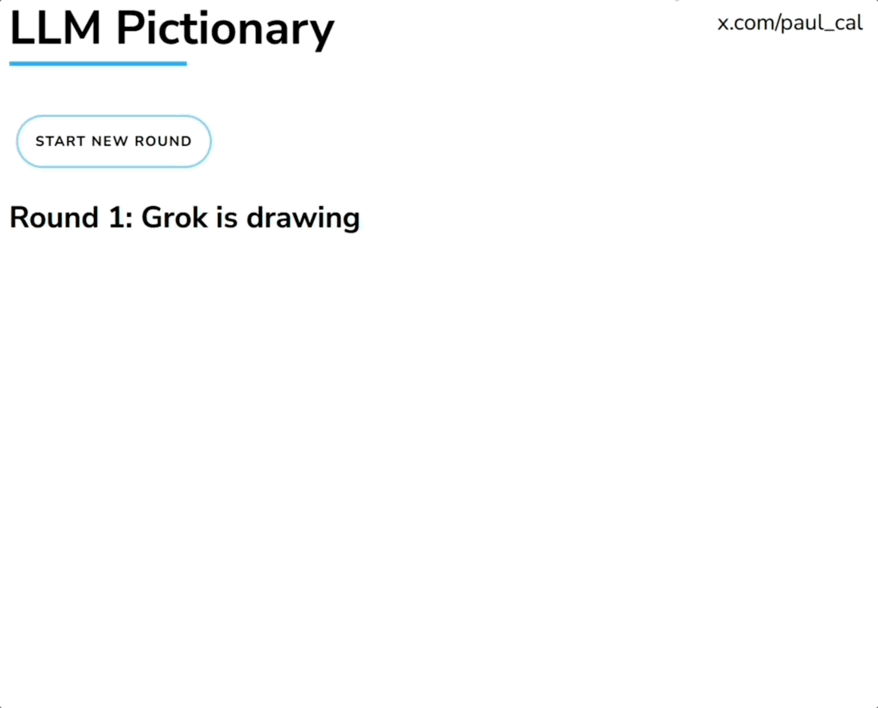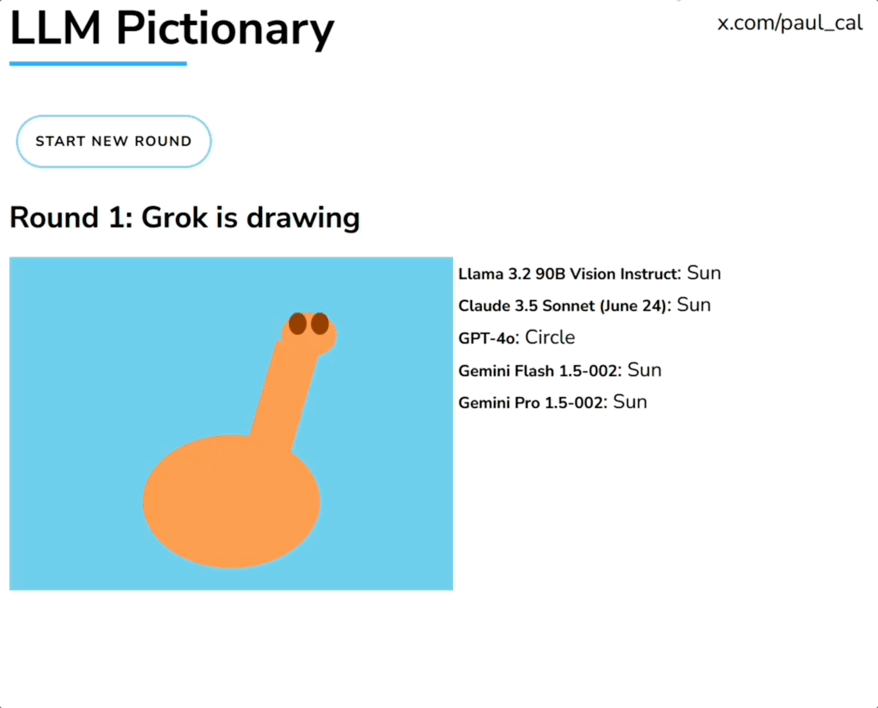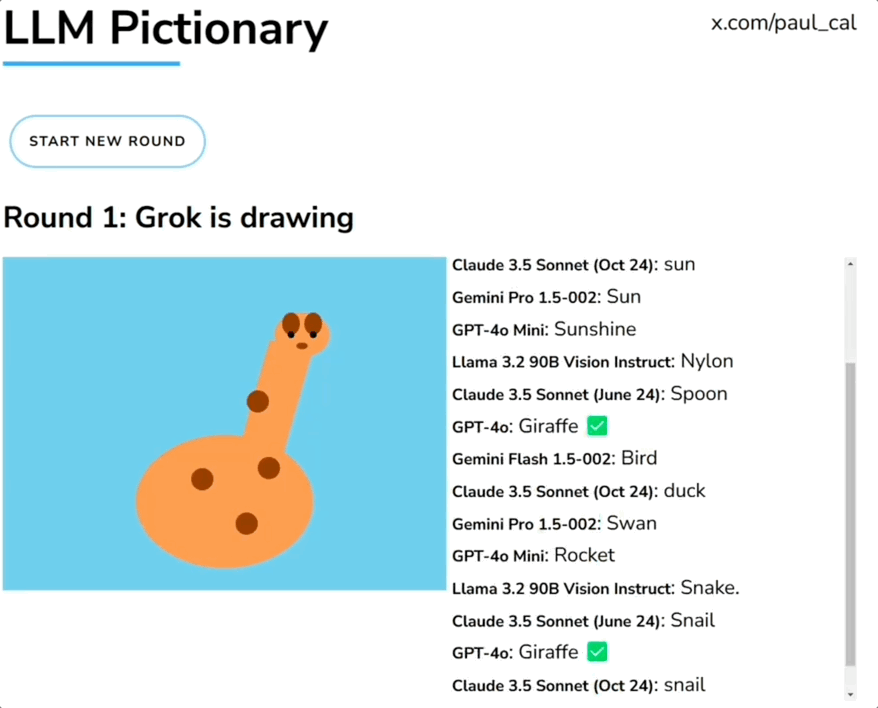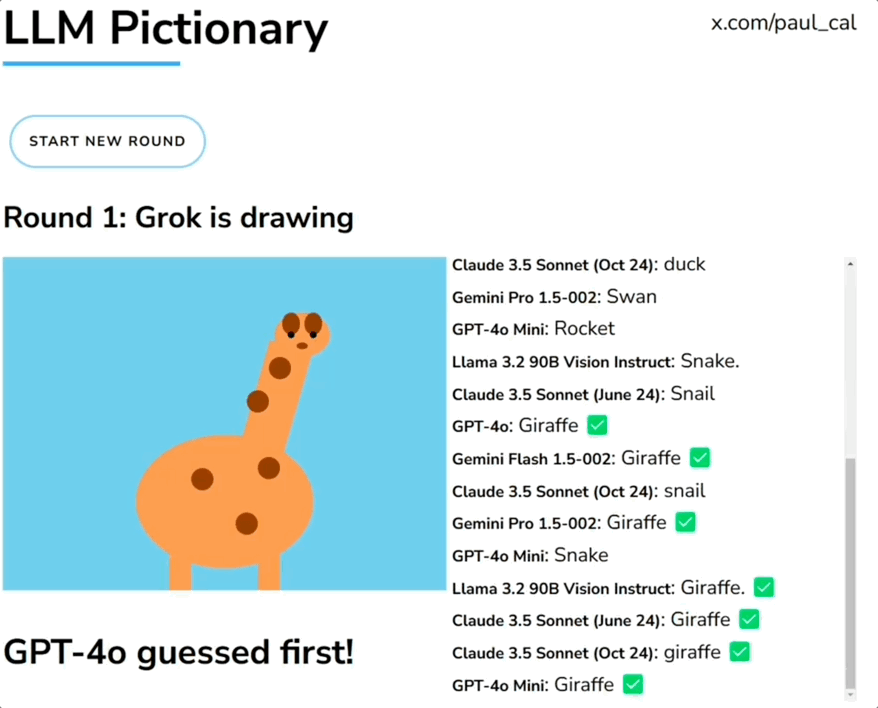
一群大模型玩你画我猜,人类一旁围观超起劲儿。 就像下面这张图展示的,由Grok画长颈鹿,一堆大模型根据生成内容猜答案。参赛选手包括GPT-4o、Claude、Llama、Gemini、Grok等。
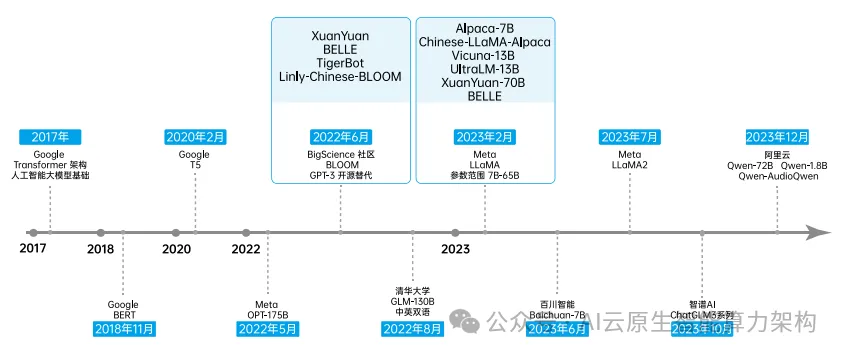
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。

北京时间 10 月 30 日,GitHub Universe 2024 如约而至,而今年正值大会十周年纪念日。本文将从 GitHub 发布的 AI 新进展入手,围绕开源模型、用户数量、盈利模式、发展历程等几个方面,全面梳理 GitHub 与 Hugging Face 两大开源平台的异同。

大模型开源的口号,不是随便说说的。

随着谷歌和 Meta 相继推出基于大语言模型的 AI 播客功能,将极大地丰富人类用户与 AI 智能体互动的体验。