深扒GPT Image 2:疑似“吞”下了GPT-4o,OpenAI没把它当“生图”模型训练
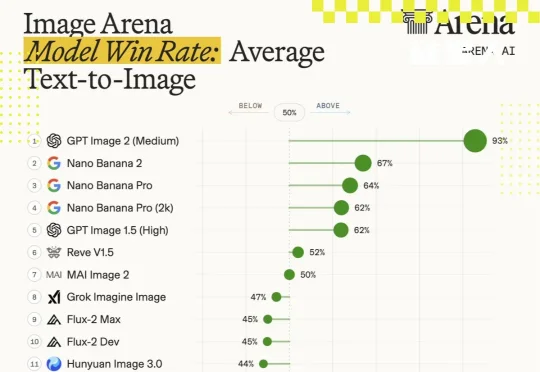
深扒GPT Image 2:疑似“吞”下了GPT-4o,OpenAI没把它当“生图”模型训练GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。
来自主题: AI技术研报
7954 点击 2026-05-03 22:58