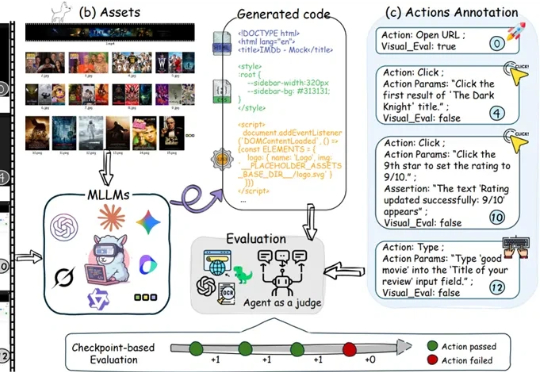
让模型“看视频写网页”,GPT-5仅得36.35分!上海AI Lab联合发布首个video2code基准
让模型“看视频写网页”,GPT-5仅得36.35分!上海AI Lab联合发布首个video2code基准多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
来自主题: AI技术研报
8404 点击 2025-10-20 14:57
 搜索
搜索
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
Reve AI 是一家 2023 年 12 月才建立的加州 AI 初创公司,他们在 2025 年 3 月推出了第一个生图模型叫 Reve Image 1.0,内部代号是「Halfmoon」。6 个月过后,再次升级该模型为「图像编辑模型」。
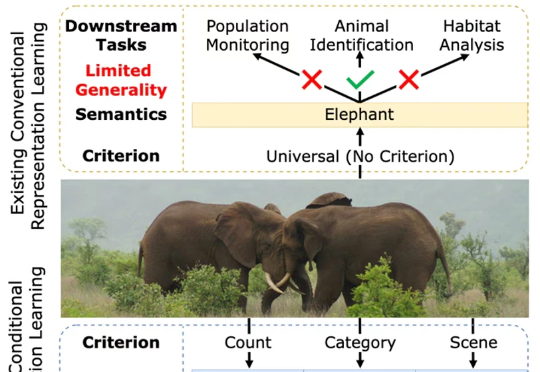
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。

近日,RoboChallenge 重磅推出!这是全球首个大规模、多任务的在真实物理环境中由真实机器人执行操作任务的基准测试。
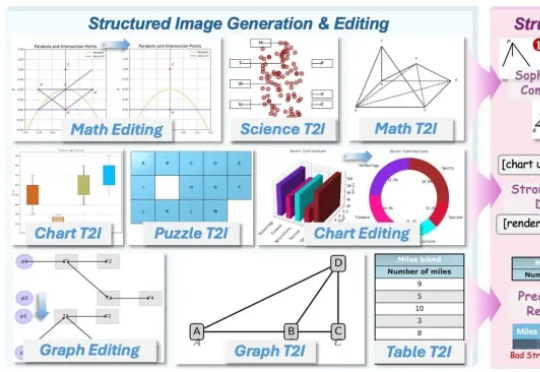
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
李飞飞要用ImageNet的方式,推动具身智能了。就在最近,由李飞飞团队发起、英伟达赞助(其中之一)的首届BEHAVIOR家务挑战赛正式启动。这一次,他们下定决心凝聚学术界和产业界的力量,共同向机器人做家务这一高地发起冲击。
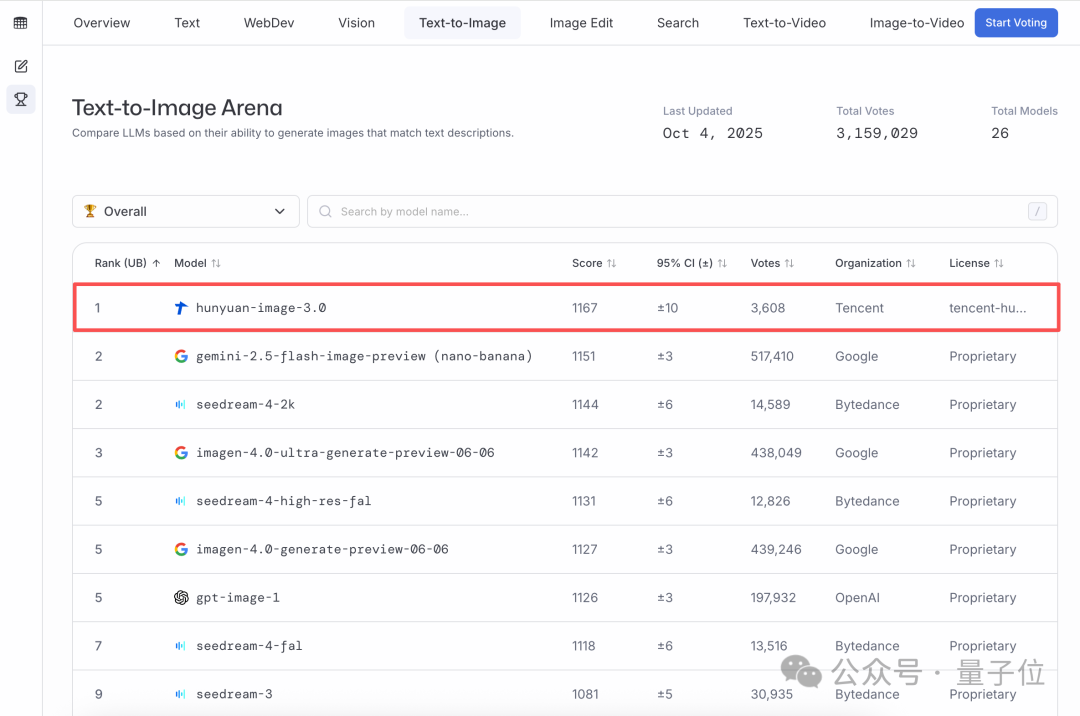
全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。
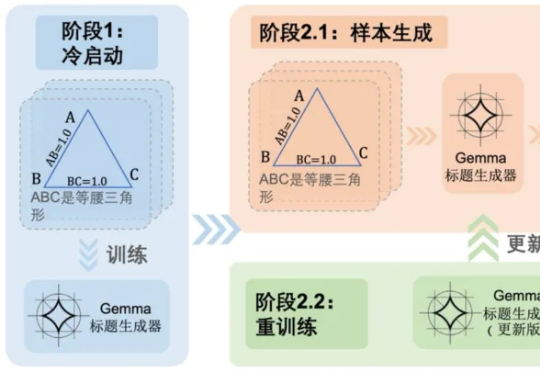
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。

刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。不仅支持多图融合,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。