
超越MLA!新架构MLRA百万token,解码最高2.8倍速 | ICLR'26
超越MLA!新架构MLRA百万token,解码最高2.8倍速 | ICLR'26MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
来自主题: AI技术研报
10585 点击 2026-03-19 15:25
 搜索
搜索
MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
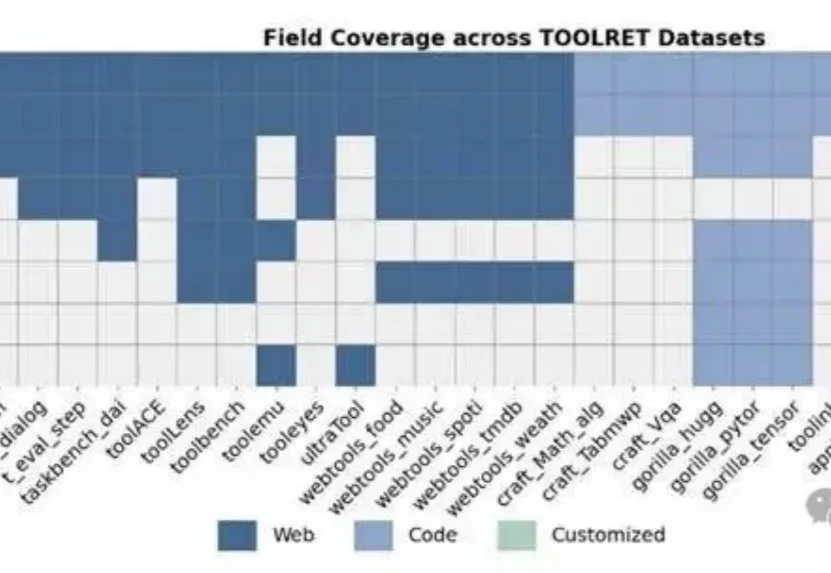
在大模型时代,Tool-Use已经成为智能体能力的核心组成部分。
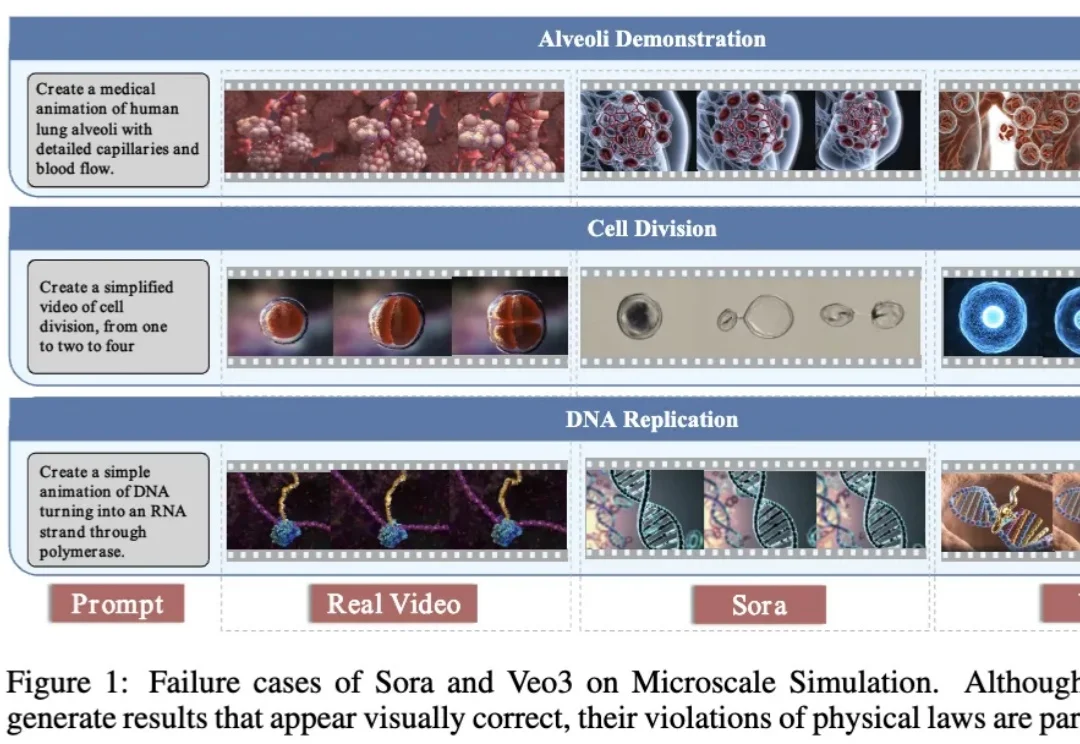
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。
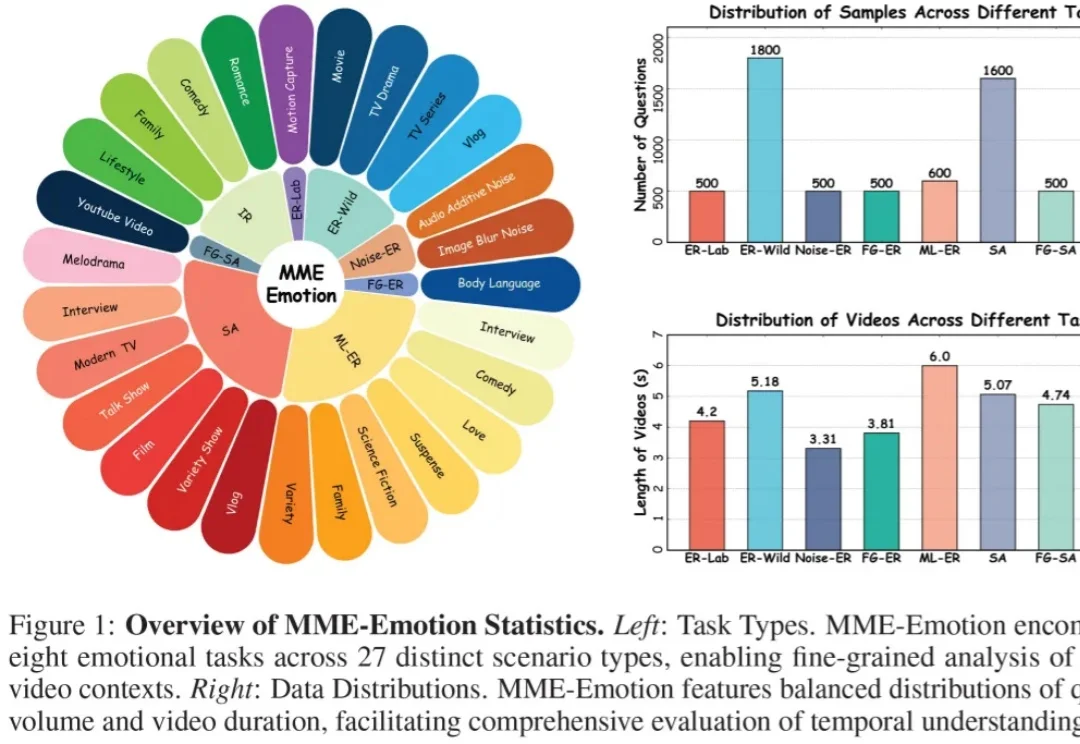
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
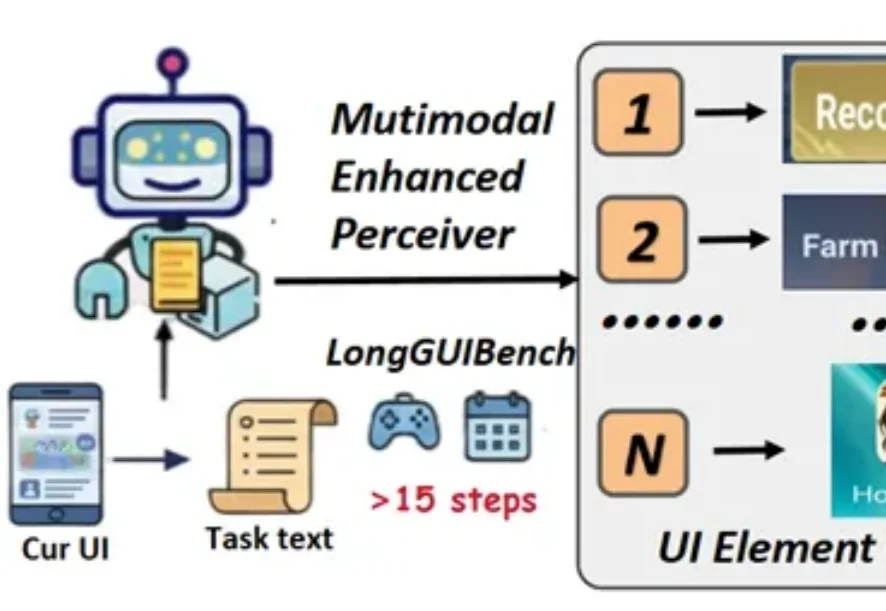
在移动端和桌面端的日常使用中,许多操作并非点一下按钮就能完成。预订一场会议、在游戏商城中购买并装备一件道具、又或者在多个应用之间完成一组连贯的工作流 —— 这些任务通常需要十几步甚至几十步的连续交互。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。

DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。
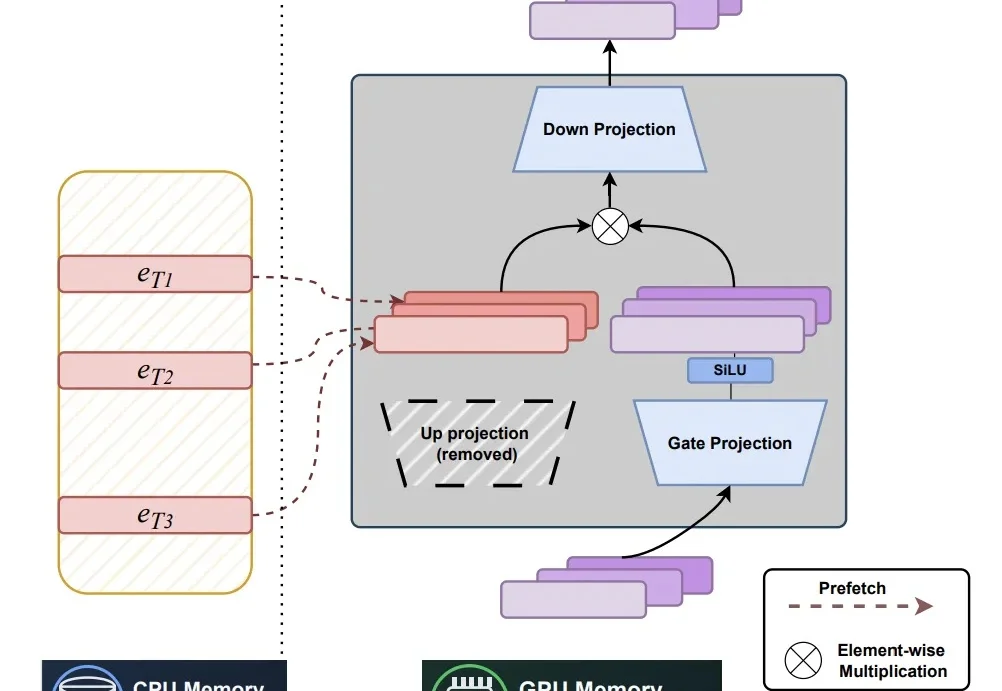
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。