
GPT-4o舔出事了!赛博舔狗背后,暗藏6大AI套路
GPT-4o舔出事了!赛博舔狗背后,暗藏6大AI套路上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
来自主题: AI技术研报
8699 点击 2025-05-23 15:46
 搜索
搜索
上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
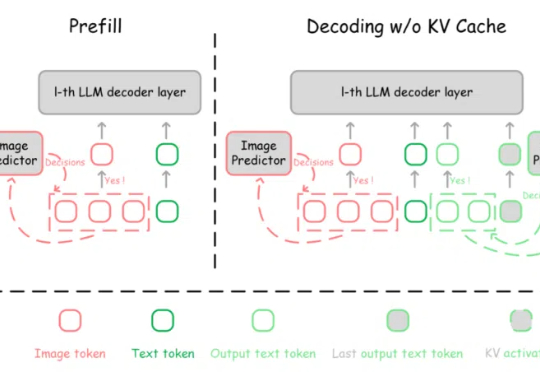
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。

ICLR 2025杰出论文揭晓!
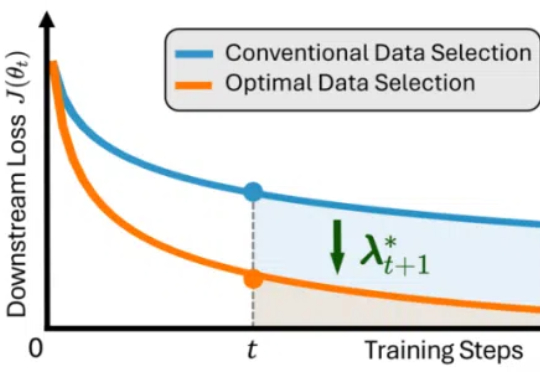
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

算力砍半,视觉生成任务依然SOTA!

一年一度ICLR 2025杰出论文开奖!普林斯顿、UBC、中科大NUS等团队的论文拔得头筹,还有Meta团队「分割一切」SAM 2摘得荣誉提名。
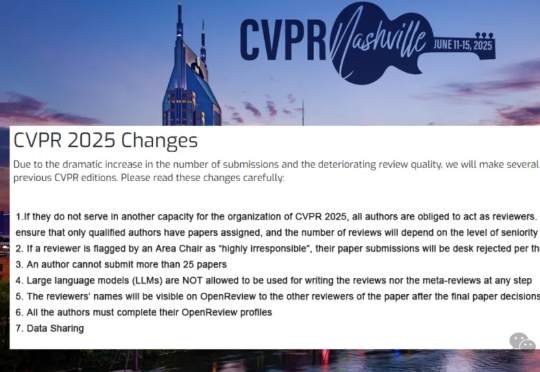
顶会论文评审,AI立大功!ICLR 2025首次大规模引入AI参与审稿,最终有12222条建议被审稿人采纳,89%情况下提升了评审质量。详细30页报告,揭秘AI在顶会审稿的惊人潜力。
ICLR 2025时间检验奖重磅揭晓!Yoshua Bengio与华人科学家Jimmy Ba分别领衔的两篇十年前论文摘得冠军与亚军。一个是Adam优化器,另一个注意力机制,彻底重塑深度学习的未来。