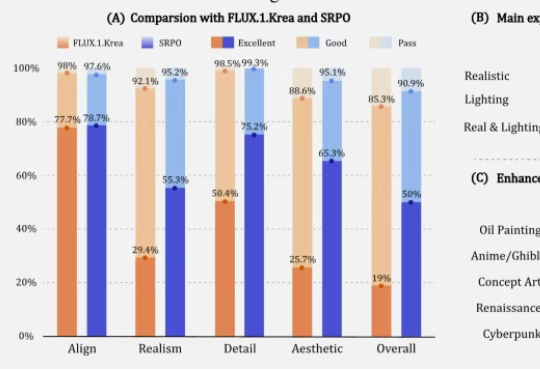
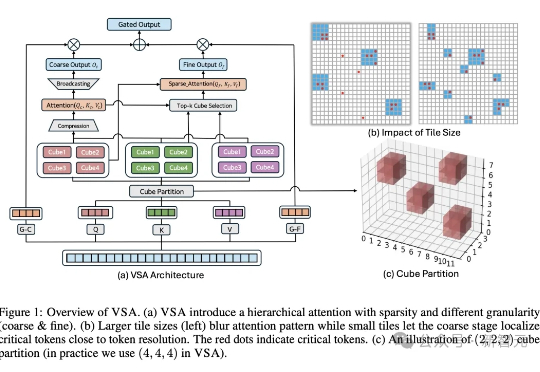
两周复刻DeepSeek-OCR!两人小团队还原低token高压缩核心,换完解码器更实用
两周复刻DeepSeek-OCR!两人小团队还原低token高压缩核心,换完解码器更实用两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。
来自主题: AI资讯
9261 点击 2025-11-07 15:22