
谷歌DeepMindCEO:谷歌最接近AGI的模型是Veo,不是Gemini 3!没有引入广告的计划,曝AI眼镜最新进展:杀手级应用将出现
谷歌DeepMindCEO:谷歌最接近AGI的模型是Veo,不是Gemini 3!没有引入广告的计划,曝AI眼镜最新进展:杀手级应用将出现在达沃斯论坛之后,谷歌Deepmind CEO Demis Hassabis又连续上了两个播客,放出了不少谷歌的新动向!
来自主题: AI资讯
8316 点击 2026-01-27 16:16
 搜索
搜索
在达沃斯论坛之后,谷歌Deepmind CEO Demis Hassabis又连续上了两个播客,放出了不少谷歌的新动向!
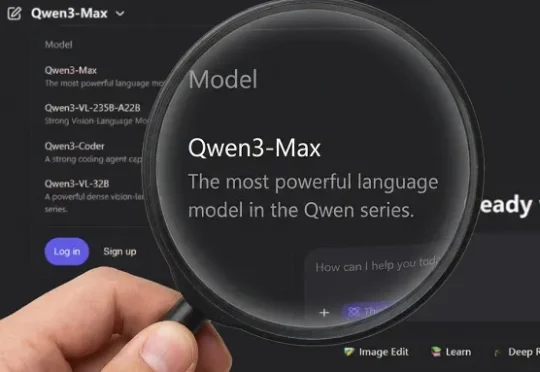
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。
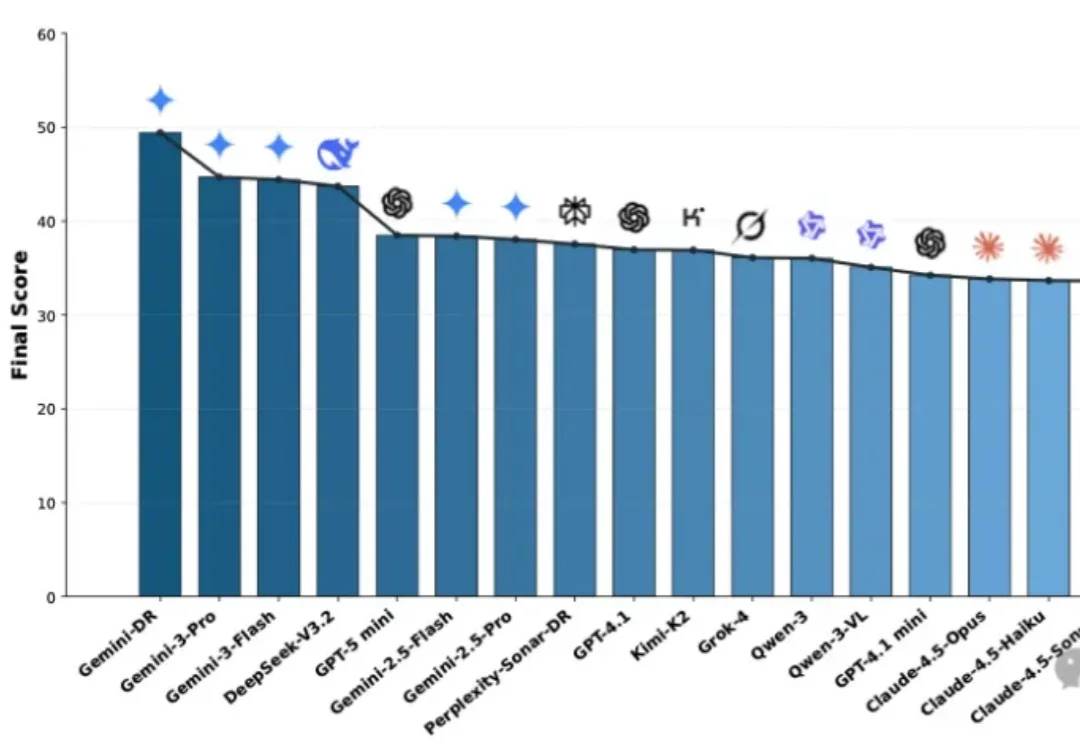
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。
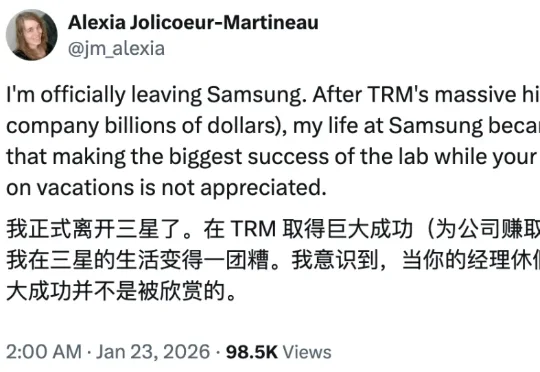
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。

目前已经出现了一些早期迹象,通用LLM助手领域的市场格局,正朝着“赢家通吃”,至少是“赢家通吃大部分市场”的趋势发展。在ChatGPT、Gemini、Claude 3和Cursor这几款产品中,仅有9%的用户会为一款以上的产品付费。
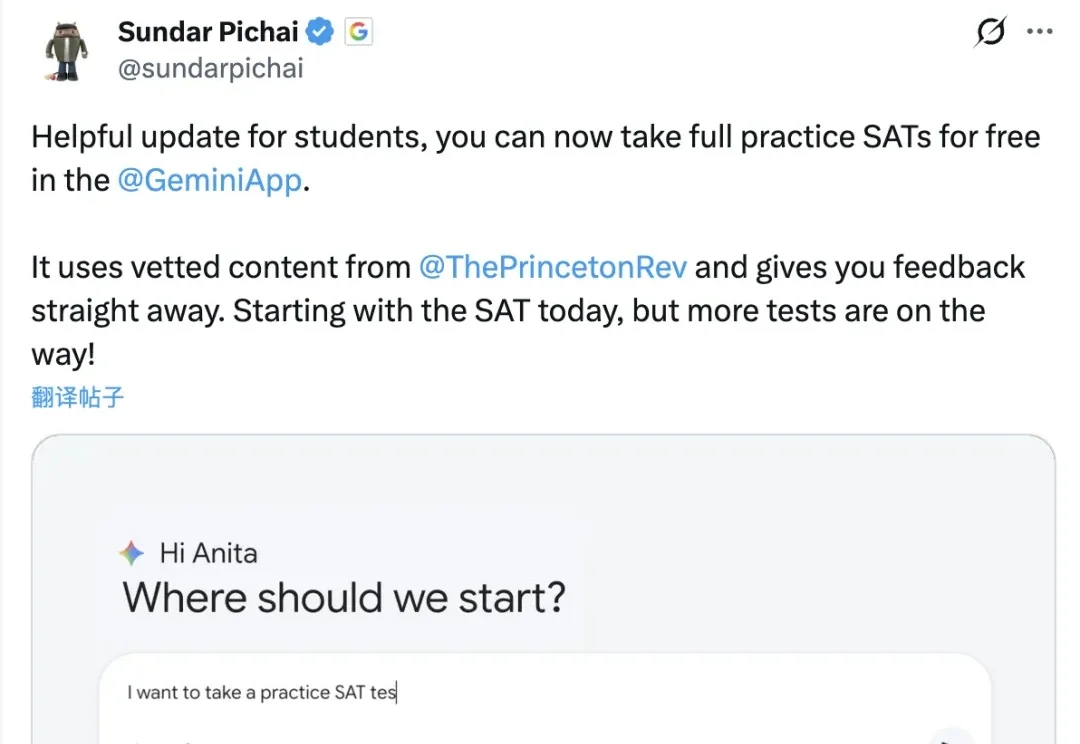
谷歌来给考生送福利了!
最近群里好多朋友在问我,Gemini 生成的图片水印能不能去掉。

谷歌对其Gemini AI 模型的改进正在提升公司的核心收入。
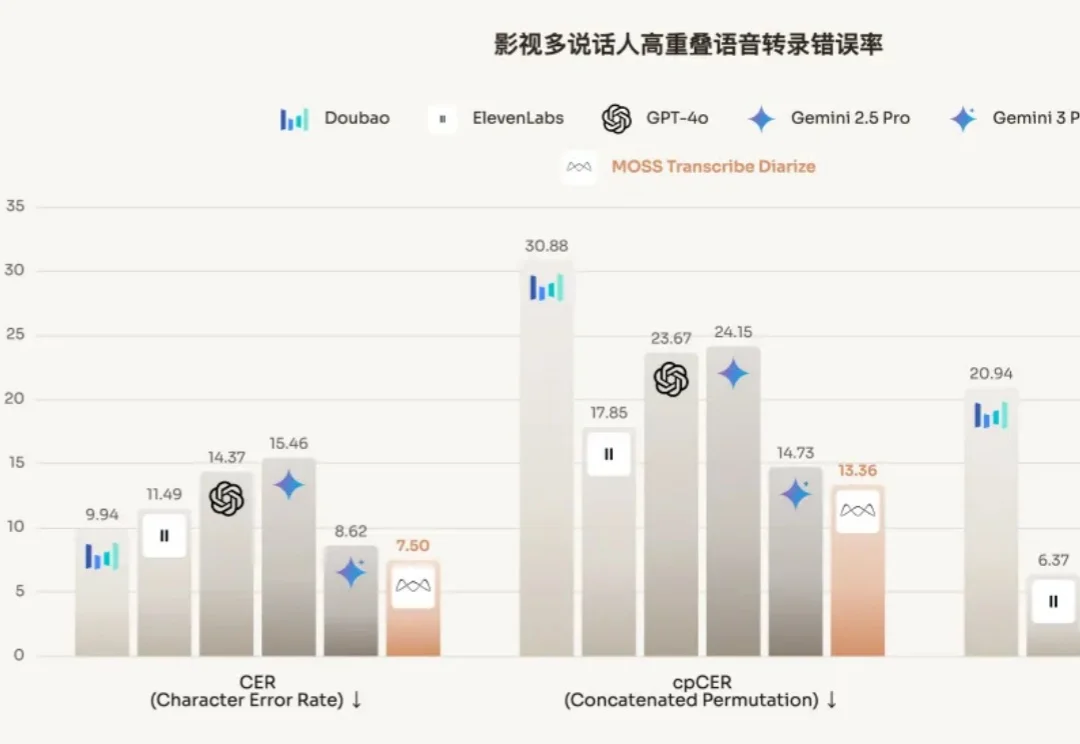
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。

究竟是什么样的更新,才能让谷歌CEO皮查伊称之为“众望所归”(Answering a top request from our users)?